imbalanced dataset sampler
v0.1.2
Em muitos aplicativos de aprendizado de máquina, geralmente encontramos conjuntos de dados, onde alguns tipos de dados podem ser vistos mais do que outros tipos. Tomar identificação de doenças raras, por exemplo, provavelmente existem amostras mais normais do que as doenças. Nesses casos, precisamos garantir que o modelo treinado não seja tendencioso em relação à classe que possui mais dados. Como exemplo, considere um conjunto de dados em que existem 5 imagens de doença e 20 imagens normais. Se o modelo prevê que todas as imagens sejam normais, sua precisão é de 80%e a escore F1 desse modelo é de 0,88. Portanto, o modelo tem alta tendência a ser tendencioso em direção à classe "normal".
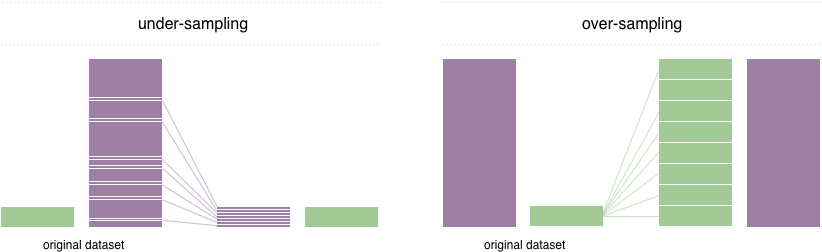
Para resolver esse problema, uma técnica amplamente adotada é chamada de reamostragem. Consiste em remover amostras da classe majoritária (sub-amostragem) e / ou adicionar mais exemplos da classe minoritária (amostragem excessiva). Apesar da vantagem de equilibrar as aulas, essas técnicas também têm suas fraquezas (não há almoço grátis). A implementação mais simples da amostragem excessiva é duplicar registros aleatórios da classe minoritária, que pode causar excesso de ajuste. Na sub-amostragem, a técnica mais simples envolve a remoção de registros aleatórios da classe majoritária, o que pode causar perda de informações.
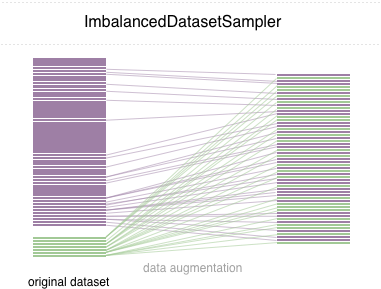
Neste repositório, implementamos um sampler pytorch fácil de usar ImbalancedDatasetSampler
Para começar simples, instale o pacote por meio de uma das seguintes maneiras:
pip install torchsampler Simplesmente passe um ImbalancedDatasetSampler para o sampler de parâmetros ao criar um DataLoader . Por exemplo:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)Em cada época, o carregador provará todo o conjunto de dados e pesará suas amostras inversamente para a sua classe que aparece a probabilidade.
