torch audiomentations
v0.11.1

การเพิ่มข้อมูลเสียงใน Pytorch แรงบันดาลใจจาก Audiomentations
nn.Module ดังนั้นพวกเขาจึงสามารถรวมเข้าเป็นส่วนหนึ่งของโมเดลเครือข่ายนิวรัล Pytorchper_batch , per_example และ per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters และ unfreeze_parameters สำหรับตอนนี้หากข้อมูลเป้าหมายเป็นเสียงที่มีรูปร่างเหมือนกับอินพุตPitchShift ไม่รองรับการเปลี่ยนแปลงระดับเสียงเล็ก ๆ โดยเฉพาะอย่างยิ่งสำหรับอัตราตัวอย่างต่ำ (#151) วิธีแก้ปัญหา: หากคุณต้องการการเลื่อนระดับเสียงเล็ก ๆ ที่ใช้กับอัตราตัวอย่างต่ำให้ใช้ pitchshift ใน audiomentations หรือคบเพลิง-พุ่งเข้าหาโดยตรงโดยไม่ต้องใช้ฟังก์ชั่นสำหรับการคำนวณเป้าหมายการเปลี่ยนระยะพิทช์ที่มีประสิทธิภาพ ยินดีต้อนรับผู้มีส่วนร่วม! เข้าร่วมการหย่อนของดาวเคราะห์น้อยเพื่อเริ่มพูดคุยเกี่ยวกับ torch-audiomentations กับเรา
เราไม่ต้องการให้การเพิ่มข้อมูลเป็นคอขวดในความเร็วในการฝึกอบรมแบบจำลอง นี่คือการเปรียบเทียบเวลาที่ใช้ในการเรียกใช้ 1D convolution:
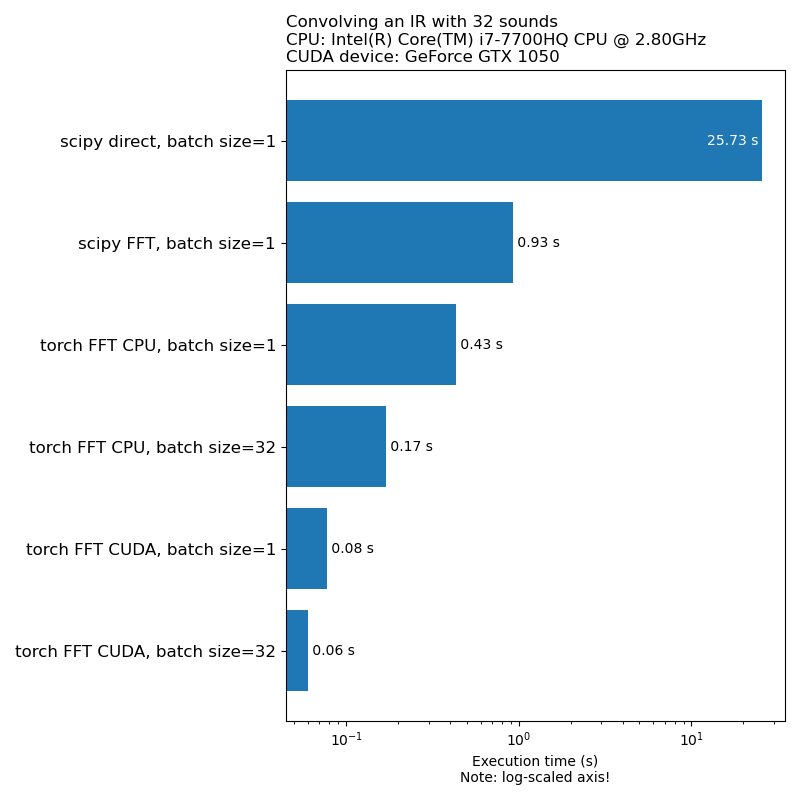
หมายเหตุ: การแปลงทั้งหมดไม่ใช่การเร่งความเร็วที่น่าประทับใจเมื่อเทียบกับ CPU โดยทั่วไปการใช้การเพิ่มข้อมูลเสียงบน GPU ไม่ใช่ตัวเลือกที่ดีที่สุดเสมอไป สำหรับข้อมูลเพิ่มเติมดูบทความนี้: https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
Torch-Audiomentations อยู่ในช่วงเริ่มต้นการพัฒนาดังนั้น APIs อาจมีการเปลี่ยนแปลง
การแปลงทุกครั้งมี mode , p และ p_mode - พารามิเตอร์ที่ตัดสินใจว่าจะดำเนินการเสริมอย่างไร
