torch audiomentations
v0.11.1

زيادة بيانات الصوت في Pytorch. مستوحاة من السمع.
nn.Module ، بحيث يمكن دمجها كجزء من نموذج شبكة Pytorch العصبيةper_batch ، per_example و per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters و unfreeze_parameters في الوقت الحالي إذا كانت البيانات المستهدفة صوتية بنفس شكل الإدخال.PitchShift نوبات الملعب الصغيرة ، خاصة بالنسبة لمعدلات العينة المنخفضة (#151). الحل البديل: إذا كنت بحاجة إلى تحولات صغيرة في الملعب يتم تطبيقها على معدلات العينة المنخفضة ، فاستخدم الانزياح السمعي في المسموعات أو التحول في الشعلة مباشرة دون وظيفة لحساب أهداف التحول الفعالة. ترحيب المساهمين! انضم إلى الركود في الكويكب لبدء المناقشة حول torch-audiomentations معنا.
لا نريد أن يكون زيادة البيانات عنق الزجاجة في سرعة التدريب النموذجية. فيما يلي مقارنة بين الوقت الذي يستغرقه تشغيل الالتفاف 1D:
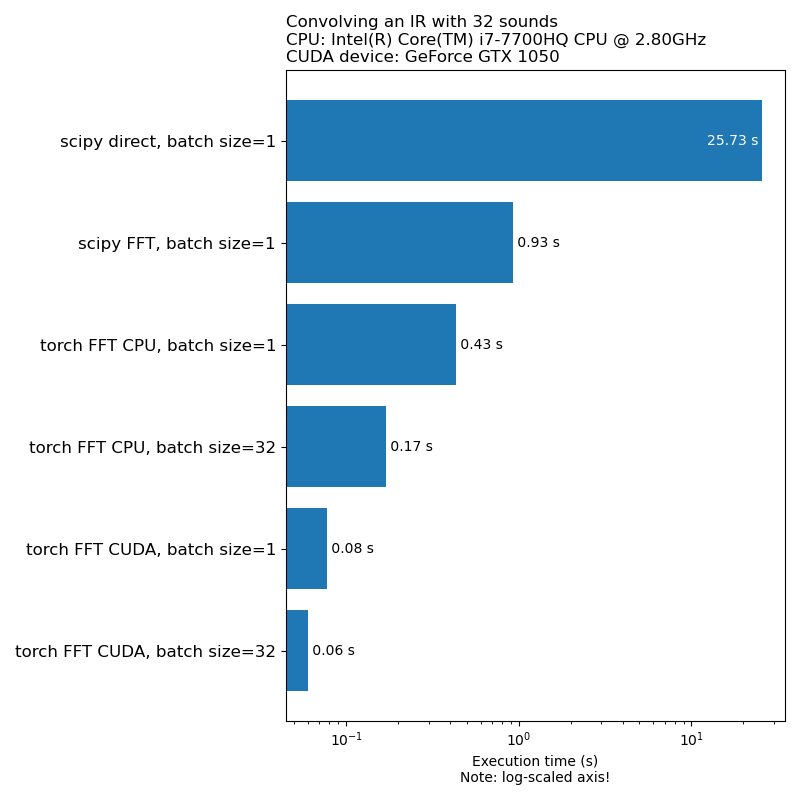
ملاحظة: ليس كل التحويلات لديها تسريع هذا مثير للإعجاب مقارنة بوحدة المعالجة المركزية. بشكل عام ، فإن تشغيل بيانات الصوت على GPU ليس دائمًا الخيار الأفضل. لمزيد من المعلومات ، راجع هذا المقال: https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
تُعتبر Torch-AudioMentations في مرحلة التنمية المبكرة ، وبالتالي فإن واجهات برمجة التطبيقات (APIs) عرضة للتغيير.
كل تحويل لديه mode ، p ، و p_mode - المعلمات التي تقرر كيفية تنفيذ زيادة.
mode كيفية تجميع العشوائية للزيادة وتطبيقها.p يقرر احتمال تشغيل/إيقاف تطبيق التعزيز.p_mode يقرر كيفية تطبيق ON/OFF من التعزيز. يوضح هذا التصور كيف تقوم مجموعات مختلفة من mode و p_mode بإجراء زيادة.
