torch audiomentations
v0.11.1

Pytorchのオーディオデータ増強。聴覚に触発されました。
nn.Moduleを拡張するため、Pytorch Neural Networkモデルの一部として統合できますper_batch 、 per_example 、 per_channelpip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parametersとunfreeze_parameters使用してください。PitchShift 、特に低いサンプルレートの場合、小さなピッチシフトをサポートしていません(#151)。回避策:低いサンプルレートに小さなピッチシフトを適用する必要がある場合は、効率的なピッチシフトターゲットを計算するための関数なしで、オーディオメントまたはトーチピッチシフトでピッチシフトを直接使用します。貢献者を歓迎します!小惑星のスラックに参加して、 torch-audiomentationsについて話し合い始めてください。
データ増強がモデルトレーニング速度のボトルネックになることは望ましくありません。これは、1D畳み込みを実行するのにかかる時間の比較です。
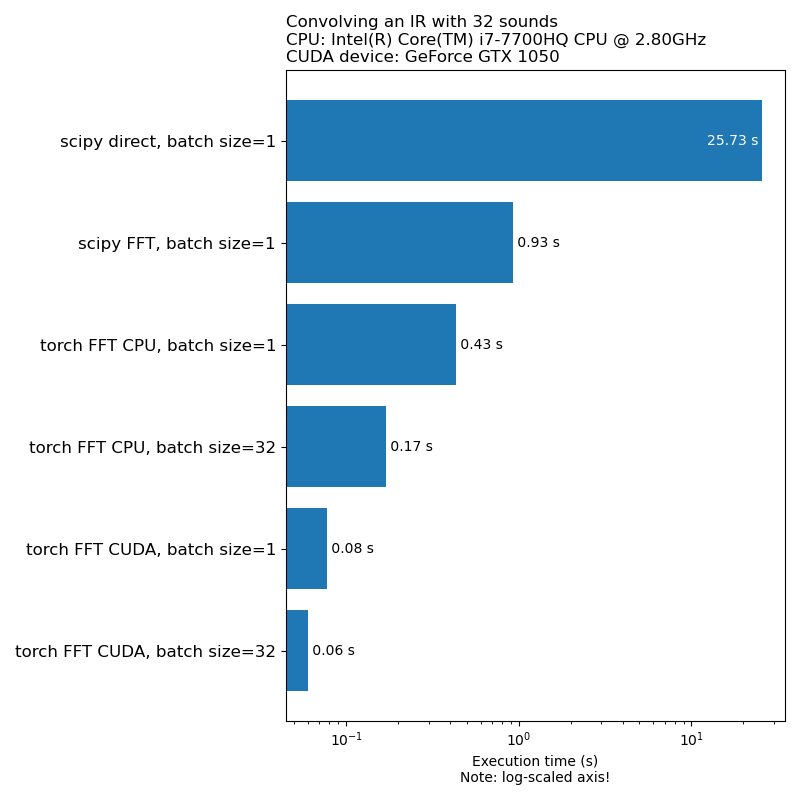
注:すべての変換がCPUと比較してこの印象的なスピードアップを持っているわけではありません。一般に、GPUでオーディオデータ増強を実行することが必ずしも最良の選択肢ではありません。詳細については、この記事を参照してください:https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
トーチ監視は初期の開発段階にあるため、APIは変更される可能性があります。
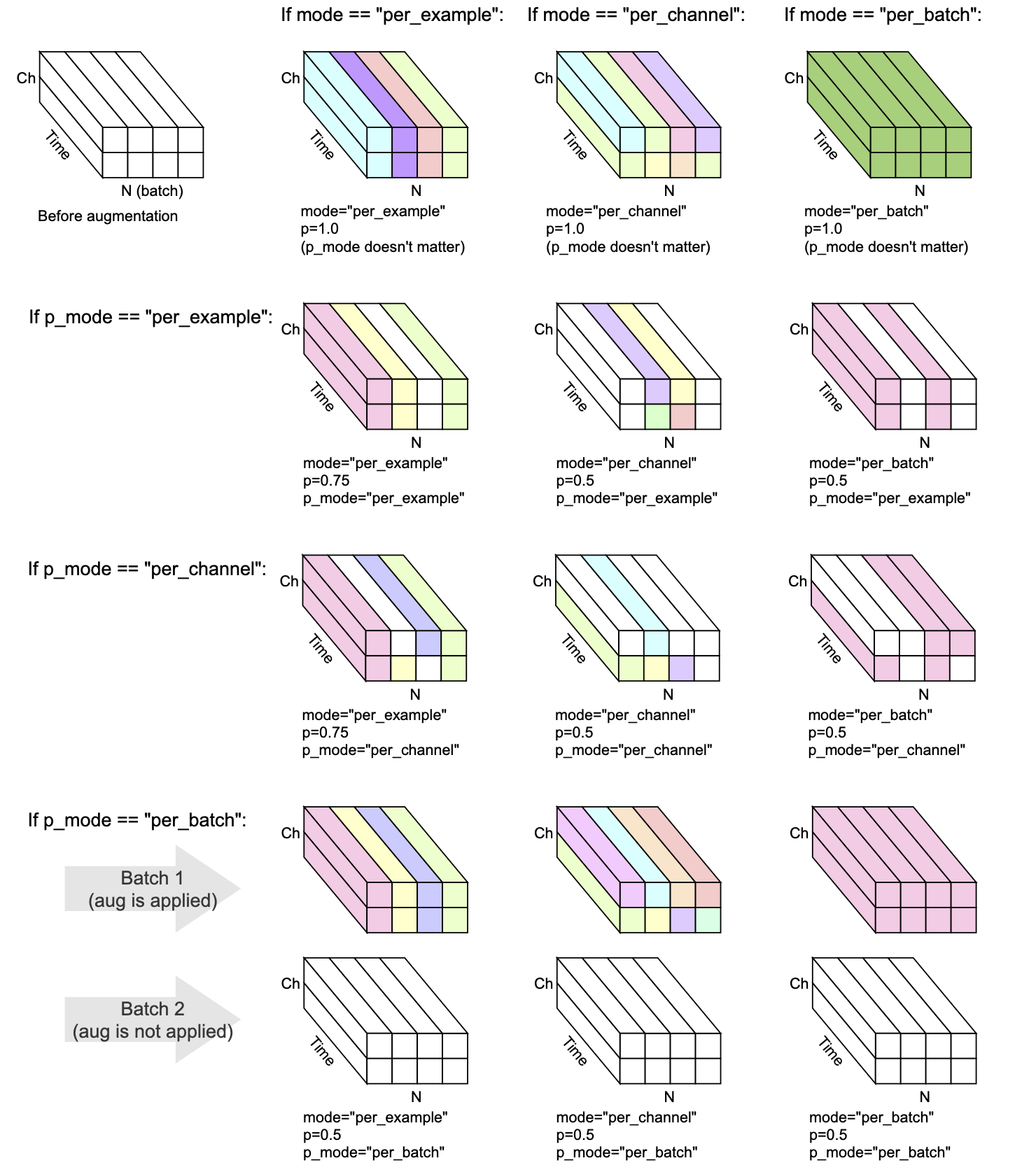
すべての変換には、 mode 、 p 、およびp_modeがあります。これは、増強の実行方法を決定するパラメーターです。
mode 、増強のランダム化がどのようにグループ化され、適用されるかを決定します。p 、増強を適用するオン/オフ確率を決定します。p_mode 、増強のオン/オフがどのように適用されるかを決定します。この視覚化はmodeとp_modeの異なる組み合わせが拡張を実行する方法を示しています。
v0.5.0に追加されました
入力オーディオに背景ノイズを追加します。
v0.7.0に追加されました
入力オーディオに色付きノイズを追加します。
v0.5.0に追加されました
与えられたオーディオをインパルス応答で調整します。
v0.9.0に追加されました
入力オーディオにバンドパスフィルタリングを適用します。
v0.10.0に追加されました
入力オーディオにバンドストップフィルタリングを適用します。 Notchフィルターとも呼ばれます。
v0.1.0に追加されました
音量を削減または増加させるために、オーディオにランダム振幅係数を掛けます。この手法は、入力オーディオの全体的なゲインにモデルがやや不変になるのに役立ちます。