mode ตัดสินใจว่าการสุ่มของการเพิ่มการจัดกลุ่มและนำไปใช้อย่างไรp ตัดสินใจเปิด/ปิดความน่าจะเป็นของการใช้การเพิ่มp_mode ตัดสินใจว่าการเปิด/ปิดของการเพิ่มการเพิ่ม การสร้างภาพข้อมูลนี้แสดงให้เห็นว่าการรวมกันของ mode และ p_mode จะดำเนินการเพิ่มได้อย่างไร
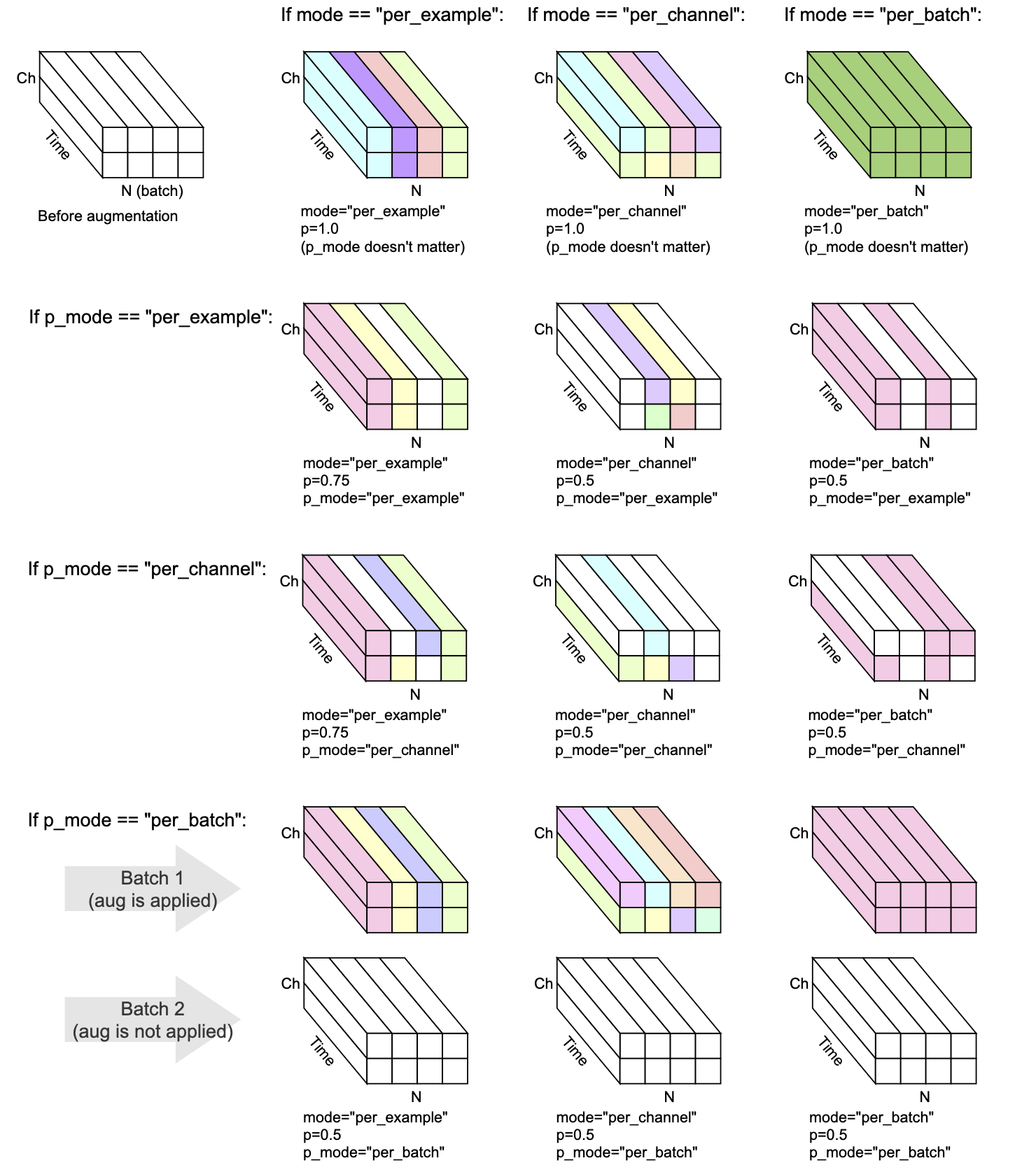
เพิ่มใน v0.5.0
เพิ่มเสียงพื้นหลังลงในเสียงอินพุต
เพิ่มใน v0.7.0
เพิ่มเสียงสีลงในเสียงอินพุต
เพิ่มใน v0.5.0
โน้มน้าวเสียงที่ได้รับพร้อมกับการตอบสนองแบบอิมพัลส์
เพิ่มใน v0.9.0
ใช้การกรอง Band-Pass กับเสียงอินพุต
เพิ่มใน v0.10.0
ใช้การกรองแบบแบนด์แบบสต็อปกับเสียงอินพุต ยังเป็นที่รู้จักกันในชื่อตัวกรอง Notch
เพิ่มใน v0.1.0
คูณเสียงด้วยปัจจัยแอมพลิจูดแบบสุ่มเพื่อลดหรือเพิ่มระดับเสียง เทคนิคนี้สามารถช่วยให้โมเดลกลายเป็นค่าคงที่เล็กน้อยต่อการได้รับโดยรวมของเสียงอินพุต
คำเตือน: การแปลงนี้สามารถส่งคืนตัวอย่างนอกช่วง [-1, 1] ซึ่งอาจนำไปสู่การตัดหรือห่อบิดขึ้นอยู่กับสิ่งที่คุณทำกับเสียงในระยะต่อมา ดูเพิ่มเติมที่ https://en.wikipedia.org/wiki/clipping_(Audio)#digital_clipping
เพิ่มใน v0.8.0
ใช้การกรองผ่านผ่านระดับสูงกับเสียงอินพุต
เพิ่มใน v0.11.0
การแปลงนี้ส่งคืนอินพุตไม่เปลี่ยนแปลง มันสามารถใช้สำหรับการทำให้รหัสง่ายขึ้นในกรณีที่ควรปิดใช้งานการเพิ่มข้อมูล
เพิ่มใน v0.8.0
ใช้การกรองผ่านผ่านทางต่ำกับเสียงอินพุต
เพิ่มใน v0.2.0
ใช้อัตราขยายที่คงที่ดังนั้นระดับสัญญาณสูงสุดที่มีอยู่ในแต่ละตัวอย่างเสียงในแบทช์จะกลายเป็น 0 dbfs นั่นคือระดับเสียงที่ดังที่สุดหากตัวอย่างทั้งหมดต้องอยู่ระหว่าง -1 และ 1
การแปลงนี้มีโหมดทางเลือก (appl_to = "only_too_loud_sounds") โดยที่มันใช้กับตัวอย่างเสียงที่มีค่าสุดขีดนอกช่วง [-1, 1] เท่านั้น สิ่งนี้มีประโยชน์สำหรับการหลีกเลี่ยงการตัดดิจิตอลในเสียงที่ดังเกินไปในขณะที่ปล่อยให้เสียงอื่นไม่ถูกแตะต้อง
