torch audiomentations
v0.11.1

Pytorch의 오디오 데이터 확대. 시청각에서 영감을 얻었습니다.
nn.Module 확장 변환 Pytorch Neural Network 모델의 일부로 통합 될 수 있습니다.per_batch , per_example 및 per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters 및 unfreeze_parameters 사용하십시오.PitchShift 특히 낮은 샘플 속도에 대해 작은 피치 시프트를 지원하지 않습니다 (#151). 해결 방법 : 낮은 샘플 속도에 적용되는 작은 피치 시프트가 필요한 경우, 효율적인 피치 시프트 대상을 계산하기위한 기능없이 시청각에서 피치 시프트를 직접 사용하십시오. 기고자 환영합니다! 소행성의 여유에 가입하여 우리와의 torch-audiomentations 에 대한 논의를 시작하십시오.
우리는 데이터 확대가 모델 교육 속도의 병목 현상이되기를 원하지 않습니다. 다음은 1D Convolution을 실행하는 데 걸리는 시간의 비교입니다.
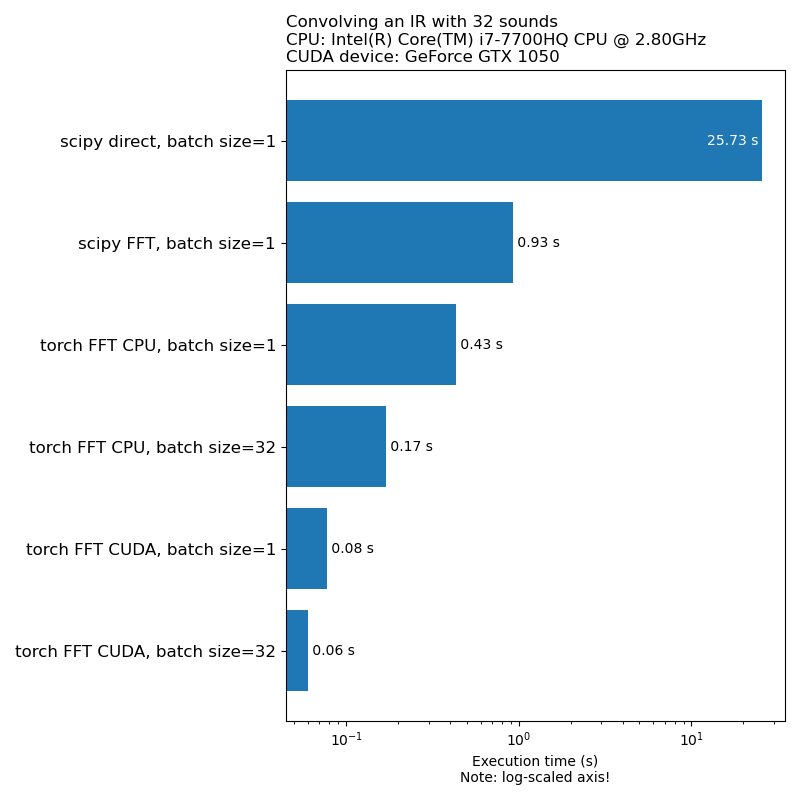
참고 : 모든 변환이 CPU에 비해 인상적인 속도를 갖는 것은 아닙니다. 일반적으로 GPU에서 오디오 데이터 확대를 실행하는 것이 항상 최선의 선택은 아닙니다. 자세한 내용은이 기사를 참조하십시오 : https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
Torch-Audiomentations는 초기 개발 단계에 있으므로 API는 변경 될 수 있습니다.
