torch audiomentations
v0.11.1

Pytorch中的音頻數據增強。受聽眾的啟發。
nn.Module ,因此它們可以作為Pytorch神經網絡模型的一部分集成per_batch , per_example和per_channelpip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters和unfreeze_parameters現在使用Undreeze_parameters。PitchShift不支持小小的音高變化,尤其是對於低樣本率(#151)。解決方法:如果您需要適用於低樣本速率的較小的音高偏移,請直接在聽眾或火炬旋轉中使用PitchShift,而無需計算有效的換擋目標的功能。貢獻者歡迎!加入小行星的懈怠,開始與我們討論torch-audiomentations 。
我們不希望數據擴展成為模型訓練速度的瓶頸。這是運行1D卷積所需的時間的比較:
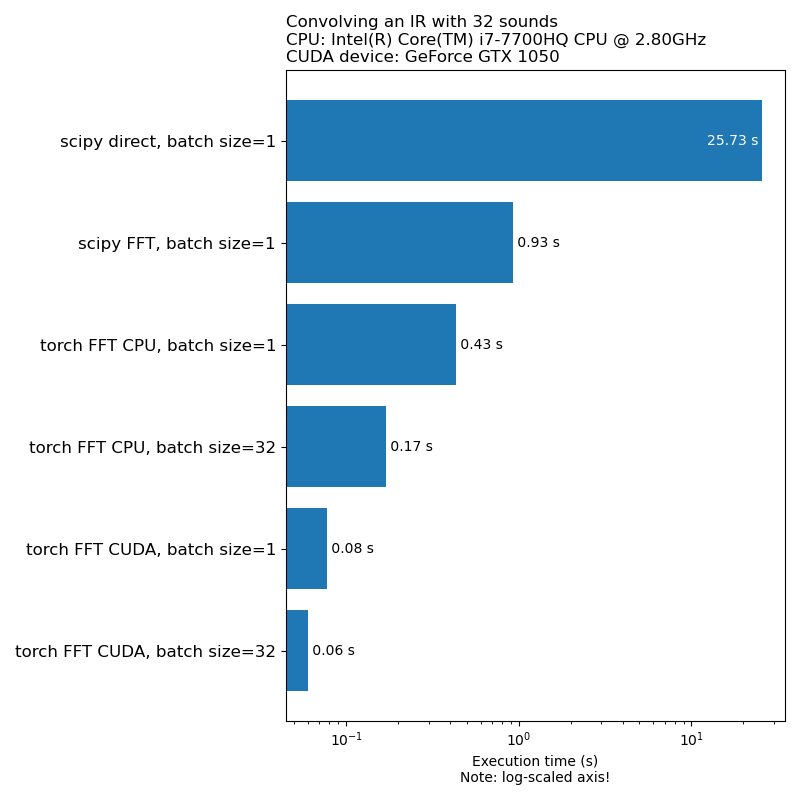
注意:與CPU相比,並非所有轉換都具有令人印象深刻的加速。通常,在GPU上運行音頻數據並不總是最好的選擇。有關更多信息,請參閱本文:https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
火炬原理處於早期開發階段,因此API可能會發生變化。
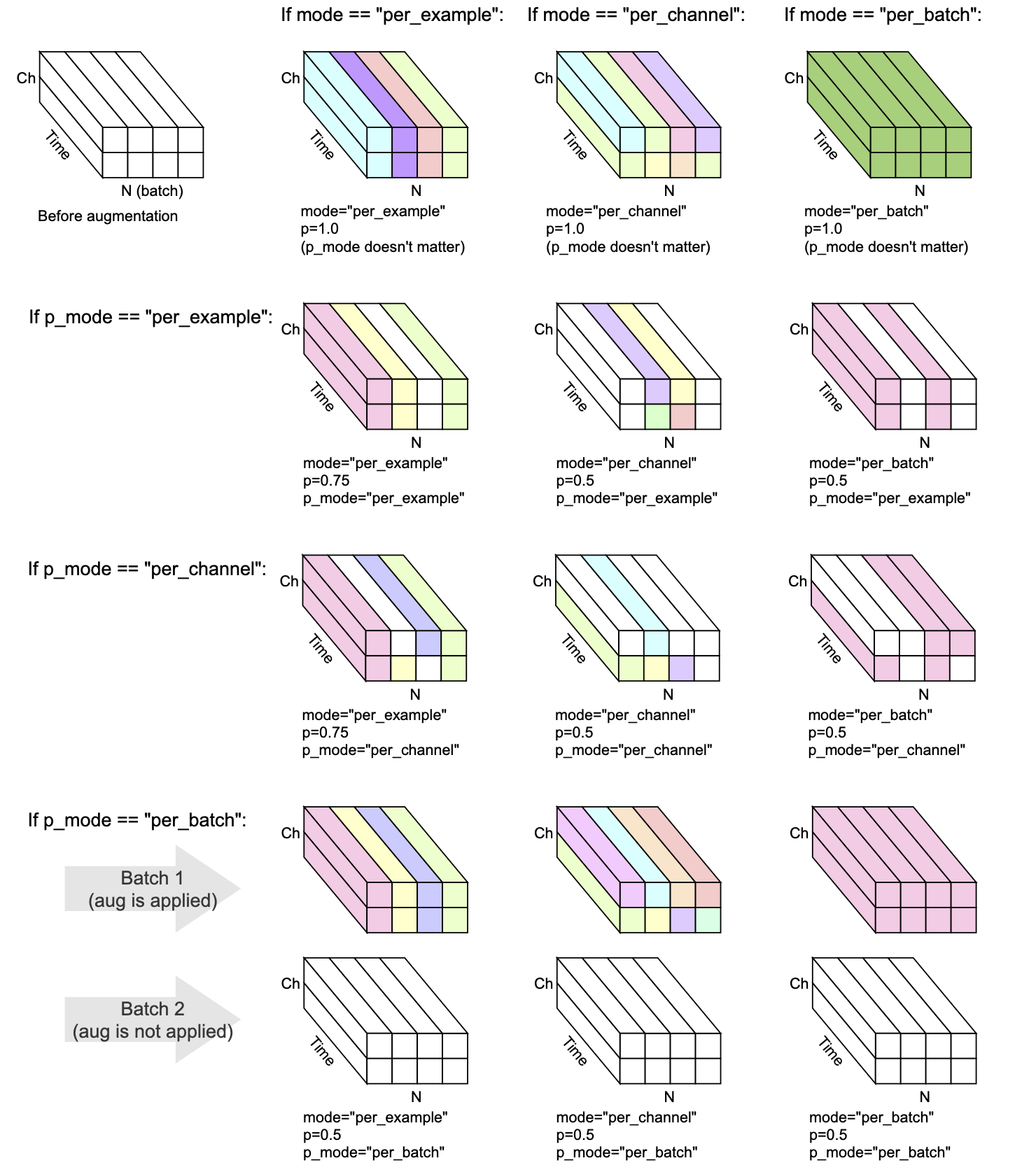
每個變換都有mode , p和p_mode - 決定如何執行增強的參數。
mode決定瞭如何將增強的隨機化分組和應用。p決定應用增強的概率。p_mode決定如何應用增強的ON/OFF。該可視化顯示了mode和p_mode的不同組合將如何執行增強。
在v0.5.0中添加
在輸入音頻中添加背景噪聲。
在v0.7.0中添加
在輸入音頻中添加彩色噪聲。
在v0.5.0中添加
通過衝動響應來卷積給定的音頻。
在v0.9.0中添加
將帶通濾波應用於輸入音頻。
在v0.10.0中添加
在輸入音頻上應用帶擋局過濾。也稱為Notch過濾器。
在v0.1.0中添加
將音頻乘以隨機振幅因子,以減少或增加體積。該技術可以幫助模型成為輸入音頻的整體增益的不變性。
警告:此轉換可以返回[-1,1]範圍之外的樣品,這可能會導致剪輯或包裹失真,具體取決於您在以後的音頻中使用的內容。另請參見https://en.wikipedia.org/wiki/clipping_(audio)#digital_clipping
