imbalanced dataset sampler
v0.1.2
在許多機器學習應用程序中,我們經常會遇到與其他類型相比,可能看到某些類型的數據的數據集。以稀有疾病的鑑定,可能比疾病樣本更正常。在這些情況下,我們需要確保訓練有素的模型不會偏向具有更多數據的類。例如,考慮一個數據集,其中有5個疾病圖像和20個正常圖像。如果該模型預測所有圖像是正常的,則其精度為80%,此類模型的F1得分為0.88。因此,該模型具有偏向“正常”類別的高趨勢。
為了解決這個問題,廣泛採用的技術稱為重採樣。它包括從多數類(不足下採樣)中刪除樣本和 /或添加更多少數族裔類(過度採樣)的示例。儘管有平衡課程的優勢,但這些技術也有弱點(沒有免費午餐)。過度採樣的最簡單實現是複制少數族裔類的隨機記錄,這可能會導致過度擬合。在抽樣範圍內,最簡單的技術涉及從多數類中刪除隨機記錄,這可能會導致信息丟失。
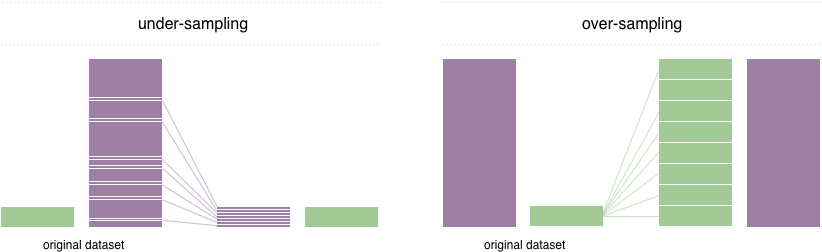
在此存儲庫中,我們實現了一個易於使用的Pytorch採樣器ImbalancedDatasetSampler
對於簡單的開始,通過以下方式安裝軟件包:
pip install torchsampler創建DataLoader時,只需將ImbalancedDatasetSampler datasetsempler傳遞給參數sampler即可。例如:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)然後,在每個時期內,裝載機將對整個數據集進行採樣,並將樣品倒數地稱為班級的概率。
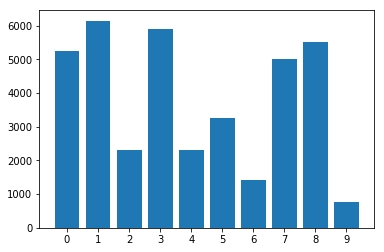
在數據集中的類別分佈:
使用不平衡的數據集採樣器:
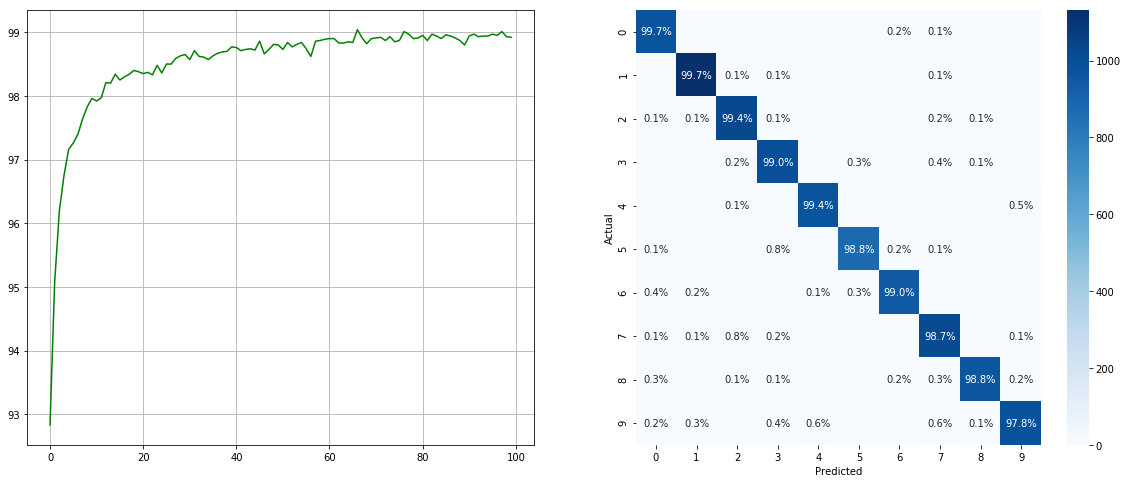 (左:每個時期的測試ACC;右:混淆矩陣)
(左:每個時期的測試ACC;右:混淆矩陣)
沒有不平衡的數據集採樣器:
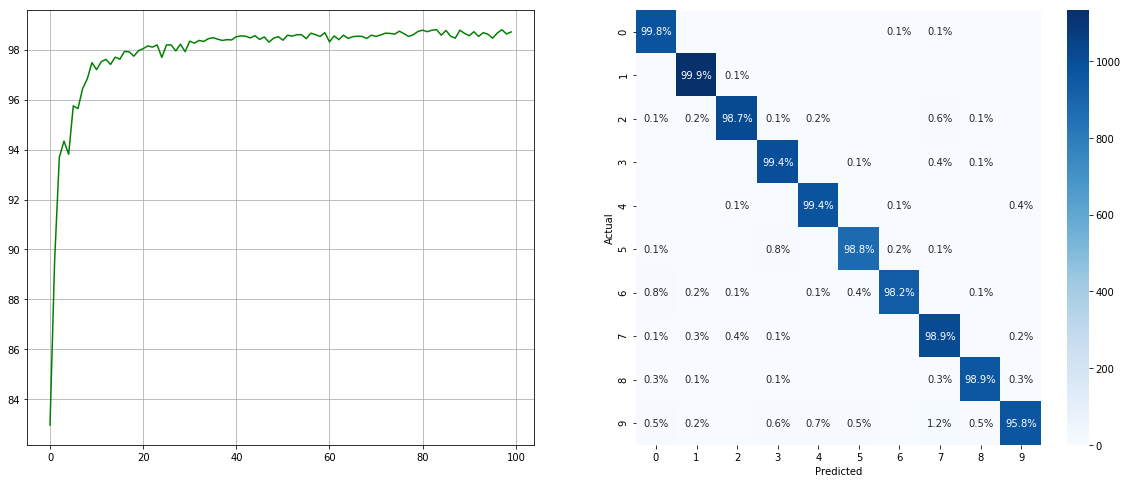 (左:每個時期的測試ACC;右:混淆矩陣)
(左:每個時期的測試ACC;右:混淆矩陣)
請注意,諸如2 6 9類的次要類別有顯著改善,而其他類別的準確性則保留了。
我們感謝所有貢獻。如果您打算貢獻較小的錯誤,請這樣做,而無需進行任何進一步的討論。如果您打算貢獻新功能,實用程序功能或擴展名,請首先打開問題並與我們討論該功能。
麻省理工學院許可。


