DeepLabV3Plus Pytorch
1.0.0
DeeplAbv3 pré -tenhado, DEEPLABV3+ para Pascal Voc & Cityscapes.
| DEEPLABV3 | DEEPLABV3+ |
|---|---|
| DEEPLABV3_RESNET50 | DEEPLABV3PLUS_RESNET50 |
| DEEPLABV3_RESNET101 | DEEPLABV3PLUS_RESNET101 |
| DEEPLABV3_MOBILENET | DEEPLABV3PLUS_MOBILENET |
| DEEPLABV3_HRNETV2_48 | DEEPLABV3PLUS_HRNETV2_48 |
| DEEPLABV3_HRNETV2_32 | DEEPLABV3PLUS_HRNETV2_32 |
| DEEPLABV3_XCECPEIRA | DEEPLABV3plus_xception |
Consulte o Network/Modeling.Py para todas as entradas do modelo.
Faça o download de modelos pré -ridados: Dropbox, Tencent Weiyun
Nota: O backbone HRNET foi contribuído por @TimotyLimyl. Um backbone pré-treinado está disponível no Google Drive.
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL ImageNOTA : Todos os modelos pré-treinados neste repositório foram treinados sem convolução separável atrevida.
Convolução separável ativa é apoiada neste repositório. Fornecemos uma network.convert_to_separable_conv de ferramentas simples.convert_to_separable_conv para converter nn.Conv2d para AtrousSeparableConvolution . Por favor, execute main.py com '--separable_conv' se for necessário . Consulte 'Main.py' e 'Network/_deeplab.py' para obter mais detalhes.
Imagem única:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsPasta de imagem:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsConsulte este comprometimento (Xception) para obter mais detalhes sobre como adicionar novos backbones.
Você pode treinar modelos DEEPLAB em seus próprios conjuntos de dados. O seu torch.utils.data.Dataset deve fornecer um método de decodificação que transforma suas previsões em imagens coloridas, assim como o conjunto de dados VOC:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ] Treinamento: 513x513 colheita aleatória
Validação: 513x513 colheita central
| Modelo | Tamanho do lote | Flops | Trem/Val OS | miou | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| DEEPLABV3-MOBILENET | 16 | 6.0g | 16/16 | 0,701 | Download | Download |
| DEEPLABV3-RESNET50 | 16 | 51.4G | 16/16 | 0,769 | Download | Download |
| DEEPLABV3-RESNET101 | 16 | 72.1g | 16/16 | 0,773 | Download | Download |
| DEEPLABV3PLUS-MOBILENET | 16 | 17.0g | 16/16 | 0,711 | Download | Download |
| DEEPLABV3PLUS-RESNET50 | 16 | 62.7g | 16/16 | 0,772 | Download | Download |
| DEEPLABV3PLUS-RESNET101 | 16 | 83.4g | 16/16 | 0,783 | Download | Download |
Treinamento: 768x768 Cultura aleatória
Validação: 1024x2048
| Modelo | Tamanho do lote | Flops | Trem/Val OS | miou | Dropbox | Tencent Weiyun |
|---|---|---|---|---|---|---|
| DEEPLABV3PLUS-MOBILENET | 16 | 135g | 16/16 | 0,721 | Download | Download |
| DEEPLABV3PLUS-RESNET101 | 16 | N / D | 16/16 | 0,762 | Download | N / D |












