torch audiomentations
v0.11.1

Увеличение аудиоданных в Pytorch. Вдохновленный аудиоманциями.
nn.Module , поэтому они могут быть интегрированы как часть модели нейронной сети Pytorchper_batch , per_example и per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters и unfreeze_parameters .PitchShift не поддерживает небольшие сдвиги шага, особенно для низких показателей дискретизации (#151). Обходной путь: если вам нужны малые сдвиги шага, применяемые к низким показателям дискретизации, используйте перенос в аудиоменах или сдвиг с факелом непосредственно без функции для расчета эффективных целей сдвига шага. Участники приветствуются! Присоединяйтесь к слабым астероиду, чтобы начать обсуждать с нами torch-audiomentations .
Мы не хотим, чтобы увеличение данных было узким местом в скорости тренировок. Вот сравнение времени, необходимого для запуска 1D свертки:
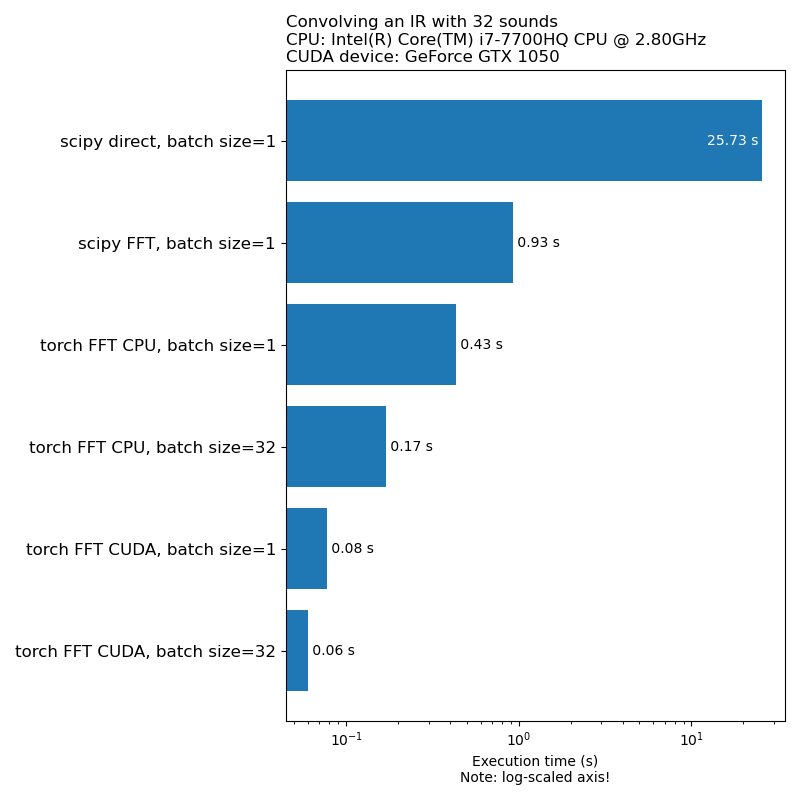
Примечание. Не все преобразования имеют ускорение, впечатляющее по сравнению с процессором. В целом, запуск аудиодативных данных на графическом процессоре не всегда является лучшим вариантом. Для получения дополнительной информации см. В этой статье: https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
Факел-авторские препараты находятся на ранней стадии развития, поэтому API могут быть изменены.
