torch audiomentations
v0.11.1

Augmentasi data audio di Pytorch. Terinspirasi oleh audiomentation.
nn.Module , sehingga dapat diintegrasikan sebagai bagian dari model jaringan saraf pytorchper_batch , per_example dan per_channel pip install torch-audiomentations
import torch
from torch_audiomentations import Compose , Gain , PolarityInversion
# Initialize augmentation callable
apply_augmentation = Compose (
transforms = [
Gain (
min_gain_in_db = - 15.0 ,
max_gain_in_db = 5.0 ,
p = 0.5 ,
),
PolarityInversion ( p = 0.5 )
]
)
torch_device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
# Make an example tensor with white noise.
# This tensor represents 8 audio snippets with 2 channels (stereo) and 2 s of 16 kHz audio.
audio_samples = torch . rand ( size = ( 8 , 2 , 32000 ), dtype = torch . float32 , device = torch_device ) - 0.5
# Apply augmentation. This varies the gain and polarity of (some of)
# the audio snippets in the batch independently.
perturbed_audio_samples = apply_augmentation ( audio_samples , sample_rate = 16000 )freeze_parameters dan unfreeze_parameters untuk saat ini jika data target audio dengan bentuk yang sama dengan input.PitchShift tidak mendukung pergeseran pitch kecil, terutama untuk laju sampel rendah (#151). Penanganan masalah: Jika Anda membutuhkan pergeseran pitch kecil yang diterapkan pada laju sampel rendah, gunakan pitchshift di audiomentation atau obor-pitch-shift langsung tanpa fungsi untuk menghitung target pitch-shift yang efisien. Kontributor selamat datang! Bergabunglah dengan Slack Asteroid untuk mulai membahas tentang torch-audiomentations dengan kami.
Kami tidak ingin augmentasi data menjadi hambatan dalam kecepatan pelatihan model. Berikut adalah perbandingan waktu yang diperlukan untuk menjalankan konvolusi 1D:
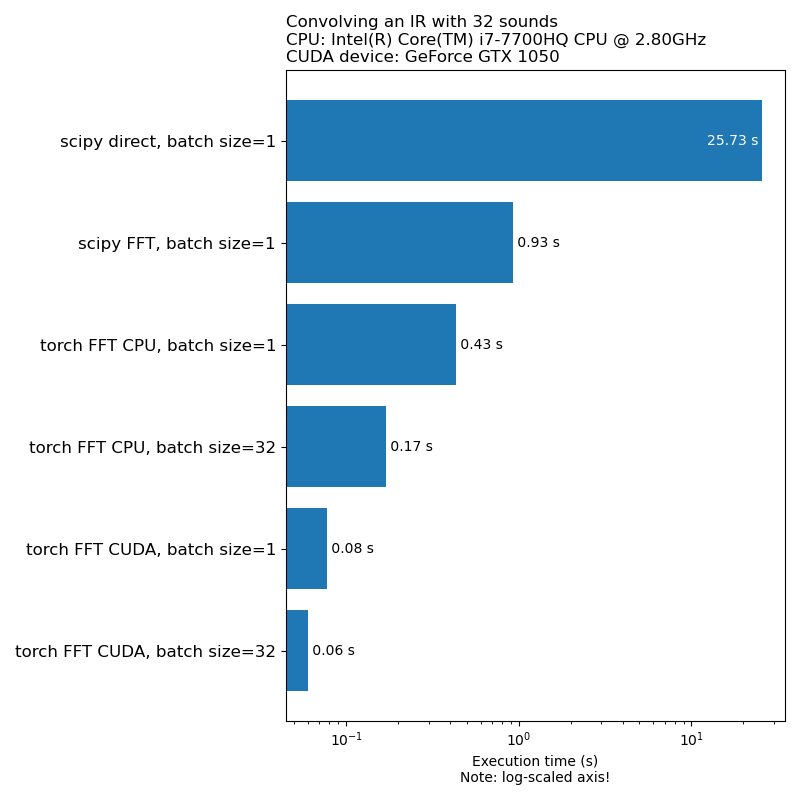
Catatan: Tidak semua transformasi memiliki kecepatan yang mengesankan ini dibandingkan dengan CPU. Secara umum, menjalankan augmentasi data audio pada GPU tidak selalu merupakan pilihan terbaik. Untuk info lebih lanjut, lihat artikel ini: https://iver56.github.io/audiomentations/guides/cpu_vs_gpu/
Obor-audiomentasi berada dalam tahap pengembangan awal, sehingga API dapat berubah.
