DeepLabV3Plus Pytorch
1.0.0
DeepLabv3 previamente provocado, DeepLabv3+ para Pascal VOC y paisajes urbanos.
| DeepLabv3 | DeepLabv3+ |
|---|---|
| DeepLabv3_Resnet50 | DeepLabv3Plus_Resnet50 |
| DeepLabv3_Resnet101 | DeepLabv3Plus_Resnet101 |
| DeepLabv3_Mobilenet | DeepLabv3Plus_Mobilenet |
| DeepLabv3_hrnetv2_48 | DeepLabv3Plus_HRNETV2_48 |
| DeepLabv3_hrnetv2_32 | DeepLabv3Plus_HRNETV2_32 |
| DeepLabv3_xception | DeepLabv3plus_xception |
Consulte Network/Modeling.py para todas las entradas del modelo.
Descargar modelos previos a la aparición: Dropbox, Tencent Weiyun
Nota: La columna vertebral de HRNet fue aportada por @timothylimyl. Una columna vertebral previamente entrenada está disponible en Google Drive.
model = network . modeling . __dict__ [ MODEL_NAME ]( num_classes = NUM_CLASSES , output_stride = OUTPUT_SRTIDE )
model . load_state_dict ( torch . load ( PATH_TO_PTH )[ 'model_state' ] ) outputs = model ( images )
preds = outputs . max ( 1 )[ 1 ]. detach (). cpu (). numpy ()
colorized_preds = val_dst . decode_target ( preds ). astype ( 'uint8' ) # To RGB images, (N, H, W, 3), ranged 0~255, numpy array
# Do whatever you like here with the colorized segmentation maps
colorized_preds = Image . fromarray ( colorized_preds [ 0 ]) # to PIL ImageNota : Todos los modelos previamente capacitados en este repositorio fueron entrenados sin una convolución separable de atracción.
La convolución separable atrusa se respalda en este repositorio. Proporcionamos una herramienta simple network.convert_to_separable_conv para convertir nn.Conv2d a AtrousSeparableConvolution . Ejecute Main.py con '--separable_conv' si es necesario . Consulte 'Main.py' y 'Network/_deeplab.py' para obtener más detalles.
Imagen individual:
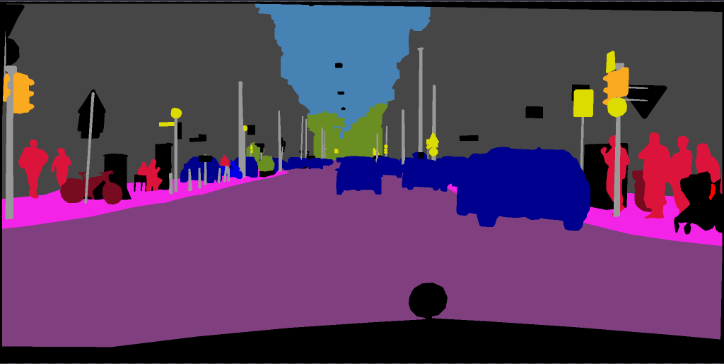
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen/bremen_000000_000019_leftImg8bit.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsCarpeta de imagen:
python predict.py --input datasets/data/cityscapes/leftImg8bit/train/bremen --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_resultsConsulte este Commit (Xception) para obtener más detalles sobre cómo agregar nuevas columnas.
Puede entrenar modelos DeepLab en sus propios conjuntos de datos. Su torch.utils.data.Dataset debe proporcionar un método de decodificación que transforme sus predicciones en imágenes colorizadas, al igual que el conjunto de datos VOC:
class MyDataset ( data . Dataset ):
...
@ classmethod
def decode_target ( cls , mask ):
"""decode semantic mask to RGB image"""
return cls . cmap [ mask ] Entrenamiento: 513x513 cultivo aleatorio
Validación: 513x513 Crop de cosecha
| Modelo | Tamaño por lotes | Chocolas | Train/Val OS | miou | Dropbox | Tencent weiyun |
|---|---|---|---|---|---|---|
| DeepLabv3-Mobilenet | 16 | 6.0g | 16/16 | 0.701 | Descargar | Descargar |
| DeepLabv3-Resnet50 | 16 | 51.4g | 16/16 | 0.769 | Descargar | Descargar |
| DeepLabv3-Resnet101 | 16 | 72.1g | 16/16 | 0.773 | Descargar | Descargar |