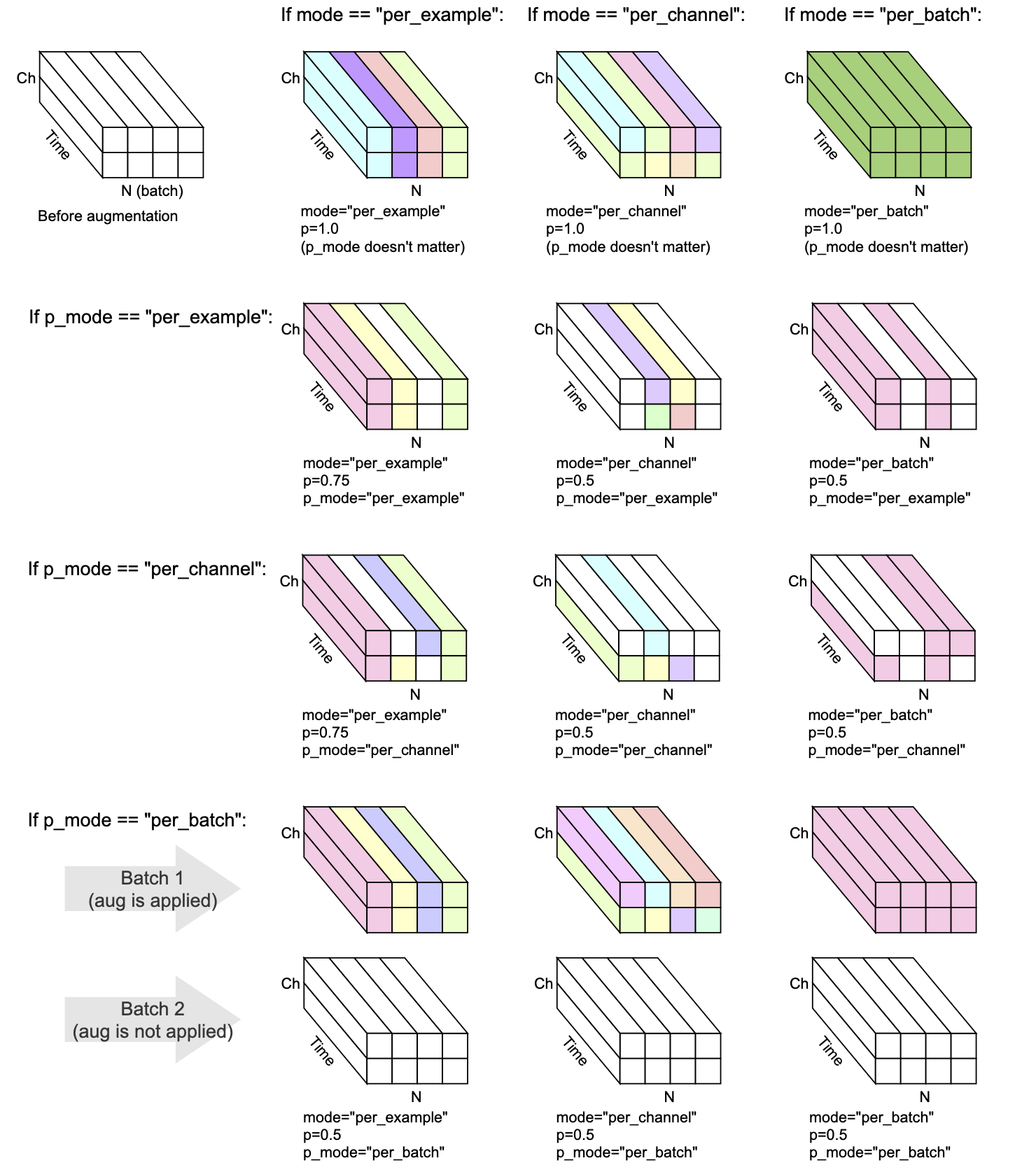
أضاف في v0.5.0
أضف ضوضاء الخلفية إلى صوت الإدخال.
أضيفت في v0.7.0
إضافة ضوضاء ملونة إلى صوت الإدخال.
أضاف في v0.5.0
حل الصوت المعطى مع استجابات الدافع.
أضاف في v0.9.0
قم بتطبيق تصفية تمرير النطاق على صوت الإدخال.
تمت إضافة في v0.10.0
قم بتطبيق تصفية توقف النطاق على صوت الإدخال. المعروف أيضا باسم مرشح الشق.
أضيفت في v0.1.0
اضرب الصوت بواسطة عامل السعة العشوائية لتقليل أو زيادة مستوى الصوت. يمكن أن تساعد هذه التقنية نموذجًا على أن يصبح ثابتًا إلى حد ما لتحقيق المكاسب الإجمالية لصوت المدخلات.
تحذير: يمكن لهذا التحول إرجاع عينات خارج نطاق [-1 ، 1] ، مما قد يؤدي إلى القطع أو التفاف ، اعتمادًا على ما تفعله مع الصوت في مرحلة لاحقة. انظر أيضًا https://en.wikipedia.org/wiki/clipping_(audio)#digital_clipping
أضيفت في v0.8.0
قم بتطبيق تصفية تمرير عالي على صوت الإدخال.
تمت إضافة في v0.11.0
هذا التحويل يعيد الإدخال دون تغيير. يمكن استخدامه لتبسيط الكود في الحالات التي يجب فيها تعطيل زيادة البيانات.
أضيفت في v0.8.0
قم بتطبيق تصفية تمرير منخفض على صوت الإدخال.
أضاف في v0.2.0
قم بتطبيق كمية ثابتة من الربح ، بحيث يصبح أعلى مستوى إشارة موجود في كل مقتطف صوتي في الدُفعة 0 DBFs ، أي أعلى مستوى مسموح به إذا كان يجب أن تكون جميع العينات بين -1 و 1.