เพิ่มใน v0.9.0
เสียงเลื่อนดังขึ้นหรือลงโดยไม่เปลี่ยนจังหวะ
เพิ่มใน v0.1.0
พลิกตัวอย่างเสียงคว่ำลงกลับขั้วของพวกเขา กล่าวอีกนัยหนึ่งคูณรูปคลื่นด้วย -1 ดังนั้นค่าลบจึงกลายเป็นบวกและในทางกลับกัน ผลลัพธ์จะฟังดูเหมือนกันเมื่อเทียบกับต้นฉบับเมื่อเล่นแยกกลับ อย่างไรก็ตามเมื่อผสมกับแหล่งเสียงอื่น ๆ ผลลัพธ์อาจแตกต่างกัน เทคนิคการผกผันของรูปคลื่นนี้บางครั้งใช้สำหรับการยกเลิกเสียงหรือได้รับความแตกต่างระหว่างรูปคลื่นสองรูป อย่างไรก็ตามในบริบทของการเพิ่มข้อมูลเสียงการแปลงนี้จะมีประโยชน์เมื่อการฝึกอบรมแบบจำลองการเรียนรู้ของเครื่องที่รับรู้เฟส
เพิ่มใน v0.5.0
เลื่อนเสียงไปข้างหน้าหรือย้อนกลับโดยมีหรือไม่มีโรลโอเวอร์
เพิ่มใน v0.6.0
เมื่อได้รับอินพุตเสียงหลายช่อง (เช่นสเตอริโอ), สลับช่องทางเช่นซ้ายสามารถกลายเป็นถูกต้องและในทางกลับกัน การแปลงนี้สามารถช่วยต่อสู้กับอคติตำแหน่งในรูปแบบการเรียนรู้ของเครื่องที่ป้อนรูปคลื่นหลายช่องสัญญาณ
หากเสียงอินพุตเป็นโมโนการแปลงนี้จะไม่ทำอะไรเลยนอกจากปล่อยคำเตือน
เพิ่มใน v0.10.0
ย้อนกลับ (กลับ) เสียงตามแกนเวลาคล้ายกับการพลิกภาพแบบสุ่มในโดเมนภาพ สิ่งนี้สามารถเกี่ยวข้องในบริบทของการจำแนกเสียง มันถูกนำไปใช้อย่างประสบความสำเร็จใน Audioclip กระดาษ: ขยายคลิปไปยังรูปภาพข้อความและเสียง
Mix , Padding , RandomCrop และ SpliceOut LowPassFilter และ HighPassFilterAddColoredNoiseShiftset_backend เพื่อหลีกเลี่ยง UserWarning จาก TORCHAUDIO IdentityObjectDict เป็นทางเลือกแทน torch.Tensor ทางเลือกนี้คือการเลือกใช้สำหรับตอนนี้ (สำหรับความเข้ากันได้ย้อนหลัง) แต่โปรดทราบว่าประเภทเอาต์พุตเก่า ( torch.Tensor ) เลิกใช้แล้วและสนับสนุนมันจะถูกลบออกในรุ่นอนาคตAddBackgroundNoise