imbalanced dataset sampler
v0.1.2
많은 기계 학습 응용 프로그램에서, 우리는 종종 일부 유형의 데이터가 다른 유형보다 더 많이 볼 수있는 데이터 세트를 발견합니다. 예를 들어, 희귀 질병을 식별하십시오. 예를 들어, 질병보다 더 정상적인 샘플이있을 수 있습니다. 이 경우, 우리는 훈련 된 모델이 더 많은 데이터가있는 클래스에 편향되어 있지 않도록해야합니다. 예를 들어, 5 개의 질병 이미지와 20 개의 정상 이미지가있는 데이터 세트를 고려하십시오. 모델이 모든 이미지를 정상으로 예측하면 정확도는 80%이며 이러한 모델의 F1 점수는 0.88입니다. 따라서이 모델은 '정상적인'클래스로 편향되는 경향이 높습니다.
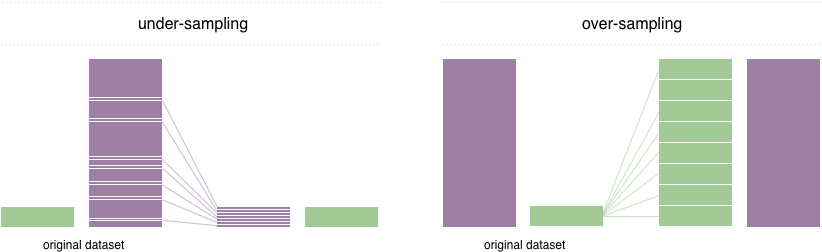
이 문제를 해결하기 위해 널리 채택 된 기술을 리샘플링이라고합니다. 다수 클래스에서 샘플을 제거하고 (아래 샘플링) 소수 클래스 (오버 샘플링)에서 더 많은 예제를 추가하는 것으로 구성됩니다. 수업 균형의 장점에도 불구하고 이러한 기술에는 약점이 있습니다 (무료 점심은 없습니다). 오버 샘플링의 가장 간단한 구현은 소수 클래스에서 임의 레코드를 복제하는 것입니다. 언더 샘플링에서 가장 간단한 기술은 대다수 클래스에서 임의의 레코드를 제거하여 정보 손실을 유발할 수 있습니다.
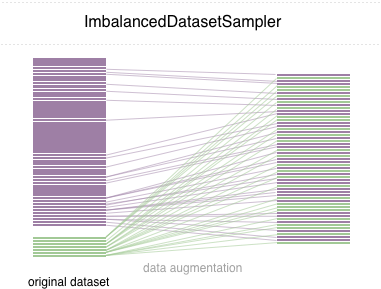
이 repo에서 우리는 사용하기 쉬운 pytorch 샘플러 ImbalancedDatasetSampler 구현할 수 있습니다.
간단한 시작을 위해 다음 방법 중 하나를 통해 패키지를 설치하십시오.
pip install torchsampler DataLoader 생성 할 때 매개 변수 sampler 에 대한 ImbalancedDatasetSampler DatasetSampler를 전달하기 만하면됩니다. 예를 들어:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)그런 다음 각 시대에 로더는 전체 데이터 세트를 샘플링하고 샘플을 클래스에 반비례하여 보이는 확률에 반비례합니다.