يحتوي هذا التحويل على وضع بديل (application_to = "omsy_too_loud_sounds") حيث ينطبق فقط على مقتطفات الصوت التي لها قيم متطرفة خارج نطاق [-1 ، 1]. يعد هذا مفيدًا لتجنب القطع الرقمي في الصوت بصوت عالٍ للغاية ، مع ترك صوت آخر دون مساس.
أضاف في v0.9.0
يبدو أن تحريك الملعب لأعلى أو لأسفل دون تغيير الإيقاع.
أضيفت في v0.1.0
اقلب عينات الصوت رأسًا على عقب ، مما يعكس قطبية. بمعنى آخر ، اضرب الشكل الموجي بمقدار -1 ، لذلك تصبح القيم السلبية إيجابية ، والعكس صحيح. سوف تبدو النتيجة كما هي مقارنة بالأصل عند تشغيلها مرة أخرى في عزلة. ومع ذلك ، عند خلطها مع مصادر صوتية أخرى ، قد تكون النتيجة مختلفة. يتم استخدام تقنية انعكاس الموجة هذه في بعض الأحيان لإلغاء الصوت أو الحصول على الفرق بين شكلين موجيين. ومع ذلك ، في سياق زيادة بيانات الصوت ، يمكن أن يكون هذا التحول مفيدًا عند تدريب نماذج التعلم الآلي على دراية المرحلة.
أضاف في v0.5.0
قم بتحويل الصوت إلى الأمام أو للخلف ، مع أو بدون التمرير
تمت إضافة في v0.6.0
بالنظر إلى إدخال الصوت متعدد القنوات (EG Stereo) ، خلط القنوات ، على سبيل المثال ، يمكن أن يصبح اليسار يمينًا والعكس صحيح. يمكن أن يساعد هذا التحول في مكافحة التحيز الموضعي في نماذج التعلم الآلي التي تقوم بإدخال أشكال موجية متعددة القنوات.
إذا كان صوت الإدخال أحاديًا ، فإن هذا التحول لا يفعل شيئًا سوى انبعاث تحذير.
تمت إضافة في v0.10.0
عكسي (انقلاب) الصوت على طول المحور الزمني مماثل للوجه العشوائي لصورة في المجال البصري. هذا يمكن أن يكون ذا صلة في سياق تصنيف الصوت. تم تطبيقه بنجاح في الورق Audioclip: تمديد المقطع إلى الصورة والنصوص والصوت
Mix ، Padding ، RandomCrop و SpliceOut LowPassFilter و HighPassFilterAddColoredNoiseShiftset_backend لتجنب UserWarning من Torchaudio IdentityObjectDict كبديل لـ torch.Tensor . هذا البديل يتم اختياره في الوقت الحالي (من أجل التوافق مع الإصدارات السابقة) ، ولكن لاحظ أن نوع الإخراج القديم ( torch.Tensor ) قد تم إهماله وسيتم إزالته في إصدار مستقبلي.AddBackgroundNoise ApplyImpulseResponsetorch-pitch-shift لضمان دعم Torchaudio 0.11 في PitchShiftBandPassFilter على GPU AddBackgroundNoiseAddBackgroundNoise OneOf SomeOf لتطبيق واحد أو أكثر من مجموعة من التحويلاتBandStopFilter و TimeInversionir_paths في transform_parameters في ApplyImpulseResponse ، لذلك من الممكن فحص الاستجابات التي تم استخدامها. هذا يعطي أيضا freeze_parameters() السلوك المتوقع.BandPassFilter . تم تحديث القيم الافتراضية وفقًا لذلك. إذا كنت تحدد سابقًا min_bandwidth_fraction و/أو max_bandwidth_fraction ، فأنت الآن بحاجة إلى مضاعفة هذه الأرقام للحصول على نفس السلوك كما كان من قبل. compensate_for_propagation_delay في ApplyImpulseResponseBandPassFilterPitchShiftHighPassFilter و LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise على CUDAApplyImpulseResponse . AddBackgroundNoise وتطبيق ApplyImpulseResponseShiftsample_rate اختياريًا. السماح بتحديد sample_rate في __init__ بدلاً من forward . هذا يعني أنه يمكن استخدام تحويلات Torchaudio في Compose الآن.parameters من الفئة الفرعية nn.ModuleCompose لتطبيق تحويلات متعددةfrom_dict و from_yaml لتحميل تكوينات زيادة البيانات من DICT أو JSON أو YAMLper_batch و per_channelPeakNormalizationconvolve في واجهة برمجة التطبيقاتGain PolarityInversionيمكن إنشاء بيئة تنمية تدعم GPU للاشتعالات مع الكوندا:
conda env create pytest
تفضل بتطوير تظليل الشعلة.
شكرا لجميع المساهمين الذين يساعدون في تحسين التزحلق الشعاعي.