警告:この変換は、[-1、1]範囲の外側のサンプルを返すことができます。これにより、後の段階でオーディオを使用することに応じて、クリッピングまたはラップの歪みにつながる可能性があります。 https://en.wikipedia.org/wiki/clipping_(Audio)#digital_clippingも参照してください
v0.8.0に追加されました
入力オーディオにハイパスフィルタリングを適用します。
v0.11.0に追加されました
この変換は、変更されていない入力を返します。データの増強を無効にする必要がある場合に、コードを簡素化するために使用できます。
v0.8.0に追加されました
入力オーディオにローパスフィルタリングを適用します。
v0.2.0に追加されました
一定量のゲインを適用して、バッチ内の各オーディオスニペットに存在する最高の信号レベルが0 dBFになります。つまり、すべてのサンプルが-1〜1の間でなければならない場合は、最大レベルが許容されます。
この変換には、[-1、1]範囲外に極端な値を持つオーディオスニペットのみに適用される代替モード(Apply_to = "only_too_loud_sounds")があります。これは、他のオーディオのままにしている間、音声が大きすぎるオーディオのデジタルクリッピングを回避するのに役立ちます。
v0.9.0に追加されました
ピッチシフトは、テンポを変更せずに上下に鳴ります。
v0.1.0に追加されました
オーディオサンプルを逆さまにし、極性を逆転させます。言い換えれば、波形に-1を掛けると、負の値が正しくなり、逆も同様です。結果は、孤立して再生されたときに元のものと比較して同じように聞こえます。ただし、他のオーディオソースと混合すると、結果は異なる場合があります。この波形反転手法は、オーディオキャンセルまたは2つの波形の差を取得するために使用されることがあります。ただし、オーディオデータの増強のコンテキストでは、この変換は、段階認識機械学習モデルをトレーニングする場合に役立ちます。
v0.5.0に追加されました
ロールオーバーの有無にかかわらず、オーディオを前方または後方にシフトします
v0.6.0に追加されました
マルチチャネルオーディオ入力(ステレオなど)を考えると、チャンネルをシャッフルします。この変換は、マルチチャネル波形を入力する機械学習モデルのポジショナルバイアスとの戦闘に役立ちます。
入力オーディオがモノである場合、この変換は警告を発すること以外は何もしません。
v0.10.0に追加されました
視覚ドメイン内の画像のランダムフリップと同様の時間軸に沿ったオーディオを逆(反転)します。これは、オーディオ分類のコンテキストで関連することができます。それは紙のAudioClipに正常に適用されました:画像、テキスト、オーディオにクリップを拡張します
Mix 、 Padding 、 RandomCrop 、 SpliceOut LowPassFilterとHighPassFilterの一定のカットオフ周波数をサポートするAddColoredNoiseにmax_f_decayを追加しますShiftで不正確なタイプのヒントを修正しますset_backendを削除して、TorchaudioからUserWarningを避けますIdentitytorch.Tensorの代替としてObjectDict出力タイプを追加します。