torch audiomentations
v0.11.1

Audio Aumento de datos en Pytorch. Inspirado en audiomentaciones.
nn.Module , por lo que pueden integrarse como parte de un modelo de red neuronal de Pytorchper_batch , per_example y per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters y unfreeze_parameters por ahora si los datos de destino son audio con la misma forma que la entrada.PitchShift no admite pequeños cambios de tono, especialmente para bajas velocidades de muestreo (#151). Solución alternativa: si necesita pequeños turnos de tono aplicados a bajas velocidades de muestra, use PitchShift en audiomentaciones o Torch-Pitch-Shift directamente sin la función para calcular objetivos eficientes de cambio de cabeceo. ¡Los contribuyentes bienvenidos! Únase a la holgura del asteroide para comenzar a discutir sobre torch-audiomentations con nosotros.
No queremos que el aumento de datos sea un cuello de botella en la velocidad de entrenamiento modelo. Aquí hay una comparación del tiempo que lleva ejecutar 1D convolución:
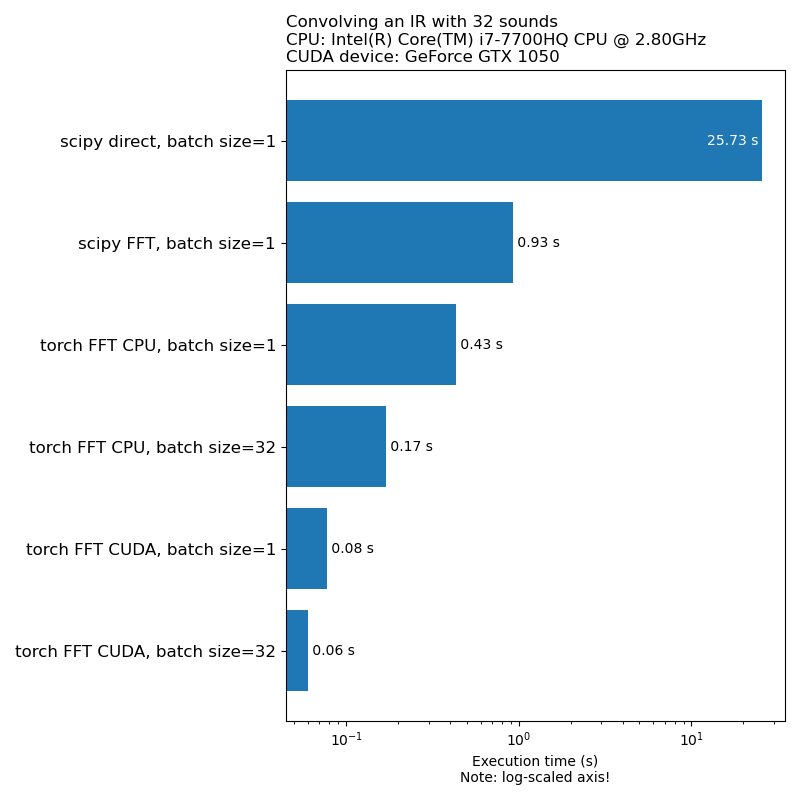
Nota: No todas las transformaciones tienen una aceleración tan impresionante en comparación con la CPU. En general, ejecutar el aumento de datos de audio en GPU no siempre es la mejor opción. Para obtener más información, consulte este artículo: https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
Las audiomenciones de antorcha se encuentran en una etapa de desarrollo temprano, por lo que las API están sujetas a cambios.