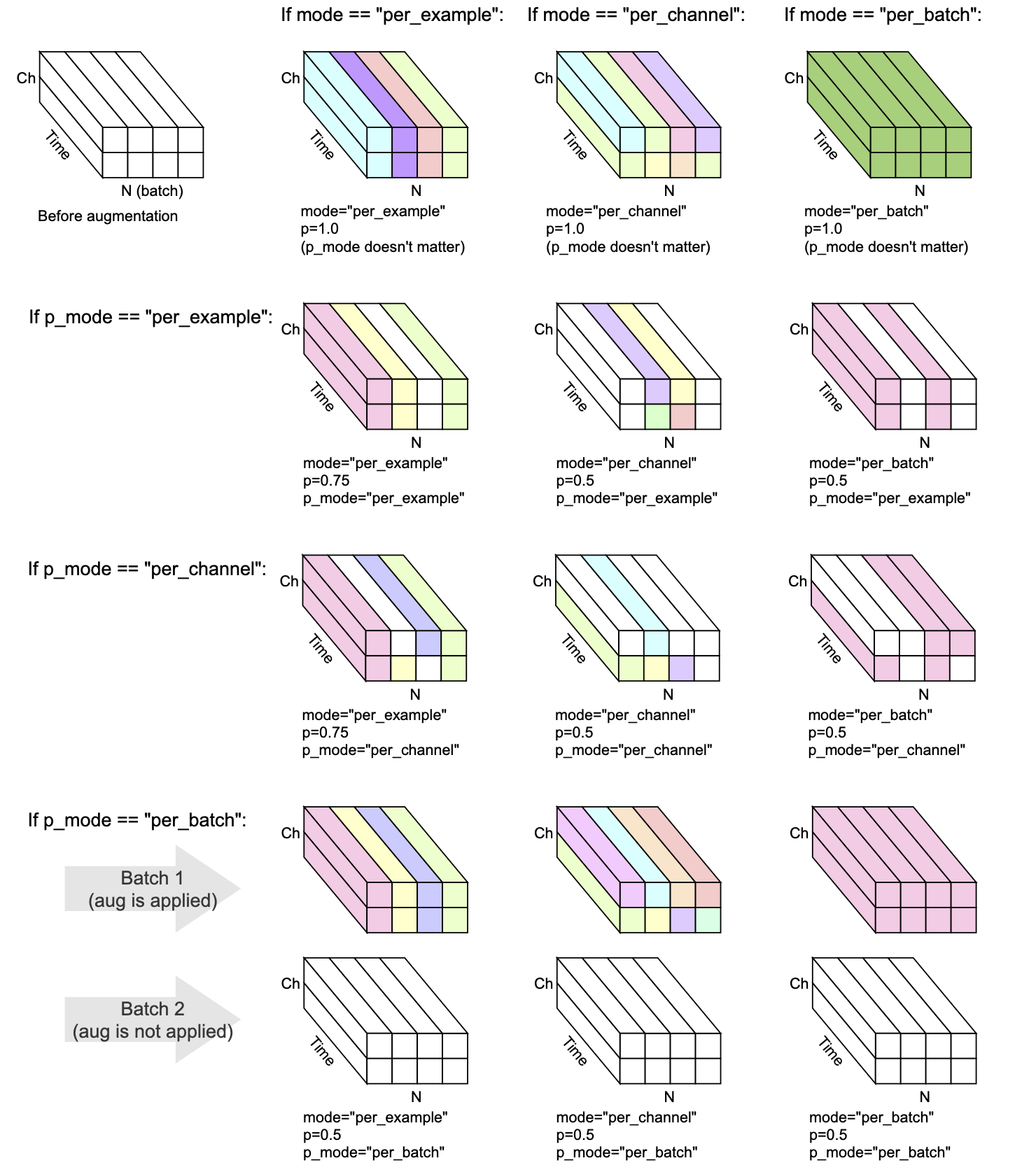
모든 변환에는 mode , p 및 p_mode 가 있습니다 - 증강이 수행되는 방법을 결정하는 매개 변수입니다.
mode 증강의 무작위 화가 어떻게 그룹화되고 적용되는지 결정합니다.p 증강을 적용 할 확률을 결정합니다.p_mode 증강의 온/오프가 어떻게 적용되는지 결정합니다. 이 시각화는 mode 와 p_mode 의 다른 조합이 어떻게 증강을 수행하는지 보여줍니다.
v0.5.0에 추가되었습니다
입력 오디오에 배경 노이즈를 추가하십시오.
