torch audiomentations
v0.11.1

Aumentação de dados de áudio em Pytorch. Inspirado em audiomentações.
nn.Module , para que possam ser integrados como parte de um modelo de rede neural pytorchper_batch , per_example e per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters e unfreeze_parameters Por enquanto, se os dados de destino forem áudio com a mesma forma que a entrada.PitchShift não suporta pequenas mudanças de afinação, especialmente para baixas taxas de amostragem (#151). Solução alternativa: se você precisar de pequenas mudanças de afinação aplicadas a baixas taxas de amostragem, use o pitchshift em audiomentações ou deslocamento de tocha diretamente sem a função para calcular alvos eficientes de deslocamento de afinação. Contribuidores são bem -vindos! Junte-se à folga do asteróide para começar a discutir sobre torch-audiomentations conosco.
Não queremos que o aumento de dados seja um gargalo na velocidade de treinamento do modelo. Aqui está uma comparação do tempo necessário para executar a convolução 1D:
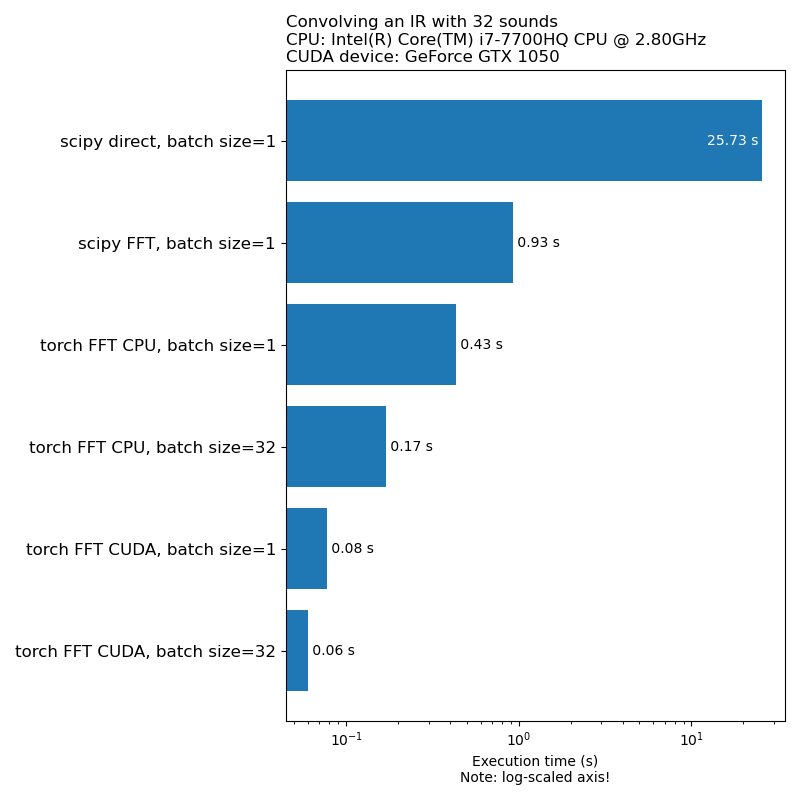
NOTA: Nem todas as transformações têm uma aceleração tão impressionante em comparação com a CPU. Em geral, o aumento de dados de áudio na GPU nem sempre é a melhor opção. Para mais informações, consulte este artigo: https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
Torch-Audiomentations está em um estágio inicial de desenvolvimento; portanto, as APIs estão sujeitas a alterações.