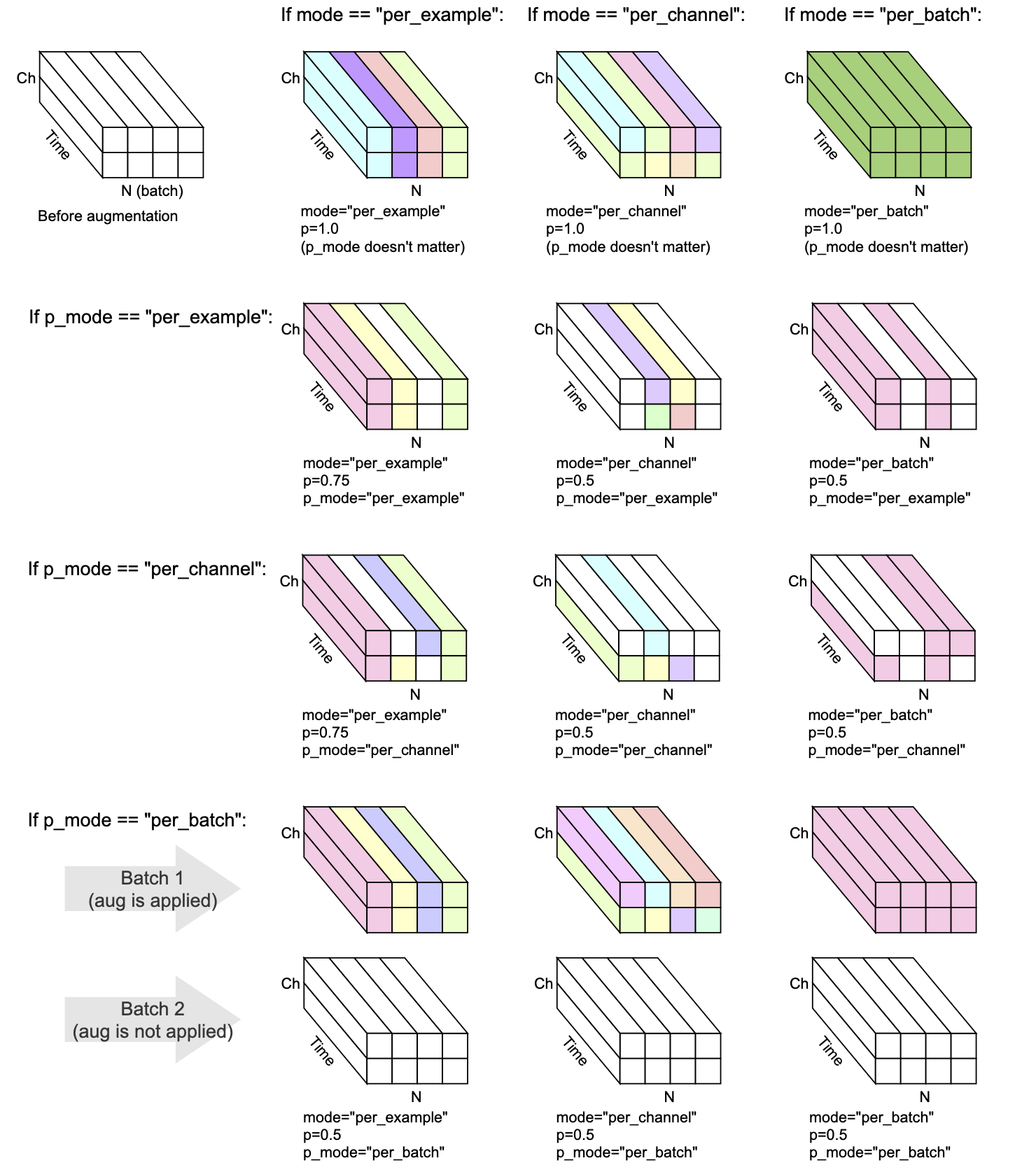
Cada transformación tiene mode , p y p_mode : los parámetros que deciden cómo se realiza el aumento.
mode decide cómo se agrupa y aplica la aleatorización del aumento.p decide la probabilidad de encendido/apagado de aplicar el aumento.p_mode decide cómo se aplica el encendido/apagado del aumento. Esta visualización muestra cómo diferentes combinaciones de mode y p_mode realizarían un aumento.
Agregado en v0.5.0
Agregue el ruido de fondo al audio de entrada.
Agregado en v0.7.0
Agregue el ruido de color al audio de entrada.
Agregado en v0.5.0
Convolucionar el audio dado con respuestas de impulso.
Agregado en V0.9.0
Aplique el filtrado de paso de banda al audio de entrada.
Agregado en v0.10.0
Aplique filtrado de parada de banda al audio de entrada. También conocido como filtro de muescas.
Agregado en v0.1.0
Multiplique el audio por un factor de amplitud aleatorio para reducir o aumentar el volumen. Esta técnica puede ayudar a que un modelo se vuelva algo invariante para la ganancia general del audio de entrada.
ADVERTENCIA: Esta transformación puede devolver muestras fuera del rango [-1, 1], lo que puede conducir a una distorsión de recorte o envoltura, dependiendo de lo que haga con el audio en una etapa posterior. Ver también https://en.wikipedia.org/wiki/clipping_(audio)#digital_clipping
Agregado en v0.8.0
Aplique un filtrado de paso alto al audio de entrada.
Agregado en V0.11.0
Esta transformación devuelve la entrada sin cambios. Se puede usar para simplificar el código en los casos en que el aumento de datos debe deshabilitarse.
