torch audiomentations
v0.11.1

Augmentation des données audio dans Pytorch. Inspiré par des audiomentations.
nn.Module , afin qu'ils puissent être intégrés dans le cadre d'un modèle de réseau neuronal pytorchper_batch , per_example et per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters et unfreeze_parameters pour l'instant si les données cibles sont audio avec la même forme que l'entrée.PitchShift ne prend pas en charge les petits changements de hauteur, en particulier pour les faibles taux d'échantillonnage (# 151). Solution: Si vous avez besoin de petits décalages de hauteur appliqués à de faibles fréquences d'échantillonnage, utilisez un pashish de pitch dans des audiomentations ou du décalage de torche directement sans la fonction de calcul des cibles de décalage de hauteur efficaces. Les contributeurs sont les bienvenus! Rejoignez le mou de l'astéroïde pour commencer à torch-audiomentations avec nous.
Nous ne voulons pas que l'augmentation des données soit un goulot d'étranglement dans la vitesse de formation du modèle. Voici une comparaison du temps nécessaire pour exécuter 1D Convolution:
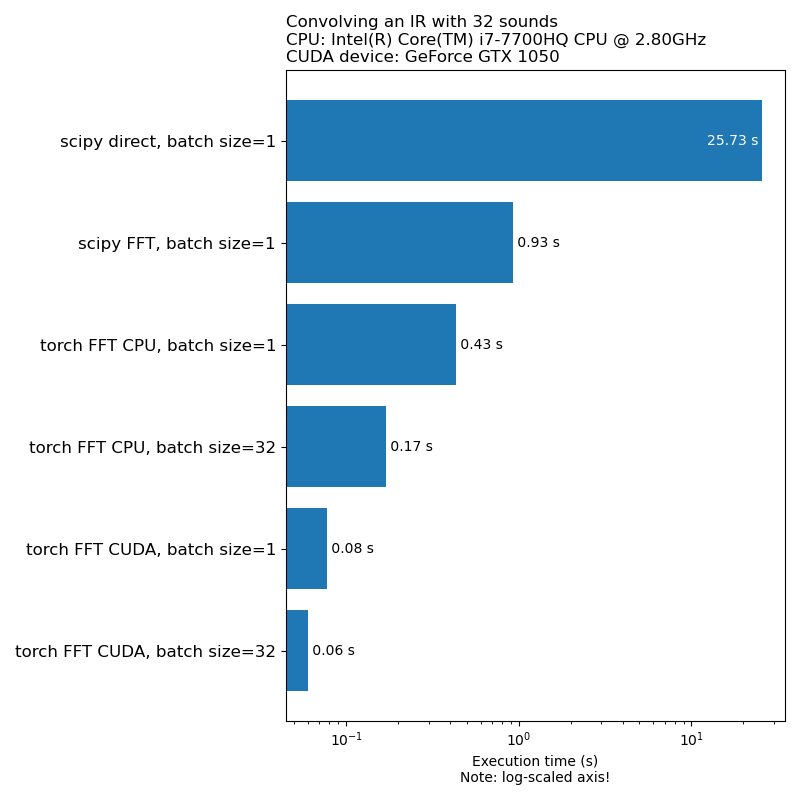
Remarque: Toutes les transformations n'ont pas une accélération aussi impressionnante par rapport au CPU. En général, l'exécution d'augmentation des données audio sur GPU n'est pas toujours la meilleure option. Pour plus d'informations, consultez cet article: https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
Les audiomentations des torch sont à un stade de développement précoce, donc les API sont sujettes à un changement.