| DeepLabv3plus-Mobilenet | 16 | 17.0g | 16/16 | 0.711 | Descargar | Descargar |
| DeepLabv3Plus-Resnet50 | 16 | 62.7g | 16/16 | 0.772 | Descargar | Descargar |
| DeepLabv3Plus-Resnet101 | 16 | 83.4g | 16/16 | 0.783 | Descargar | Descargar |
Entrenamiento: 768x768 Corte aleatorio
Validación: 1024x2048
| Modelo | Tamaño por lotes | Chocolas | Train/Val OS | miou | Dropbox | Tencent weiyun |
|---|---|---|---|---|---|---|
| DeepLabv3plus-Mobilenet | 16 | 135G | 16/16 | 0.721 | Descargar | Descargar |
| DeepLabv3Plus-Resnet101 | 16 | N / A | 16/16 | 0.762 | Descargar | N / A |














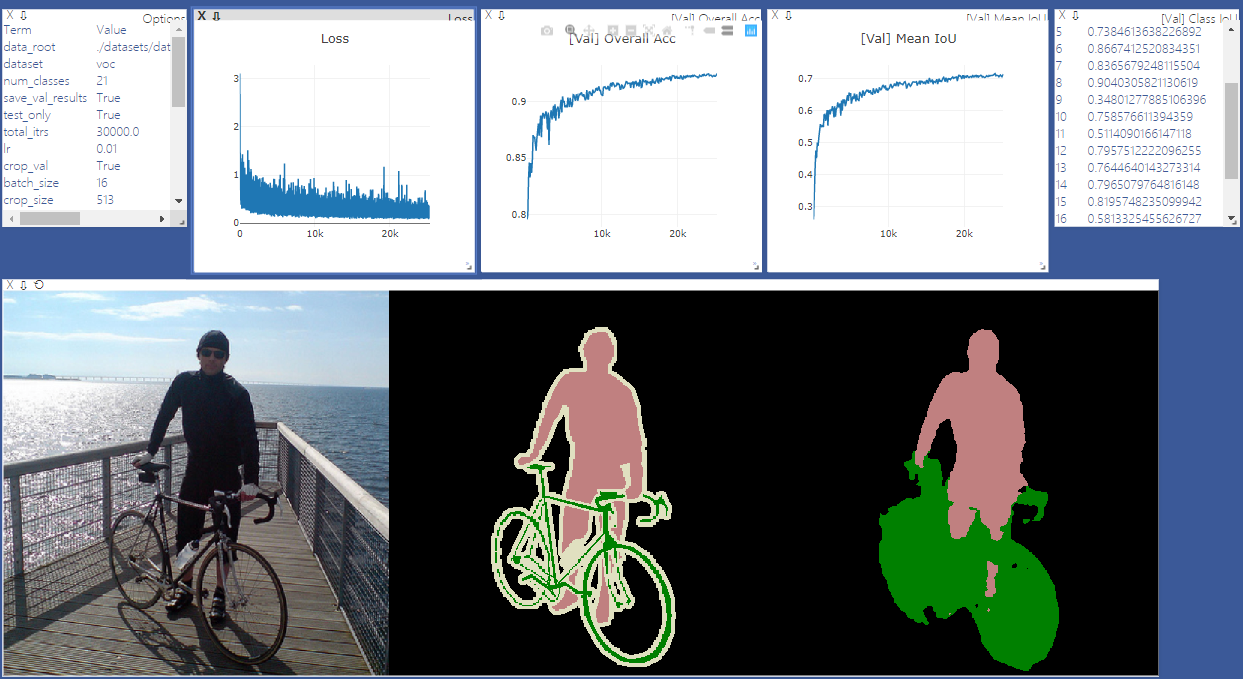
pip install -r requirements.txtPuede ejecutar Train.py con la opción "-Download" para descargar y extraer el conjunto de datos PASCAL VOC. La ruta defaut es './datasets/data':
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Ver Capítulo 4 de [2]
The original dataset contains 1464 (train), 1449 (val), and 1456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by [76], resulting in 10582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
./datasets/data/train_aug.txt incluye los nombres de archivo de 10582 imágenes de capas (las imágenes VAL están excluidas). Por favor, descargue sus etiquetas de Dropbox o Tencent Weiyun. Esas etiquetas provienen del repositorio de Drsleep.
Extraer etiquetas de Trazaug (SegmentationClassaug) al directorio VOC2012.
/datasets
/data
/VOCdevkit
/VOC2012
/SegmentationClass
/SegmentationClassAug # <= the trainaug labels
/JPEGImages
...
...
/VOCtrainval_11-May-2012.tar
...
Comience a Visdom severa para la visualización. Eliminar '--enable_vis' si no se necesita visualización.
# Run visdom server on port 28333
visdom -port 28333Ejecute Main.py con "-año 2012_aug" para entrenar a su modelo en Pascal VOC2012 Ago. También puede ser paralelo a su entrenamiento en 4 GPU con '--GPU_ID 0,1,2,3'
Nota: No hay sincronización en este repositorio, por lo que el entrenamiento con GPU multple y el tamaño de lotes pequeños puede degradar el rendimiento. Consulte Pytorch-coding para obtener más detalles sobre SyncBN
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16Ejecute Main.py con '--Continue_Training' para restaurar el state_dict of Optimizer y Scheduler desde su_ckpt.
python main.py ... --ckpt YOUR_CKPT --continue_trainingLos resultados se guardarán en ./results.
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 28333 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results /datasets
/data
/cityscapes
/gtFine
/leftImg8bit
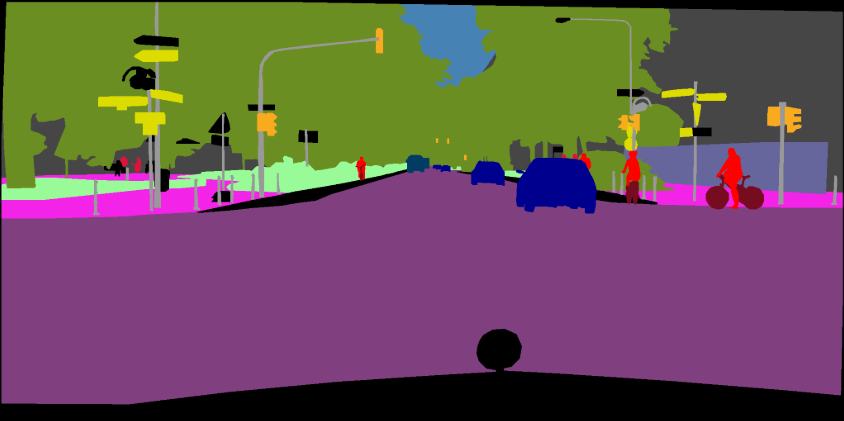
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 28333 --gpu_id 0 --lr 0.1 --crop_size 768 --batch_size 16 --output_stride 16 --data_root ./datasets/data/cityscapes [1] Repensar la convolución aturiosa para la segmentación de imágenes semánticas
[2] Decodificador del codificador con convolución separable atrous para la segmentación de imágenes semánticas