และ ApplyImpulseResponsetorch-pitch-shift รุ่นใหม่เพื่อให้แน่ใจว่ารองรับ Torchaudio 0.11 ใน PitchShiftBandPassFilter ไม่ทำงานบน GPU AddBackgroundNoiseAddBackgroundNoise OneOf และ SomeOf สำหรับการใช้ชุดการแปลงที่กำหนดอย่างน้อยหนึ่งชุดBandStopFilter และ TimeInversionir_paths ใน transform_parameters ใน ApplyImpulseResponse ดังนั้นจึงเป็นไปได้ที่จะตรวจสอบสิ่งที่ใช้การตอบสนองของแรงกระตุ้น นอกจากนี้ยังให้ freeze_parameters() พฤติกรรมที่คาดหวังBandPassFilter ค่าเริ่มต้นได้รับการอัปเดตตามนั้น หากก่อนหน้านี้คุณระบุ min_bandwidth_fraction และ/หรือ max_bandwidth_fraction ตอนนี้คุณต้องเพิ่มตัวเลขเหล่านั้นให้เป็นสองเท่าเพื่อให้ได้พฤติกรรมเหมือนเดิม compensate_for_propagation_delay ใน ApplyImpulseResponseBandPassFilterPitchShiftHighPassFilter และ LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise ไม่ทำงานบน cudaApplyImpulseResponse AddBackgroundNoise และ ApplyImpulseResponseShiftsample_rate เป็นทางเลือก อนุญาตให้ระบุ sample_rate ใน __init__ แทนที่จะ forward ซึ่งหมายความว่าการแปลง Torchaudio สามารถใช้ใน Compose ในขณะนี้parameters ของคลาสย่อย nn.ModuleCompose เพื่อใช้การแปลงหลายครั้งfrom_dict และ from_yaml สำหรับการโหลดการกำหนดค่าการเพิ่มข้อมูลจาก dict, json หรือ yamlper_batch และ per_channelPeakNormalizationconvolve ใน APIGain และ PolarityInversionสภาพแวดล้อมการพัฒนาที่เปิดใช้งาน GPU สำหรับคบเพลิงสามารถสร้างได้ด้วย conda:
conda env create pytest
การพัฒนาของคบเพลิง-อคติได้รับการสนับสนุนจาก Nomono
ขอบคุณผู้สนับสนุนทุกคนที่ช่วยปรับปรุงคบเพลิง