この代替案は現在のオプトインです(後方互換性のため)ですが、古い出力タイプ( torch.Tensor )は非推奨であり、将来のバージョンでサポートが削除されることに注意してください。AddBackgroundNoiseおよびApplyImpulseResponseへのフォルダーのリストを指定することを許可しますPitchShiftでTorchaudio 0.11のサポートを確保するためにtorch-pitch-shiftの新しいバージョンが必要ですBandPassFilterがGPUで動作しなかったバグを修正しますAddBackgroundNoiseに追加するAddBackgroundNoiseで互換性のない長さに再サンプリングされることがあるバグを修正しますOneOf SomeOfを実装しますBandStopFilterとTimeInversionir_paths transform_parametersにApplyImpulseResponseに入れて、どのインパルス応答が使用されたかを調べることができるようにします。これにより、 freeze_parameters()に予想される動作が得られます。BandPassFilterで予想される2倍の大きさのバグを修正します。デフォルト値はそれに応じて更新されています。以前にmin_bandwidth_fractionおよび/またはmax_bandwidth_fractionを指定していた場合、以前と同じ動作を取得するには、それらの数値を2倍にする必要があります。 ApplyImpulseResponseにパラメーターcompensate_for_propagation_delayを追加しますBandPassFilterを実装しますPitchShiftを実装しますHighPassFilterとLowPassFilterを実装しますAddColoredNoiseを実装しますShuffleChannelsを実装しますAddBackgroundNoiseがCUDAで動作しなかったバグを修正するApplyImpulseResponseのパフォーマンスも向上します。 AddBackgroundNoiseをリリースし、 ApplyImpulseResponseShiftを実装しますsample_rateオプションにします。 forwardではなく__init__でsample_rateを指定することを許可します。これは、Torchaudio変換を今すぐComposeに使用できることを意味します。nn.Moduleサブクラスのparametersメソッドを使用できなかったバグを修正しますComposeを実装しますfrom_dictおよびfrom_yamlユーティリティ関数を実装しますper_batchとper_channelのサポートを追加しますPeakNormalizationを実装しますconvolveを公開しますGainとPolarityInversionによる初期リリーストーチ監視のためのGPU対応開発環境は、コンドラで作成できます。
conda env create pytest
トーチの監査の発達は、ノモノによって親切に支援されています。
トーチの監査の改善を支援してくれたすべての貢献者に感謝します。