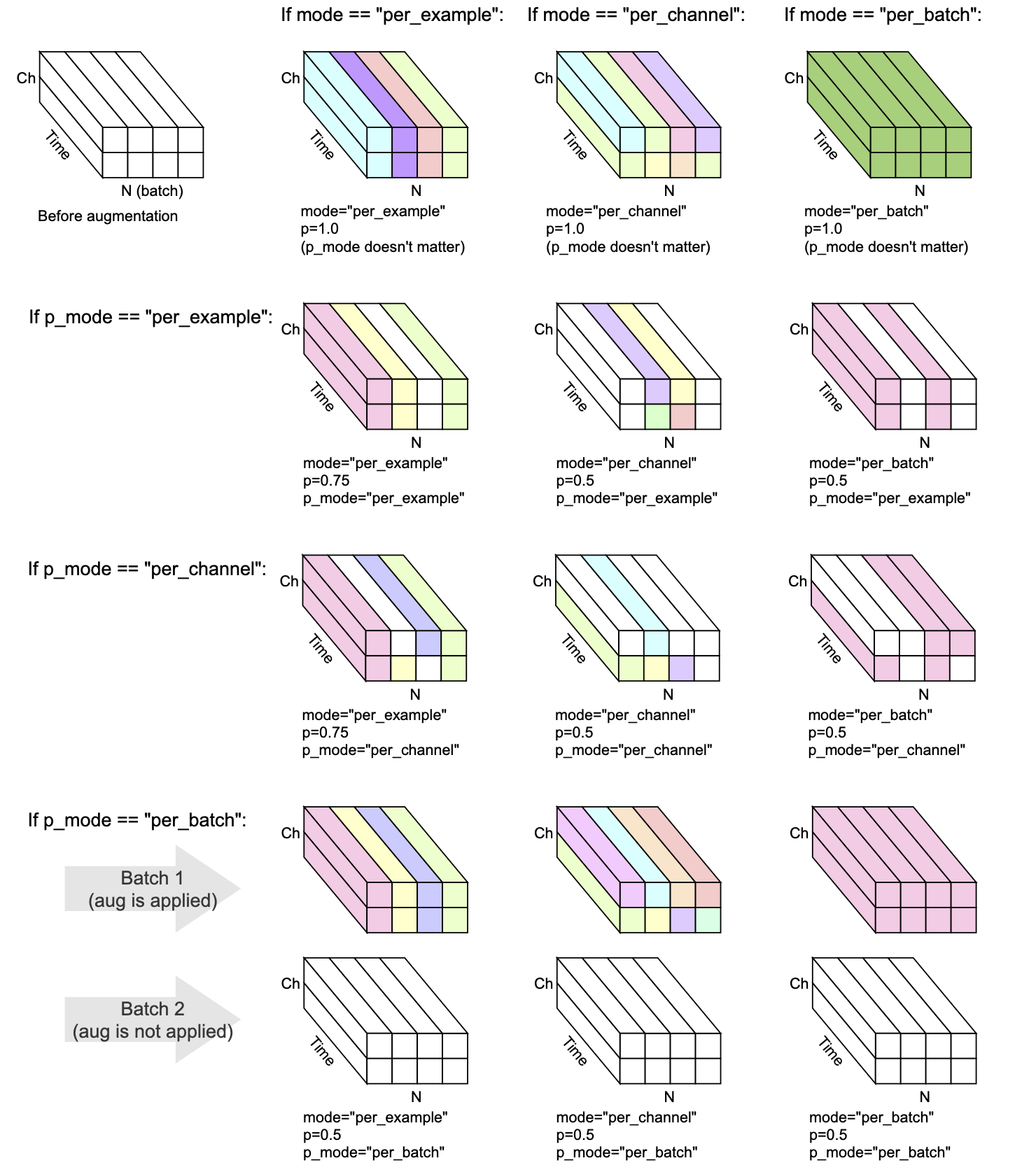
Chaque transformée a mode , p et p_mode - les paramètres qui décident comment l'augmentation est effectuée.
mode décide comment la randomisation de l'augmentation est regroupée et appliquée.p décide de la probabilité de marche / désactivation d'appliquer l'augmentation.p_mode décide comment l'entrée / désactivation de l'augmentation est appliquée. Cette visualisation montre comment différentes combinaisons de mode et p_mode effectueraient une augmentation.
Ajouté dans V0.5.0
Ajoutez un bruit de fond à l'audio d'entrée.
Ajouté dans V0.7.0
Ajouter le bruit coloré à l'audio d'entrée.
Ajouté dans V0.5.0
Convolutionz l'audio donné avec des réponses impulsives.
Ajouté dans V0.9.0
Appliquez un filtrage de passe-bande à l'audio d'entrée.
Ajouté dans v0.10.0
Appliquez un filtrage de bande d'arrêt de bande à l'audio d'entrée. Également connu sous le nom de filtre Notch.
Ajouté dans V0.1.0
Multipliez l'audio par un facteur d'amplitude aléatoire pour réduire ou augmenter le volume. Cette technique peut aider un modèle à devenir quelque peu invariant au gain global de l'audio d'entrée.
AVERTISSEMENT: Cette transformation peut retourner des échantillons à l'extérieur de la gamme [-1, 1], ce qui peut entraîner une déformation ou envelopper la distorsion, selon ce que vous faites avec l'audio à un stade ultérieur. Voir aussi https://en.wikipedia.org/wiki/clipping_(audio)#digital_clipping
Ajouté dans V0.8.0
Appliquez un filtrage passe-haut à l'audio d'entrée.
Ajouté dans v0.11.0
Cette transformation renvoie l'entrée inchangée. Il peut être utilisé pour simplifier le code dans les cas où l'augmentation des données doit être désactivée.