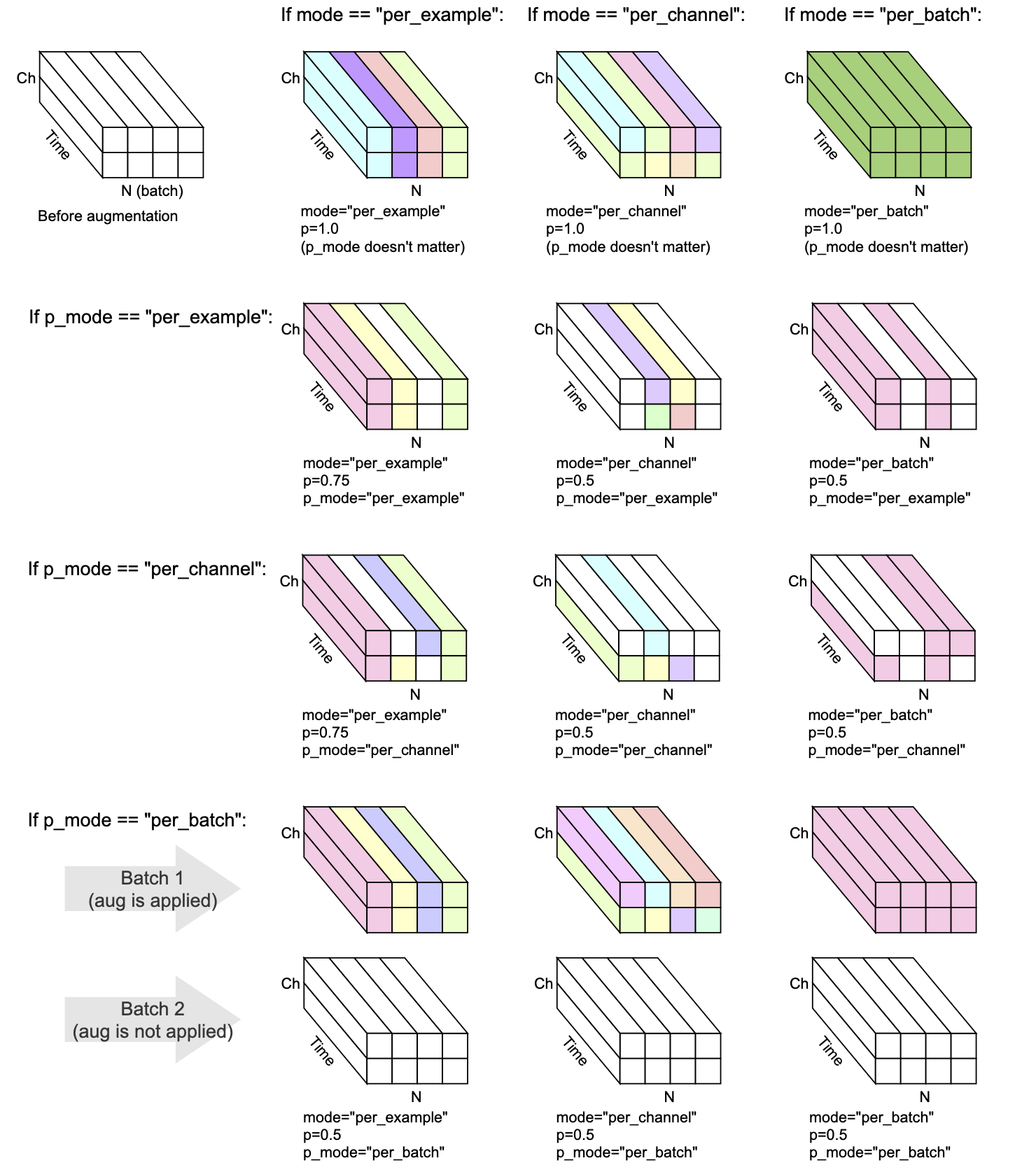
Cada transformação tem mode , p e p_mode - os parâmetros que decidem como o aumento é executado.
mode decide como a randomização do aumento é agrupada e aplicada.p decide a probabilidade ON/OFF de aplicar o aumento.p_mode decide como o aumento/desativação do aumento é aplicado. Essa visualização mostra como diferentes combinações de mode e p_mode executariam um aumento.
Adicionado na v0.5.0
Adicione o ruído de fundo ao áudio de entrada.
Adicionado em v0.7.0
Adicione o ruído colorido ao áudio de entrada.
Adicionado na v0.5.0
Convidar o áudio fornecido com respostas de impulso.
Adicionado na v0.9.0
Aplique a filtragem de passa-banda no áudio de entrada.
Adicionado na v0.10.0
Aplique filtragem de parada de banda no áudio de entrada. Também conhecido como filtro Notch.
Adicionado em v0.1.0
Multiplique o áudio por um fator de amplitude aleatória para reduzir ou aumentar o volume. Essa técnica pode ajudar um modelo a se tornar um tanto invariante para o ganho geral do áudio de entrada.
AVISO: Essa transformação pode retornar amostras para fora da faixa [-1, 1], o que pode levar a recorte ou embrulhar distorção, dependendo do que você faz com o áudio em um estágio posterior. Veja também https://en.wikipedia.org/wiki/clipping_(audio)#digital_clipping
Adicionado em v0.8.0
Aplique a filtragem passa-alta no áudio de entrada.
Adicionado na v0.11.0
Esta transformação retorna a entrada inalterada. Ele pode ser usado para simplificar o código nos casos em que o aumento de dados deve ser desativado.