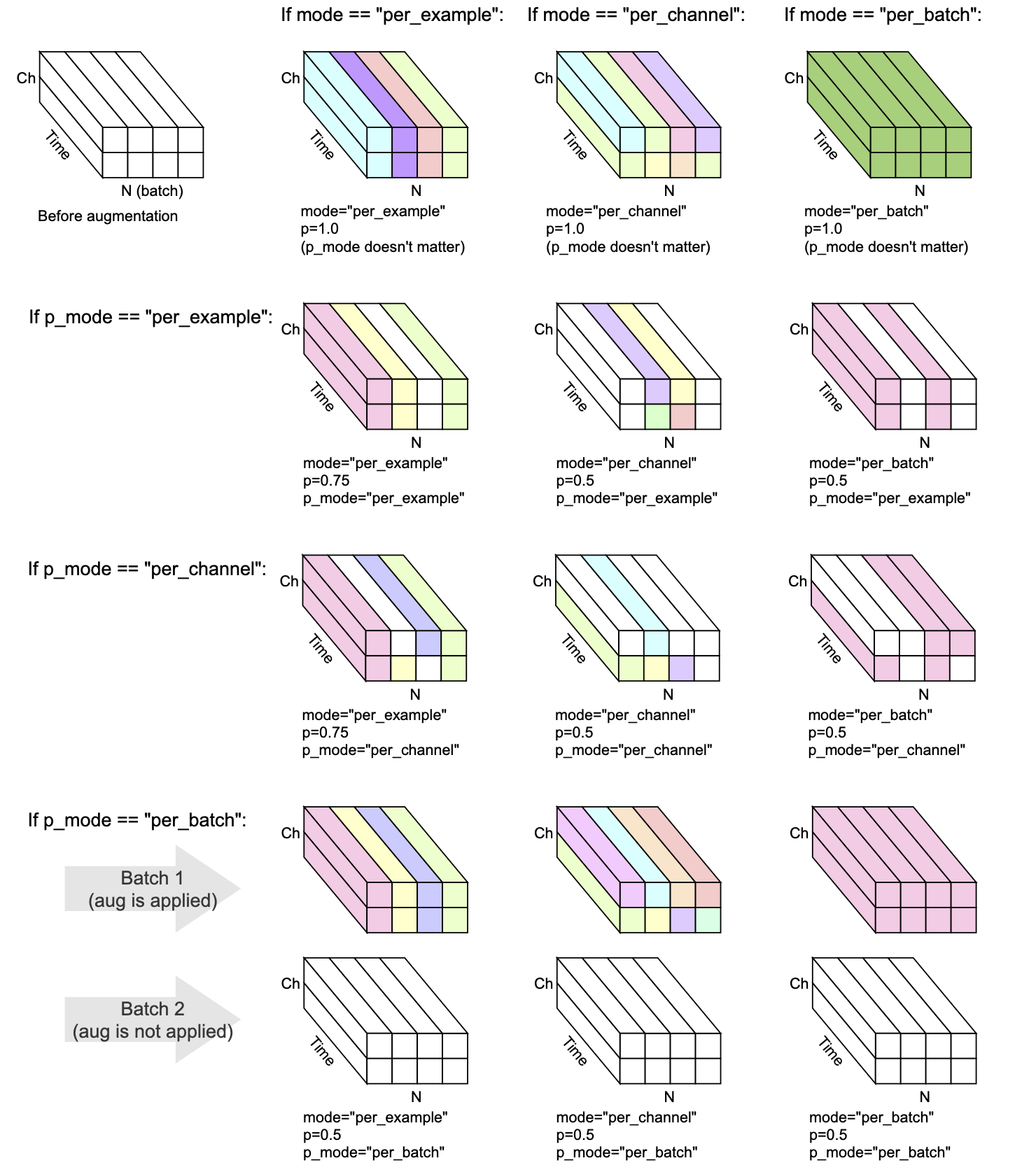
Setiap transformasi memiliki mode , p , dan p_mode - parameter yang memutuskan bagaimana augmentasi dilakukan.
mode memutuskan bagaimana pengacakan augmentasi dikelompokkan dan diterapkan.p memutuskan probabilitas hidup/mati untuk menerapkan augmentasi.p_mode memutuskan bagaimana on/off augmentasi diterapkan. Visualisasi ini menunjukkan bagaimana berbagai kombinasi mode dan p_mode akan melakukan augmentasi.
Ditambahkan dalam v0.5.0
Tambahkan latar belakang noise ke audio input.
Ditambahkan dalam v0.7.0
Tambahkan noise berwarna ke audio input.
Ditambahkan dalam v0.5.0
Convolve audio yang diberikan dengan tanggapan impuls.
Ditambahkan dalam v0.9.0
Terapkan penyaringan band-pass ke audio input.
Ditambahkan dalam v0.10.0
Terapkan penyaringan band-stop ke audio input. Juga dikenal sebagai Notch Filter.
Ditambahkan dalam V0.1.0
Lipat gandakan audio dengan faktor amplitudo acak untuk mengurangi atau meningkatkan volume. Teknik ini dapat membantu model menjadi agak invarian dengan gain keseluruhan dari audio input.
Peringatan: Transformasi ini dapat mengembalikan sampel di luar kisaran [-1, 1], yang dapat menyebabkan kliping atau membungkus distorsi, tergantung pada apa yang Anda lakukan dengan audio pada tahap selanjutnya. Lihat juga https://en.wikipedia.org/wiki/clipping_(Audio)#digital_clipping
Ditambahkan dalam V0.8.0
Terapkan penyaringan high-pass ke audio input.
Ditambahkan dalam V0.11.0
Transformasi ini mengembalikan input yang tidak berubah. Ini dapat digunakan untuk menyederhanakan kode dalam kasus di mana augmentasi data harus dinonaktifkan.