在v0.8.0中添加
將高通濾波應用於輸入音頻。
在v0.11.0中添加
此轉換返回輸入不變。在應禁用數據增加的情況下,它可用於簡化代碼。
在v0.8.0中添加
將低通濾波應用於輸入音頻。
在v0.2.0中添加
應用恆定的增益,以便批處理中每個音頻片段中存在的最高信號水平變為0 dbfs,即,如果所有樣本必須在-1和1之間,則允許的最大水平。
此轉換具有替代模式(apply_to =“ halle_too_loud_sounds”),其中僅適用於在[-1,1]範圍之外具有極高值的音頻片段。這對於避免在音頻中的數字剪輯時很有用,而這些音頻太大了,而其他音頻則未受到影響。
在v0.9.0中添加
換擋聲音向上或向下聽起來,而不會改變節奏。
在v0.1.0中添加
翻轉音頻樣品顛倒,顛倒了它們的極性。換句話說,將波形乘以-1,因此負值變為正,反之亦然。與原始作品隔離時,結果聽起來會相同。但是,當與其他音頻源混合時,結果可能會有所不同。此波形反演技術有時用於取消音頻或獲得兩個波形之間的差異。但是,在音頻數據增強的背景下,當訓練階段感知機器學習模型時,此轉換可能很有用。
在v0.5.0中添加
在有或沒有滾動的情況下向前或向後移動音頻
在v0.6.0中添加
給定多通道音頻輸入(例如立體聲),將頻道洗牌,例如,左可以變為右,反之亦然。這種轉換可以幫助打擊輸入多通道波形的機器學習模型中的位置偏差。
如果輸入音頻是單聲道,則此轉換除了發出警告外什麼都沒有。
在v0.10.0中添加
反向(反向)沿時間軸的音頻類似於視覺域中圖像的隨機翻轉。這在音頻分類的背景下可能是相關的。它成功地應用於紙聲audioclip:將剪輯擴展到圖像,文本和音頻
Mix , Padding , RandomCrop和SpliceOut LowPassFilter和HighPassFilter中增加支持恆定截止頻率的支持AddColoredNoise中添加對MIN_F_DECAY == MAX_F_DECAY的支持Shift中的不准確類型提示set_backend ,以避免在Torchaudio中UserWarning IdentityObjectDict輸出類型作為torch.Tensor的替代方案。該替代方案現在是選擇加入的(用於向後兼容),但請注意,舊輸出類型( torch.Tensor )被棄用,對其的支持將在以後的版本中刪除。