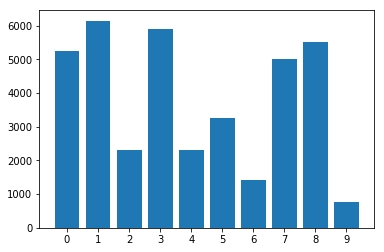
Distribuição de classes no conjunto de dados desequilibrado:
Com amostrador desequilibrado do conjunto de dados:
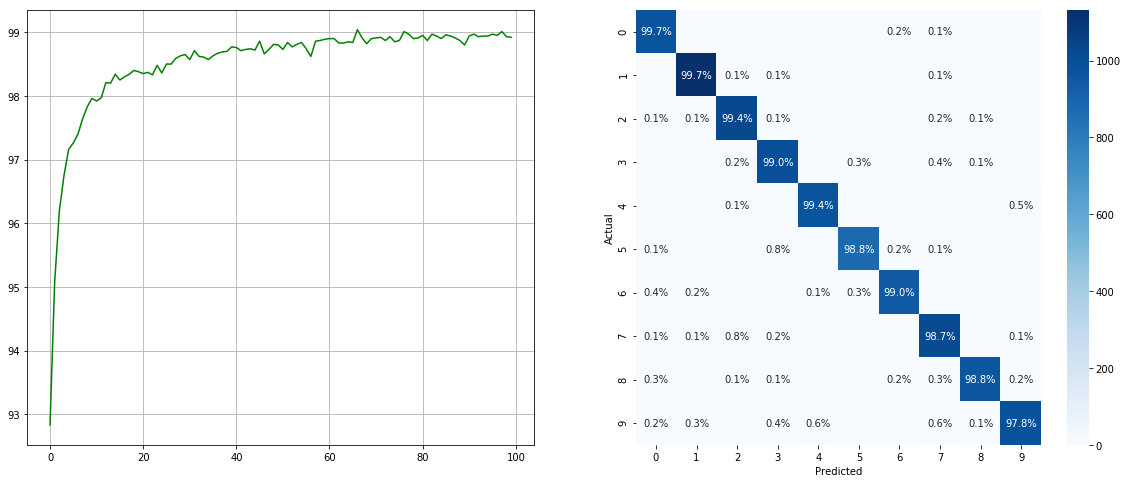 (Esquerda: teste ACC em cada época; direita: matriz de confusão)
(Esquerda: teste ACC em cada época; direita: matriz de confusão)
Sem amostrador de conjunto de dados desequilibrado:
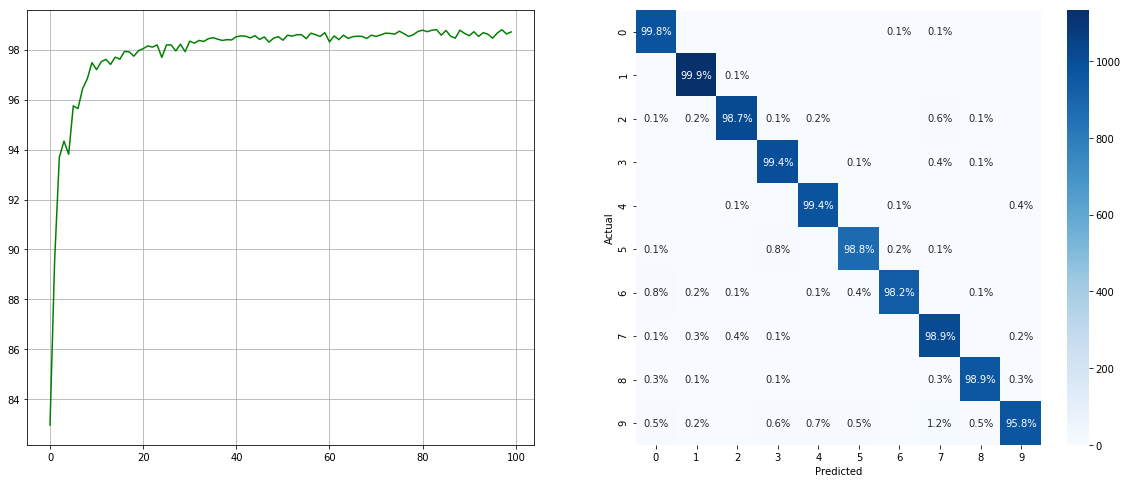 (Esquerda: teste ACC em cada época; direita: matriz de confusão)
(Esquerda: teste ACC em cada época; direita: matriz de confusão)
Observe que existem melhorias significativas para classes menores, como 2 6 9 , enquanto a precisão das outras classes é preservada.
Agradecemos todas as contribuições. Se você planeja contribuir com fixos de bug, faça-o sem nenhuma discussão adicional. Se você planeja contribuir com novos recursos, funções ou extensões de utilitário, primeiro abra um problema e discuta o recurso conosco.
MIT licenciado.