Ditambahkan dalam V0.8.0
Terapkan penyaringan low-pass ke audio input.
Ditambahkan dalam V0.2.0
Oleskan jumlah gain yang konstan, sehingga level sinyal tertinggi yang ada di setiap cuplikan audio dalam batch menjadi 0 dBfs, yaitu level paling keras yang diizinkan jika semua sampel harus antara -1 dan 1.
Transformasi ini memiliki mode alternatif (apply_to = "hanya_too_loud_sounds") di mana hanya berlaku untuk cuplikan audio yang memiliki nilai ekstrem di luar kisaran [-1, 1]. Ini berguna untuk menghindari kliping digital dalam audio yang terlalu keras, sambil meninggalkan audio lain yang tidak tersentuh.
Ditambahkan dalam v0.9.0
Pitch-shift terdengar naik atau turun tanpa mengubah tempo.
Ditambahkan dalam V0.1.0
Balikkan sampel audio terbalik, membalikkan polaritas mereka. Dengan kata lain, kalikan bentuk gelombang dengan -1, sehingga nilai -nilai negatif menjadi positif, dan sebaliknya. Hasilnya akan terdengar sama dibandingkan dengan aslinya saat diputar kembali secara terpisah. Namun, ketika dicampur dengan sumber audio lainnya, hasilnya mungkin berbeda. Teknik inversi bentuk gelombang ini kadang -kadang digunakan untuk pembatalan audio atau mendapatkan perbedaan antara dua bentuk gelombang. Namun, dalam konteks augmentasi data audio, transformasi ini dapat bermanfaat saat pelatihan model pembelajaran mesin yang sadar fase.
Ditambahkan dalam v0.5.0
Geser audio ke depan atau ke belakang, dengan atau tanpa rollover
Ditambahkan dalam v0.6.0
Mengingat MultiChannel Audio Input (misalnya stereo), kocok saluran, misalnya sehingga kiri bisa menjadi benar dan sebaliknya. Transformasi ini dapat membantu memerangi bias posisi dalam model pembelajaran mesin yang memasukkan bentuk gelombang multichannel.
Jika audio input adalah mono, transformasi ini tidak melakukan apa pun kecuali memancarkan peringatan.
Ditambahkan dalam v0.10.0
Membalikkan (membalik) audio sepanjang sumbu waktu mirip dengan flip acak gambar dalam domain visual. Ini bisa relevan dalam konteks klasifikasi audio. Itu berhasil diterapkan di kertas audioclip: memperluas klip ke gambar, teks, dan audio
Mix , Padding , RandomCrop dan SpliceOut LowPassFilter dan HighPassFilterAddColoredNoiseShiftset_backend untuk menghindari UserWarning dari Torchaudio IdentityObjectDict sebagai alternatif untuk torch.Tensor . Alternatif ini adalah opt-in untuk saat ini (untuk kompatibilitas ke belakang), tetapi perhatikan bahwa tipe output lama ( torch.Tensor ) sudah usang dan dukungan untuk itu akan dihapus dalam versi mendatang.AddBackgroundNoise dan ApplyImpulseResponsetorch-pitch-shift untuk memastikan dukungan untuk Torchaudio 0,11 di PitchShiftBandPassFilter tidak bekerja pada GPU AddBackgroundNoiseAddBackgroundNoise OneOf dan SomeOf untuk menerapkan satu atau lebih dari set transformasi yang diberikanBandStopFilter dan TimeInversionir_paths di transform_parameters di ApplyImpulseResponse sehingga dimungkinkan untuk memeriksa respons impuls apa yang digunakan. Ini juga memberi freeze_parameters() perilaku yang diharapkan.BandPassFilter . Nilai default telah diperbarui sesuai. Jika Anda sebelumnya menentukan min_bandwidth_fraction dan/atau max_bandwidth_fraction , Anda sekarang perlu menggandakan angka -angka itu untuk mendapatkan perilaku yang sama seperti sebelumnya. compensate_for_propagation_delay di ApplyImpulseResponseBandPassFilterPitchShiftHighPassFilter dan LowPassFilterAddColoredNoiseShuffleChannels AddBackgroundNoise tidak bekerja di cudaApplyImpulseResponse . AddBackgroundNoise dan ApplyImpulseResponseShiftsample_rate opsional. Izinkan menentukan sample_rate di __init__ bukan forward . Ini berarti transformasi Torchaudio dapat digunakan dalam Compose sekarang.parameters dari subkelas nn.ModuleCompose untuk Menerapkan beberapa Transformasifrom_dict dan from_yaml untuk memuat konfigurasi augmentasi data dari DICT, JSON atau YAMLper_batch dan per_channelPeakNormalizationconvolve di APIGain dan PolarityInversionLingkungan pengembangan yang diaktifkan GPU untuk Audiomentation Torch dapat dibuat dengan Conda:
conda env create pytest
Pengembangan obor-audiomentation didukung oleh Nomono.
Terima kasih kepada semua kontributor yang membantu meningkatkan Audiomentation Torch.