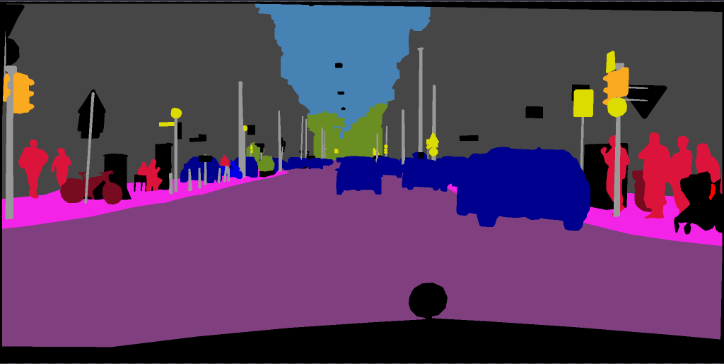

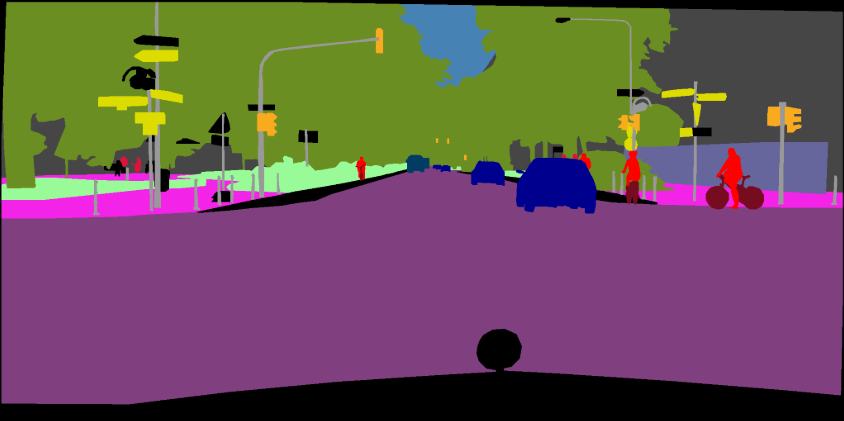

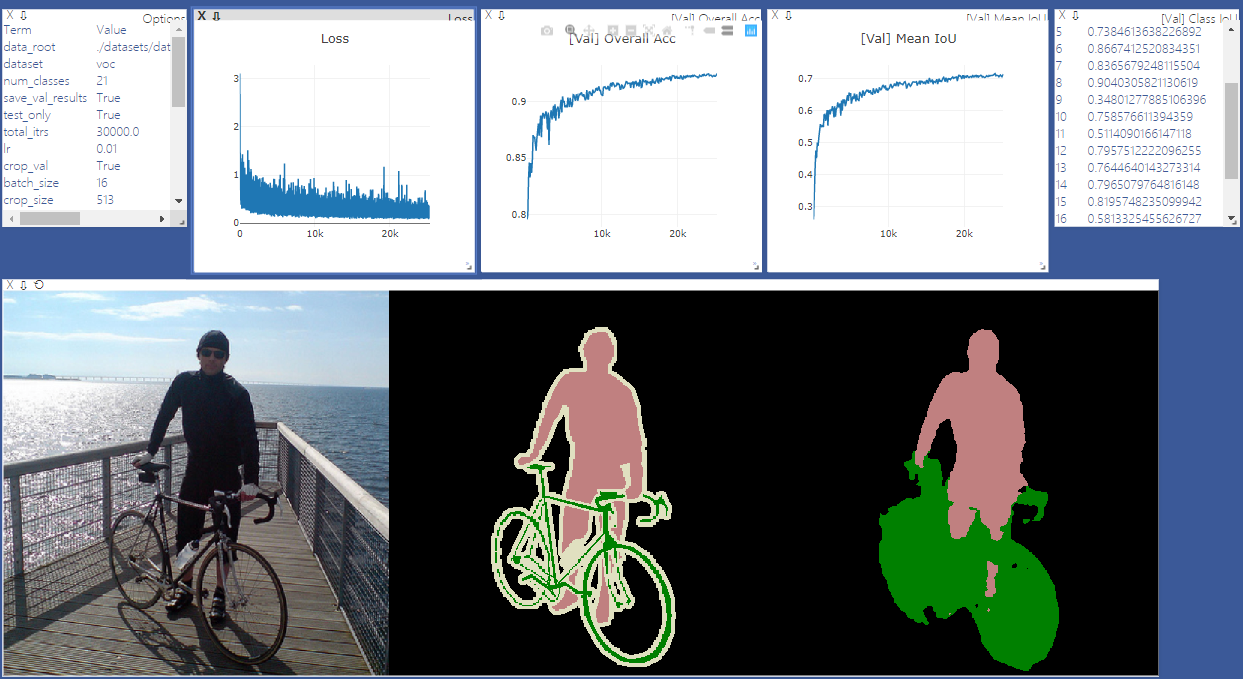
pip install -r requirements.txtVocê pode executar o Train.py com a opção "-download" para baixar e extrair o conjunto de dados Pascal VOC. O caminho de defesa é './datasets/data':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Veja o capítulo 4 de [2]
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt inclui os nomes de arquivos das imagens de 10582 trenaug (imagens Val são excluídas). Por favor, faça o download de seus rótulos da Dropbox ou Tencent Weiyun. Esses rótulos vêm do repositório de Drsleep.
Extraia os rótulos de trem (segmentationclassaug) para o diretório VOC2012.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Inicie o Sever Visdom para a visualização. Remova '--enable_vis' se a visualização não for necessária.
# Run visdom server on port 28333
visdom -port 28333Run Main.Py com "-ano de 2012_aug" para treinar seu modelo no Pascal VOC2012 de agosto. Você também pode paralelo ao seu treinamento em 4 GPUs com '--gpu_id 0,1,2,3'
NOTA: Não há SyncBN neste repositório, portanto, o treinamento com GPUs de múltiplas GPUs e tamanho pequeno em lote pode degradar o desempenho. Veja o codificação de Pytorch para obter mais detalhes sobre o SyncBN
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16Execute main.py com '--continue_training' para restaurar o State_dict of Optimizer e Scheduler do seu_ckpt.
python main.py ... --ckpt YOUR_CKPT --continue_trainingOs resultados serão salvos em ./results.
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] Repensando a convolução atrossa para segmentação de imagem semântica
[2] Encoder-decidido com convolução separável atrossa para segmentação de imagem semântica