V0.7.0에 추가되었습니다
입력 오디오에 컬러 노이즈를 추가하십시오.
v0.5.0에 추가되었습니다
임펄스 응답으로 주어진 오디오를 회복하십시오.
v0.9.0에 추가되었습니다
입력 오디오에 대역 통과 필터링을 적용하십시오.
V0.10.0에 추가되었습니다
밴드 스톱 필터링을 입력 오디오에 적용하십시오. 노치 필터라고도합니다.
V0.1.0에 추가되었습니다
오디오에 임의의 진폭 계수를 곱하여 볼륨을 줄이거 나 늘리십시오. 이 기술은 모델이 입력 오디오의 전반적인 이득에 다소 변하지 않는 데 도움이 될 수 있습니다.
경고 :이 변환은 [-1, 1] 범위 외부의 샘플을 반환 할 수 있으며, 이는 나중에 오디오에서 수행하는 작업에 따라 클리핑 또는 랩 왜곡으로 이어질 수 있습니다. 또한 https://en.wikipedia.org/wiki/cliping_(audio)#digital_clipping을 참조하십시오
V0.8.0에 추가되었습니다
입력 오디오에 고역 통과 필터링을 적용하십시오.
v0.11.0에 추가되었습니다
이 변환은 입력을 변경하지 않습니다. 데이터 확대가 비활성화되어야하는 경우 코드를 단순화하는 데 사용할 수 있습니다.
V0.8.0에 추가되었습니다
입력 오디오에 저역 통과 필터링을 적용하십시오.
v0.2.0에 추가되었습니다
일정한 양의 게인을 적용하여 배치의 각 오디오 스 니펫에 존재하는 가장 높은 신호 레벨이 0dBfs가되도록하십시오. 즉, 모든 샘플이 -1에서 1 사이 여야하는 경우 가장 큰 수준이 허용됩니다.
이 변환에는 대체 모드 (apply_to = "only_too_loud_sounds")가있어 [-1, 1] 범위 외부의 극한 값을 가진 오디오 스 니펫에만 적용됩니다. 이것은 너무 큰 오디오에서 디지털 클리핑을 피하는 데 유용하며 다른 오디오를 손길이 닿지 않습니다.
v0.9.0에 추가되었습니다
피치 시프트는 템포를 바꾸지 않고 위 또는 아래로 소리를냅니다.
V0.1.0에 추가되었습니다
오디오 샘플을 거꾸로 뒤집어 극성을 뒤집습니다. 다시 말해, 파형에 -1을 곱하므로 음수 값에 양수가되고 그 반대도 마찬가지입니다. 결과는 독립적으로 재생 될 때 원본에 비해 동일하게 들립니다. 그러나 다른 오디오 소스와 혼합되면 결과가 다를 수 있습니다. 이 파형 반전 기술은 때때로 오디오 취소에 사용되거나 두 파형 사이의 차이를 얻는 데 사용됩니다. 그러나 오디오 데이터 증강의 맥락 에서이 변환은 단계를 인식 머신 러닝 모델을 교육 할 때 유용 할 수 있습니다.
v0.5.0에 추가되었습니다
롤오버 유무에 관계없이 오디오를 앞으로 또는 뒤로 이동
V0.6.0에 추가되었습니다
멀티 채널 오디오 입력 (예 : 스테레오)이 주어지면 채널을 셔플하십시오. 이 변환은 멀티 채널 파형을 입력하는 머신 러닝 모델의 위치 바이어스를 퇴치하는 데 도움이 될 수 있습니다.