Agregado en v0.8.0
Aplique un filtrado de paso bajo al audio de entrada.
Agregado en v0.2.0
Aplique una cantidad constante de ganancia, de modo que el nivel de señal más alto presente en cada fragmento de audio en el lote se convierta en 0 dBF, es decir, el nivel más fuerte permitido si todas las muestras deben estar entre -1 y 1.
Esta transformación tiene un modo alternativo (aplicar_to = "solo_too_loud_sounds") donde solo se aplica a los fragmentos de audio que tienen valores extremos fuera del rango [-1, 1]. Esto es útil para evitar el recorte digital en audio que es demasiado ruidoso, al tiempo que deja otro audio intacto.
Agregado en V0.9.0
Pitch-Shift suena hacia arriba o hacia abajo sin cambiar el tempo.
Agregado en v0.1.0
Voltee las muestras de audio al revés, invirtiendo su polaridad. En otras palabras, multiplique la forma de onda por -1, por lo que los valores negativos se vuelven positivos, y viceversa. El resultado sonará igual en comparación con el original cuando se reproduce de forma aislada. Sin embargo, cuando se mezcla con otras fuentes de audio, el resultado puede ser diferente. Esta técnica de inversión de forma de onda a veces se usa para la cancelación de audio u para obtener la diferencia entre dos formas de onda. Sin embargo, en el contexto del aumento de datos de audio, esta transformación puede ser útil al capacitar a los modelos de aprendizaje automático con consumo de fase.
Agregado en v0.5.0
Cambiar el audio hacia adelante o hacia atrás, con o sin flujo
Agregado en v0.6.0
Dada la entrada de audio multicanal (por ejemplo, estéreo), baraja los canales, por ejemplo, para que la izquierda pueda volverse a la derecha y viceversa. Esta transformación puede ayudar a combatir el sesgo posicional en modelos de aprendizaje automático que ingresan formas de onda multicanal.
Si el audio de entrada es mono, esta transformación no hace nada excepto emitir una advertencia.
Agregado en v0.10.0
Reverse (invertir) el audio a lo largo del eje de tiempo similar al flip aleatorio de una imagen en el dominio visual. Esto puede ser relevante en el contexto de la clasificación de audio. Se aplicó con éxito en el documento AudioClip: extendiendo el clip a imagen, texto y audio
Mix , Padding , RandomCrop y SpliceOut LowPassFilter y HighPassFilterAddColoredNoiseShiftset_backend para evitar UserWarning de Torchaudio IdentityObjectDict como alternativa a torch.Tensor . Esta alternativa es la opción por ahora (por compatibilidad con hacia atrás), pero tenga en cuenta que el tipo de salida anterior ( torch.Tensor ) está en desuso y el soporte se eliminará en una versión futura.AddBackgroundNoise y ApplyImpulseResponsetorch-pitch-shift para garantizar el soporte de Torchaudio 0.11 en PitchShiftBandPassFilter no funcionó en GPU AddBackgroundNoiseAddBackgroundNoise OneOf y SomeOf para aplicar uno o más de un conjunto dado de transformacionesBandStopFilter y TimeInversionir_paths en transform_Parameters en ApplyImpulseResponse por lo que es posible inspeccionar qué respuestas de impulso se usaron. Esto también le da freeze_parameters() el comportamiento esperado.BandPassFilter . Los valores predeterminados se han actualizado en consecuencia. Si previamente estaba especificando min_bandwidth_fraction y/o max_bandwidth_fraction , ahora necesita duplicar esos números para obtener el mismo comportamiento que antes. compensate_for_propagation_delay en ApplyImpulseResponseBandPassFilterPitchShiftHighPassFilter y LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise no funcionó en CUDAApplyImpulseResponse . AddBackgroundNoise y ApplyImpulseResponseShiftsample_rate opcional. Permitir especificar sample_rate en __init__ en lugar de forward . Esto significa que las transformaciones de Torchaudio se pueden usar en Compose ahora.parameters de la subclase nn.ModuleCompose para aplicar múltiples transformacionesfrom_dict y from_yaml para cargar configuraciones de aumento de datos de DICT, JSON o YAMLper_batch y per_channelPeakNormalizationconvolve en la APIGain e PolarityInversionSe puede crear un entorno de desarrollo habilitado para GPU para audiomenciones de antorcha con conda:
conda env create pytest
El desarrollo de las audiomenciones de antorcha está respaldado amablemente por Nomono.
Gracias a todos los contribuyentes que ayudan a mejorar las audiomenciones de antorcha.