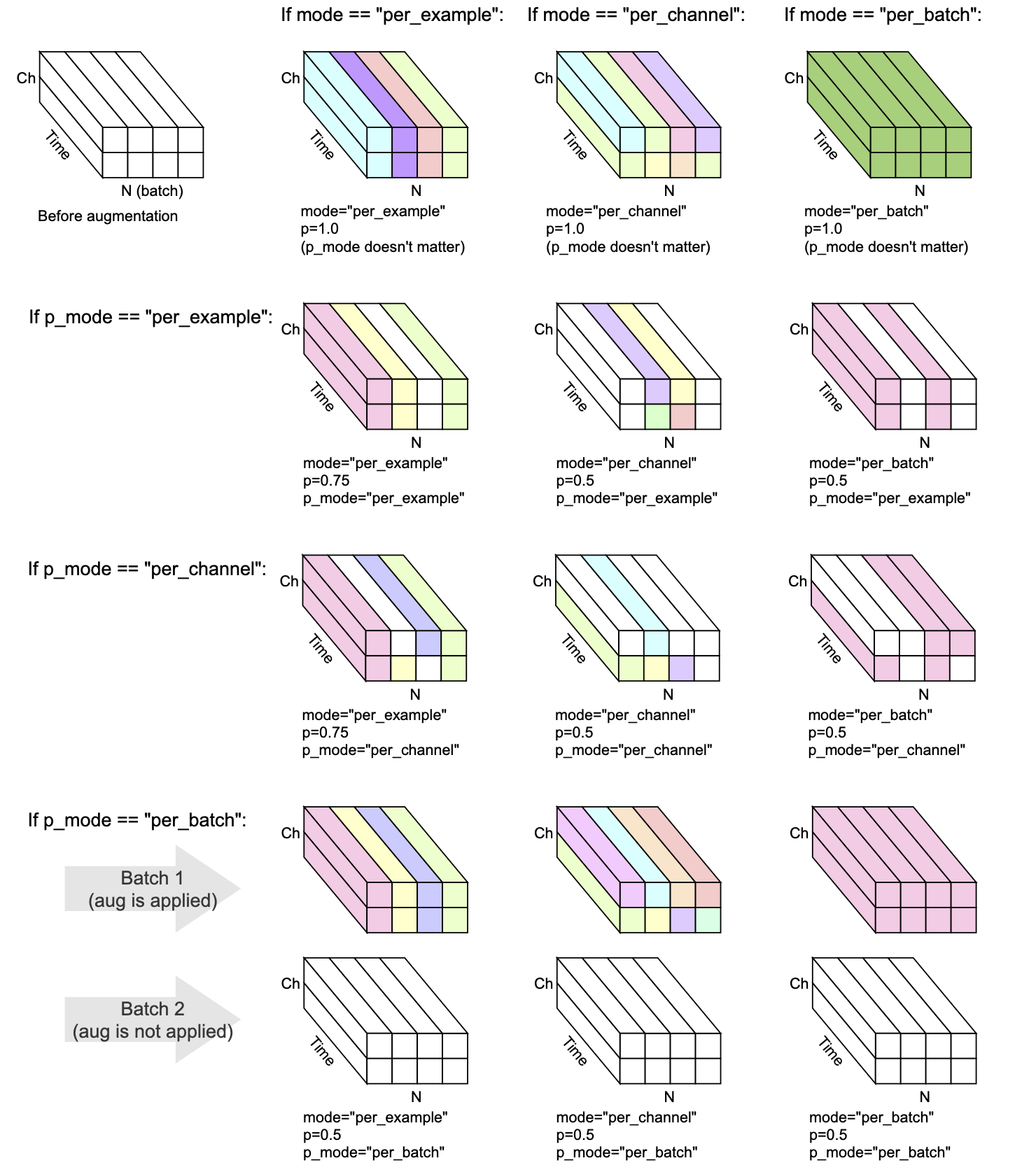
Каждое преобразование имеет mode , p и p_mode - параметры, которые решают, как выполняется увеличение.
mode решает, как рандомизация увеличения сгруппирована и применяется.p решает вероятность применения увеличения.p_mode решает, как применяется включение/выключение увеличения. Эта визуализация показывает, как различные комбинации mode и p_mode будут выполнять увеличение.
Добавлен в V0.5.0
Добавьте фоновый шум в входной аудио.
Добавлено в v0.7.0
Добавьте цветный шум в входной аудио.
Добавлен в V0.5.0
Создать данное звук с импульсивными ответами.
Добавлен в v0.9.0
Применить фильтрацию полосы проходов на входной аудио.
Добавлено в v0.10.0
Применить фильтрацию с полосой к входному аудио. Также известен как Notch Filter.
Добавлено в v0.1.0
Умножьте звук на коэффициент случайной амплитуды, чтобы уменьшить или увеличить объем. Этот метод может помочь модели стать несколько инвариантной к общему усилению входного аудио.
ПРЕДУПРЕЖДЕНИЕ: Это преобразование может возвращать образцы за пределами диапазона [-1, 1], что может привести к обрезанию или искажению обертывания, в зависимости от того, что вы делаете с аудио на более поздней стадии. См. Также https://en.wikipedia.org/wiki/clipping_(Audio)#digital_clipping
Добавлено в v0.8.0
Примените фильтрацию с высокой частотой на входной аудио.