입력 오디오가 모노 인 경우이 변환은 경고를 방출하는 것 외에는 아무것도 수행하지 않습니다.
V0.10.0에 추가되었습니다
시각적 영역에서 이미지의 임의의 플립과 유사한 타임 축을 따라 오디오를 반전 (반전). 이것은 오디오 분류의 맥락에서 관련 될 수 있습니다. 종이 오디오 클립에 성공적으로 적용되었습니다 : 이미지, 텍스트 및 오디오로 클립 확장
Mix , Padding , RandomCrop 및 SpliceOut 추가 LowPassFilter 및 HighPassFilter 에서 일정한 컷오프 주파수에 대한 지원 추가AddColoredNoise 에서 min_f_decay == max_f_decay에 대한 지원을 추가하십시오Shift 에서 수정하십시오UserWarning 피하려면 set_backend 제거하십시오 Identity 추가torch.Tensor 의 대안으로 ObjectDict 출력 유형을 추가하십시오. 이 대안은 현재 (후진 호환성)의 경우 옵트 인이지만 이전 출력 유형 ( torch.Tensor )은 더 이상 사용되지 않으며 향후 버전에서는 지원됩니다.AddBackgroundNoise 및 ApplyImpulseResponse 지정할 수 있습니다.PitchShift 를 지원하기 위해 최신 버전의 torch-pitch-shift 필요합니다.BandPassFilter 작동하지 않은 버그를 수정하십시오 AddBackgroundNoise 에서 Min SNR == Max SNR에 대한 지원 추가AddBackgroundNoise 에서 호환되지 않는 길이로 샘플링되는 버그 수정 OneOf 와 SomeOf 구현합니다.BandStopFilter 및 TimeInversionir_paths transform_parameters에 ApplyImpulseResponse 하여 어떤 충동 응답이 사용되었는지 검사 할 수 있습니다. 이것은 또한 freeze_parameters() 예상되는 동작을 제공합니다.BandPassFilter 에서 예상보다 두 배나 큰 버그를 수정하십시오. 기본값은 그에 따라 업데이트되었습니다. 이전에 min_bandwidth_fraction 및/또는 max_bandwidth_fraction 지정한 경우 이전과 동일한 동작을 얻으려면 해당 숫자를 두 배로 늘려야합니다. ApplyImpulseResponse 에서 매개 변수 compensate_for_propagation_delay 추가하십시오BandPassFilter 를 구현하십시오PitchShift 구현HighPassFilter 및 LowPassFilter 구현하십시오AddColoredNoise 구현하십시오ShuffleChannels 구현하십시오 AddBackgroundNoise 작동하지 않는 버그 수정ApplyImpulseResponse 의 성능을 향상시킵니다. AddBackgroundNoise 및 ApplyImpulseResponse 릴리스합니다Shift 구현하십시오sample_rate 선택 사항을 선택하십시오. forward 대신 __init__ 에서 sample_rate 지정할 수 있습니다. 이것은 Torchaudio 변환이 지금 Compose 에 사용할 수 있음을 의미합니다.nn.Module 서브 클래스의 parameters 메소드를 사용할 수없는 버그 수정Compose 구현하십시오from_dict , JSON 또는 YAML에서 데이터 확대 구성을로드하기 위해 유틸리티 기능을 구현하십시오 from_yamlper_batch 및 per_channel 에 대한 지원을 추가하십시오PeakNormalization 를 구현하십시오convolve 노출하십시오Gain 및 PolarityInversion 전달을 갖는 초기 방출Torch-audiomentations를위한 GPU 지원 개발 환경은 Conda를 사용하여 만들 수 있습니다.
conda env create pytest
토치-오우 디 아미 멘테이션의 발달은 Nomono에 의해 친절하게 뒷받침됩니다.
횃불 오우 디 아미 멘토링을 개선하는 데 도움이되는 모든 기고자들에게 감사합니다.


