imbalanced dataset sampler
v0.1.2
在许多机器学习应用程序中,我们经常会遇到与其他类型相比,可能看到某些类型的数据的数据集。以稀有疾病的鉴定,可能比疾病样本更正常。在这些情况下,我们需要确保训练有素的模型不会偏向具有更多数据的类。例如,考虑一个数据集,其中有5个疾病图像和20个正常图像。如果该模型预测所有图像是正常的,则其精度为80%,此类模型的F1得分为0.88。因此,该模型具有偏向“正常”类别的高趋势。
为了解决这个问题,广泛采用的技术称为重采样。它包括从多数类(不足下采样)中删除样本和 /或添加更多少数族裔类(过度采样)的示例。尽管有平衡课程的优势,但这些技术也有弱点(没有免费午餐)。过度采样的最简单实现是复制少数族裔类的随机记录,这可能会导致过度拟合。在抽样范围内,最简单的技术涉及从多数类中删除随机记录,这可能会导致信息丢失。
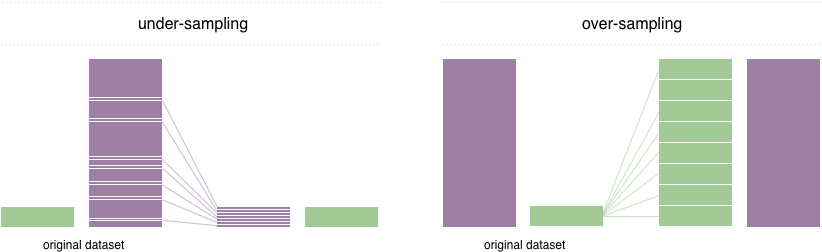
在此存储库中,我们实现了一个易于使用的Pytorch采样器ImbalancedDatasetSampler
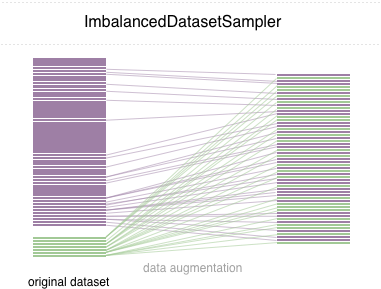
对于简单的开始,通过以下方式安装软件包:
pip install torchsampler创建DataLoader时,只需将ImbalancedDatasetSampler datasetsempler传递给参数sampler即可。例如:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)然后,在每个时期内,装载机将对整个数据集进行采样,并将样品倒数地称为班级的概率。
在数据集中的类别分布:
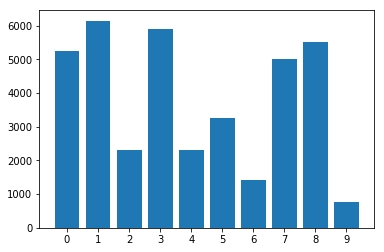
使用不平衡的数据集采样器:
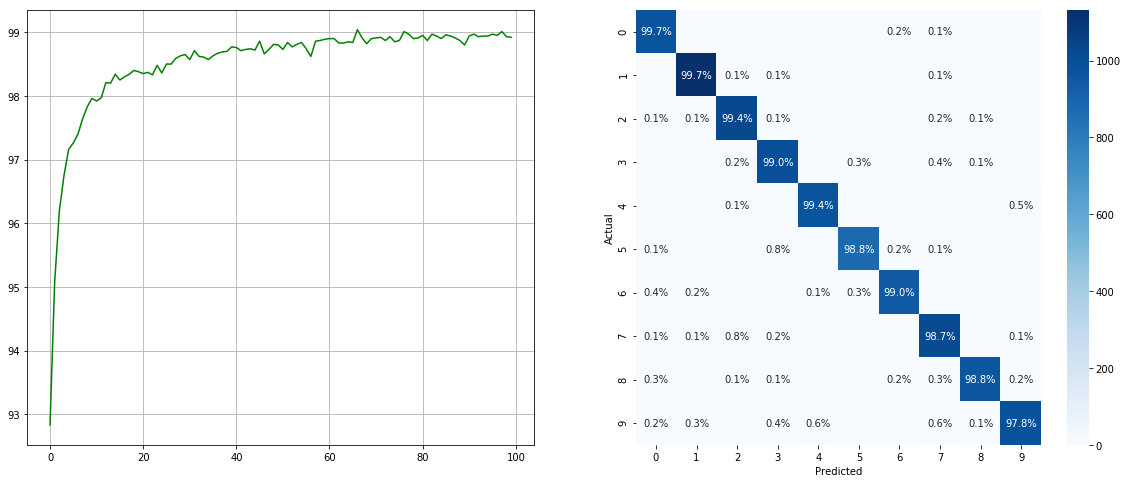 (左:每个时期的测试ACC;右:混淆矩阵)
(左:每个时期的测试ACC;右:混淆矩阵)
没有不平衡的数据集采样器:
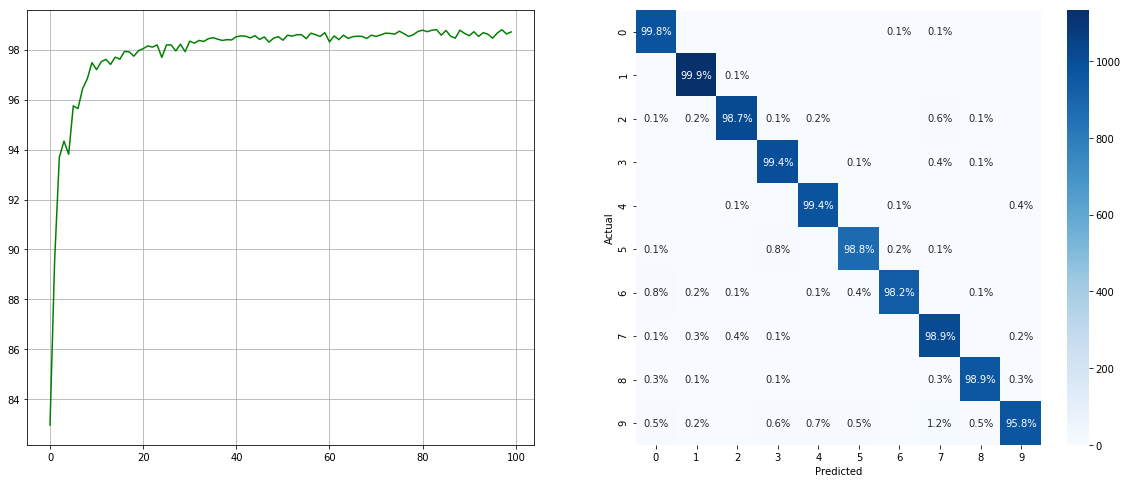 (左:每个时期的测试ACC;右:混淆矩阵)
(左:每个时期的测试ACC;右:混淆矩阵)
请注意,诸如2 6 9类的次要类别有显着改善,而其他类别的准确性则保留了。
我们感谢所有贡献。如果您打算贡献较小的错误,请这样做,而无需进行任何进一步的讨论。如果您打算贡献新功能,实用程序功能或扩展名,请首先打开问题并与我们讨论该功能。
麻省理工学院许可。