Добавлено в v0.11.0
Это преобразование возвращает вход без изменений. Его можно использовать для упрощения кода в тех случаях, когда увеличение данных должно быть отключено.
Добавлено в v0.8.0
Примените фильтрацию низкопрохожника на входной аудио.
Добавлено в V0.2.0
Примените постоянное количество усиления, так что самый высокий уровень сигнала, присутствующий в каждом фрагменте звука в партии, становится 0 дБФ, то есть, самый громкий уровень, разрешенный, если все образцы должны быть от -1 до 1.
Это преобразование имеет альтернативный режим (Apply_to = "только_TOO_LOUD_SOUNDS"), где он применим только к фрагментам аудио, которые имеют экстремальные значения за пределами диапазона [-1, 1]. Это полезно для того, чтобы избежать цифровой обрезки в аудио, который слишком громкий, оставляя другие звуки нетронутыми.
Добавлен в v0.9.0
Сдвиг шага звучит вверх или вниз, не изменяя темп.
Добавлено в v0.1.0
Переверните образцы звука вверх дном, отменив свою полярность. Другими словами, умножьте форму волны на -1, чтобы отрицательные значения стали положительными, и наоборот. Результат будет звучать одинаково по сравнению с оригиналом при воспроизведении в изоляции. Однако при смешивании с другими источниками аудио, результат может быть другим. Этот метод инверсии формы волны иногда используется для отмены звука или получения разницы между двумя формами волны. Тем не менее, в контексте увеличения аудиоданных, это преобразование может быть полезно при обучении моделей машинного обучения.
Добавлен в V0.5.0
Сдвиг аудио вперед или назад, с или без него
Добавлено в v0.6.0
Учитывая многоканальный звуковой ввод (например, стерео), перетасовать каналы, например, влево может стать правым и наоборот. Это преобразование может помочь бороться с позиционным смещением в моделях машинного обучения, которые вводят многоканальные сигналы.
Если входной звук является моно, это преобразование ничего не делает, кроме как излучать предупреждение.
Добавлено в v0.10.0
Обратный (инвертируйте) аудио вдоль оси времени, аналогичной случайному перевороту изображения в визуальной области. Это может быть актуально в контексте аудио -классификации. Он был успешно применен в бумажной аудиооклипке: расширение клипа на изображение, текст и аудио
Mix , Padding , RandomCrop и SpliceOut LowPassFilter и HighPassFilterAddColoredNoiseShiftset_backend , чтобы избежать UserWarning из Torchaudio IdentityObjectDict в качестве альтернативы torch.Tensor . Эта альтернатива на данный момент (для обратной совместимости), но обратите внимание, что старый выходной тип ( torch.Tensor ) устарел, и поддержка его будет удалена в будущей версии.AddBackgroundNoise и ApplyImpulseResponsetorch-pitch-shift PitchShiftBandPassFilter не работал на графическом процессоре AddBackgroundNoiseAddBackgroundNoise OneOf и SomeOf для применения одного или нескольких заданных набора преобразованийBandStopFilter и TimeInversionir_paths в Transform_parameters в ApplyImpulseResponse , чтобы можно было проверить, какие импульсные ответы были использованы. Это также дает freeze_parameters() ожидаемое поведение.BandPassFilter . Значения по умолчанию были обновлены соответственно. Если вы ранее указывали min_bandwidth_fraction и/или max_bandwidth_fraction , теперь вам нужно удвоить эти числа, чтобы получить то же поведение, что и раньше. compensate_for_propagation_delay в ApplyImpulseResponseBandPassFilterPitchShiftHighPassFilter и LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise не работал на CudaApplyImpulseResponse . AddBackgroundNoise и ApplyImpulseResponseShiftsample_rate необязательным. Разрешить указать sample_rate в __init__ вместо forward . Это означает, что преобразование Torchaudio можно использовать сейчас в Compose .parameters подкласса nn.ModuleCompose для применения нескольких преобразованийfrom_dict и from_yaml для загрузки конфигураций увеличения данных из DICT, JSON или YAMLper_batch и per_channelPeakNormalizationconvolve в APIGain и PolarityInversionМожно создать среду разработки с поддержкой графического процессора для факела-автоментаций с помощью Conda:
conda env create pytest
Разработка факела-автоментаций любезно поддерживается Nomono.
Спасибо всем участникам, которые помогают улучшить факел-аудиоментации.