AddBackgroundNoise ApplyImpulseResponsetorch-pitch-shift以確保在PitchShift中支持Torchaudio 0.11BandPassFilter在GPU上不起作用的錯誤AddBackgroundNoise對Min Snr == Max SNR的支持AddBackgroundNoise中的不兼容長度OneOf或SomeOf ,以應用一組或多種轉換集BandStopFilter和TimeInversionir_paths在transform_parameters中放置在ApplyImpulseResponse中,以便檢查使用了哪些脈衝響應。這也使freeze_parameters()預期行為。BandPassFilter中預期的兩倍。默認值已相應更新。如果您以前是指定min_bandwidth_fraction和/或max_bandwidth_fraction ,則現在需要將這些數字加倍才能獲得與以前相同的行為。 compensate_for_propagation_delay在ApplyImpulseResponse中BandPassFilterPitchShiftHighPassFilter和LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise在CUDA上不起作用ApplyImpulseResponse性能。 AddBackgroundNoise和ApplyImpulseResponseShiftsample_rate可選。允許在__init__中指定sample_rate ,而不是forward 。這意味著現在可以Compose Torchaudio變換。nn.Module子類的parameters方法Compose用於應用多個變換的實施from_dict和from_yaml實施實用程序功能,以從DICE,JSON或YAML加載數據增強配置per_batch和per_channel替代模式的支持PeakNormalizationconvolveGain和PolarityInversion初步釋放可以使用Conda創建一個啟用GPU的開發環境:
conda env create pytest
諾蒙諾(Nomono)友好地支持火炬審核的發展。
感謝所有有助於改善火炬原理的貢獻者。