Adicionado em v0.8.0
Aplique filtragem passa-baixa no áudio de entrada.
Adicionado na v0.2.0
Aplique uma quantidade constante de ganho, para que o nível mais alto de sinal presente em cada trecho de áudio no lote se torne 0 dBfs, ou seja, o nível mais alto permitido se todas as amostras devem estar entre -1 e 1.
Essa transformação possui um modo alternativo (APLIC_TO = "ONE_TOO_LOUD_SOUNDS"), onde se aplica apenas a trechos de áudio que possuem valores extremos fora da faixa [-1, 1]. Isso é útil para evitar o recorte digital no áudio que é muito alto, deixando outro áudio intocado.
Adicionado na v0.9.0
A mudança de passo soa para cima ou para baixo sem alterar o ritmo.
Adicionado em v0.1.0
Vire as amostras de áudio de cabeça para baixo, revertendo sua polaridade. Em outras palavras, multiplique a forma de onda por -1, para que os valores negativos se tornem positivos e vice -versa. O resultado soará o mesmo em comparação com o original quando reproduzido em isolamento. No entanto, quando misturado com outras fontes de áudio, o resultado pode ser diferente. Às vezes, essa técnica de inversão da forma de onda é usada para cancelamento de áudio ou obter a diferença entre duas formas de onda. No entanto, no contexto do aumento de dados de áudio, essa transformação pode ser útil ao treinar modelos de aprendizado de máquina com reconhecimento de fase.
Adicionado na v0.5.0
Mude o áudio para frente ou para trás, com ou sem rolagem
Adicionado em v0.6.0
Dada a entrada de áudio multicanal (por exemplo, estéreo), embaralhe os canais, por exemplo, a esquerda pode se tornar certa e vice -versa. Essa transformação pode ajudar a combater o viés posicional em modelos de aprendizado de máquina que inseram formas de onda multicanal.
Se o áudio de entrada for mono, essa transformação não fará nada, exceto emite um aviso.
Adicionado na v0.10.0
Reverte (inverter) o áudio ao longo do eixo do tempo semelhante ao flip aleatório de uma imagem no domínio visual. Isso pode ser relevante no contexto da classificação de áudio. Foi aplicado com sucesso no papel Audioclip: estendendo o clipe à imagem, texto e áudio
Mix , Padding , RandomCrop e SpliceOut LowPassFilter e HighPassFilterAddColoredNoiseShiftset_backend para evitar UserWarning do Torchaudio IdentityObjectDict como alternativa à torch.Tensor . Essa alternativa é aceita por enquanto (para compatibilidade com versões anteriores), mas observe que o tipo de saída antigo ( torch.Tensor ) está descontinuado e o suporte para ele será removido em uma versão futura.AddBackgroundNoise e ApplyImpulseResponsetorch-pitch-shift para garantir o suporte para Torchaudio 0.11 no PitchShiftBandPassFilter não funcionou na GPU AddBackgroundNoiseAddBackgroundNoise OneOf e SomeOf para aplicar um ou mais um determinado conjunto de transformaçõesBandStopFilter e TimeInversionir_paths em transform_parameters no ApplyImpulseResponse para que seja possível inspecionar quais respostas de impulso foram usadas. Isso também fornece freeze_parameters() o comportamento esperado.BandPassFilter . Os valores padrão foram atualizados de acordo. Se você estava especificando anteriormente min_bandwidth_fraction e/ou max_bandwidth_fraction , agora precisa dobrar esses números para obter o mesmo comportamento de antes. compensate_for_propagation_delay no ApplyImpulseResponseBandPassFilterPitchShiftHighPassFilter e LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise não funcionou no CUDAApplyImpulseResponse . AddBackgroundNoise e ApplyImpulseResponseShiftsample_rate Opcional. Deixe especificar sample_rate em __init__ em vez de forward . Isso significa que as transformações de Torchaudio podem ser usadas no Compose agora.parameters da subclasse nn.ModuleCompose para aplicar várias transformadasfrom_dict e from_yamlper_batch e per_channelPeakNormalizationconvolve na APIGain e PolarityInversionUm ambiente de desenvolvimento habilitado para GPU para Audiomentiações de Torch pode ser criado com o CONDA:
conda env create pytest
O desenvolvimento de tocha-audiomentiações é gentilmente apoiado por Nomono.
Obrigado a todos os colaboradores que ajudam a melhorar a tocha-audiomentiações.