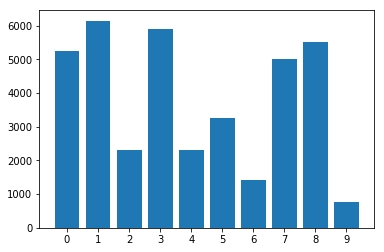
불균형 데이터 세트의 클래스 분포 :
불균형 데이터 세트 샘플러 :
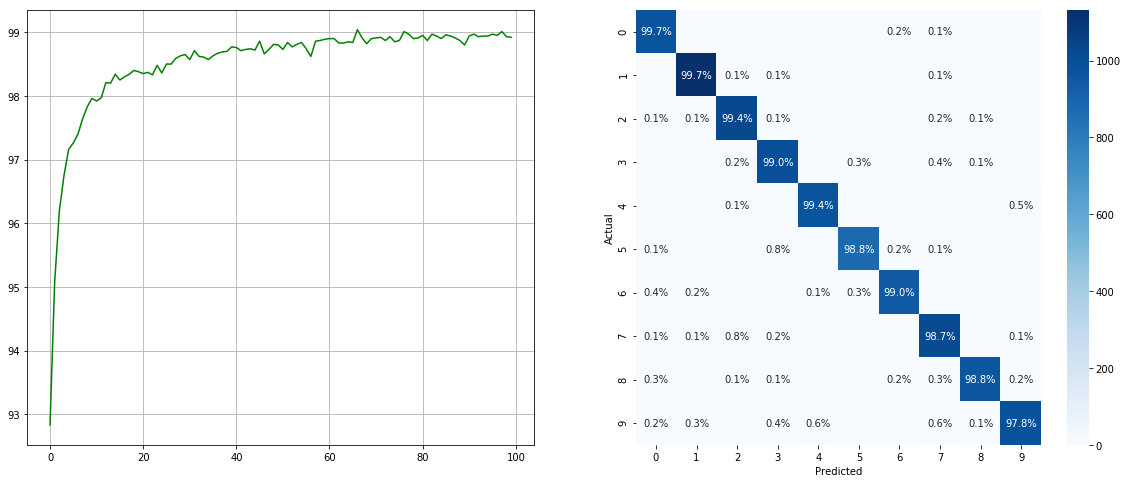 (왼쪽 : 각 시대에서 ACC를 테스트하십시오; 오른쪽 : 혼란 매트릭스)
(왼쪽 : 각 시대에서 ACC를 테스트하십시오; 오른쪽 : 혼란 매트릭스)
불균형 데이터 세트 샘플러없이 :
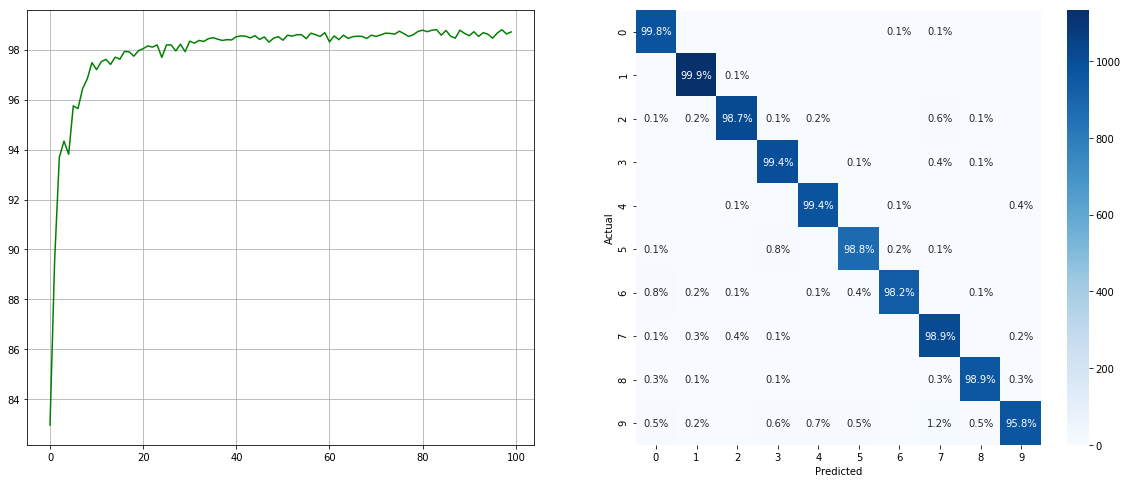 (왼쪽 : 각 시대에서 ACC를 테스트하십시오; 오른쪽 : 혼란 매트릭스)
(왼쪽 : 각 시대에서 ACC를 테스트하십시오; 오른쪽 : 혼란 매트릭스)
2 6 9 와 같은 작은 클래스의 경우 상당한 개선이 있으며 다른 클래스의 정확도는 보존됩니다.
우리는 모든 기여에 감사드립니다. 버그 고정을 다시 기여할 계획이라면 더 이상의 토론없이 그렇게하십시오. 새로운 기능, 유틸리티 기능 또는 확장 기능을 제공 할 계획이라면 먼저 문제를 열고 기능을 논의하십시오.
MIT 라이센스.