Ajouté dans V0.8.0
Appliquez un filtrage passe-bas à l'audio d'entrée.
Ajouté dans V0.2.0
Appliquez une quantité constante de gain, de sorte que le niveau de signal le plus élevé présent dans chaque extrait audio du lot devient 0 DBFS, c'est-à-dire le niveau le plus fort autorisé si tous les échantillons doivent être compris entre -1 et 1.
Cette transformation a un mode alternatif (appliquer_to = "only_too_loud_sounds") où il ne s'applique qu'aux extraits audio qui ont des valeurs extrêmes en dehors de la plage [-1, 1]. Ceci est utile pour éviter l'écrasement numérique dans l'audio qui est trop fort, tout en laissant un autre audio intact.
Ajouté dans V0.9.0
Le shift de pitch sonne vers le haut ou vers le bas sans changer le tempo.
Ajouté dans V0.1.0
Retournez les échantillons audio à l'envers, inversant leur polarité. En d'autres termes, multiplier la forme d'onde par -1, donc les valeurs négatives deviennent positives, et vice versa. Le résultat sonnera de la même manière par rapport à l'original lorsqu'il est joué de manière isolée. Cependant, lorsqu'il est mélangé avec d'autres sources audio, le résultat peut être différent. Cette technique d'inversion de forme d'onde est parfois utilisée pour l'annulation audio ou l'obtention de la différence entre deux formes d'onde. Cependant, dans le contexte de l'augmentation des données audio, cette transformation peut être utile lors de la formation des modèles d'apprentissage automatique conscients de la phase.
Ajouté dans V0.5.0
Déplacer les avantages audio ou vers l'arrière, avec ou sans renversement
Ajouté dans v0.6.0
Compte tenu de l'entrée audio multicanal (par exemple stéréo), mélanger les canaux, par exemple, la gauche peut devenir à droite et vice versa. Cette transformation peut aider à lutter contre les biais de position dans les modèles d'apprentissage automatique qui saisissent les formes d'onde multicanaux.
Si l'audio d'entrée est mono, cette transformation ne fait rien d'autre que d'émettre un avertissement.
Ajouté dans v0.10.0
Inverser (inverser) L'audio le long de l'axe temporel similaire à la flip aléatoire d'une image dans le domaine visuel. Cela peut être pertinent dans le contexte de la classification audio. Il a été appliqué avec succès dans le papier audioclip: étendant le clip à l'image, au texte et audio
Mix , Padding , RandomCrop et SpliceOut LowPassFilter et HighPassFilterAddColoredNoiseShiftset_backend pour éviter UserWarning de Torchaudio IdentityObjectDict comme alternative à torch.Tensor . Cette alternative est opt-in pour l'instant (pour la compatibilité vers l'arrière), mais notez que l'ancien type de sortie ( torch.Tensor ) est obsolète et que la prise en charge sera supprimée dans une future version.AddBackgroundNoise et ApplyImpulseResponsetorch-pitch-shift pour assurer la prise en charge de Torchaudio 0.11 dans PitchShiftBandPassFilter n'a pas fonctionné sur GPU AddBackgroundNoiseAddBackgroundNoise OneOf et SomeOf pour appliquer un ou plusieurs d'un ensemble donné de transformationsBandStopFilter et TimeInversionir_paths dans Transform_Parameters dans ApplyImpulseResponse afin qu'il soit possible d'inspecter quelles réponses impulsives ont été utilisées. Cela donne également freeze_parameters() le comportement attendu.BandPassFilter . Les valeurs par défaut ont été mises à jour en conséquence. Si vous spécifiiez auparavant min_bandwidth_fraction et / ou max_bandwidth_fraction , vous devez maintenant doubler ces nombres pour obtenir le même comportement qu'auparavant. compensate_for_propagation_delay dans ApplyImpulseResponseBandPassFilterPitchShiftHighPassFilter et LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise n'a pas fonctionné sur CudaApplyImpulseResponse . AddBackgroundNoise et ApplyImpulseResponseShiftsample_rate en option. Autoriser la spécification de sample_rate dans __init__ au lieu de forward . Cela signifie que les transformes de torch audio peuvent être utilisées dans Compose maintenant.parameters de la sous-classe nn.ModuleCompose pour appliquer plusieurs transformationsfrom_dict et from_yaml pour charger des configurations d'augmentation de données de dict, json ou yamlper_batch et per_channelPeakNormalizationconvolve dans l'APIGain et PolarityInversionUn environnement de développement compatible GPU pour les audiomentations de torch peut être créé avec Conda:
conda env create pytest
Le développement des audiomentations torch est aimablement soutenu par Nomono.
Merci à tous les contributeurs qui aident à améliorer les audiomentations des torchs.


