imbalanced dataset sampler
v0.1.2
Dans de nombreuses applications d'apprentissage automatique, nous rencontrons souvent des ensembles de données où certains types de données peuvent être vus plus que d'autres types. Prenez l'identification de maladies rares par exemple, il y a probablement plus d'échantillons normaux que les échantillons de maladie. Dans ces cas, nous devons nous assurer que le modèle formé n'est pas biaisé vers la classe qui a plus de données. Par exemple, considérons un ensemble de données où il y a 5 images de maladie et 20 images normales. Si le modèle prédit que toutes les images sont normales, sa précision est de 80% et le score F1 d'un tel modèle est de 0,88. Par conséquent, le modèle a une forte tendance à être biaisé vers la classe «normale».
Pour résoudre ce problème, une technique largement adoptée est appelée rééchantillonnage. Il consiste à éliminer les échantillons de la classe majoritaire (sous-échantillonnage) et / ou à ajouter plus d'exemples de la classe minoritaire (sur-échantillonnage). Malgré l'avantage d'équilibrer les cours, ces techniques ont également leurs faiblesses (il n'y a pas de déjeuner gratuit). La mise en œuvre la plus simple du sur-échantillonnage consiste à dupliquer des enregistrements aléatoires de la classe minoritaire, ce qui peut provoquer un sur-ajustement. En sous-échantillonnage, la technique la plus simple consiste à supprimer des enregistrements aléatoires de la classe majoritaire, ce qui peut entraîner une perte d'informations.
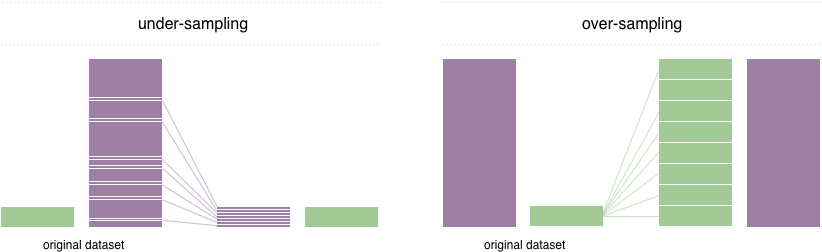
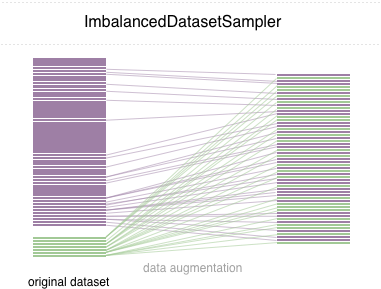
Dans ce dépôt, nous mettons en œuvre un ImbalancedDatasetSampler d'échantillonneur pytorch facile à utiliser
Pour un simple démarrage, installez le package via l'une des façons suivantes:
pip install torchsampler Passez simplement un ImbalancedDatasetSampler pour l' sampler des paramètres lors de la création d'un DataLoader . Par exemple:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)Ensuite, dans chaque époque, le chargeur dégustera l'intégralité de l'ensemble de données et évaluera inversement vos échantillons à votre classe d'apparition.
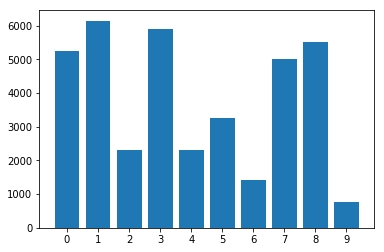
Distribution des classes dans l'ensemble de données déséquilibré:
Avec échantillonneur de jeu de données déséquilibré:
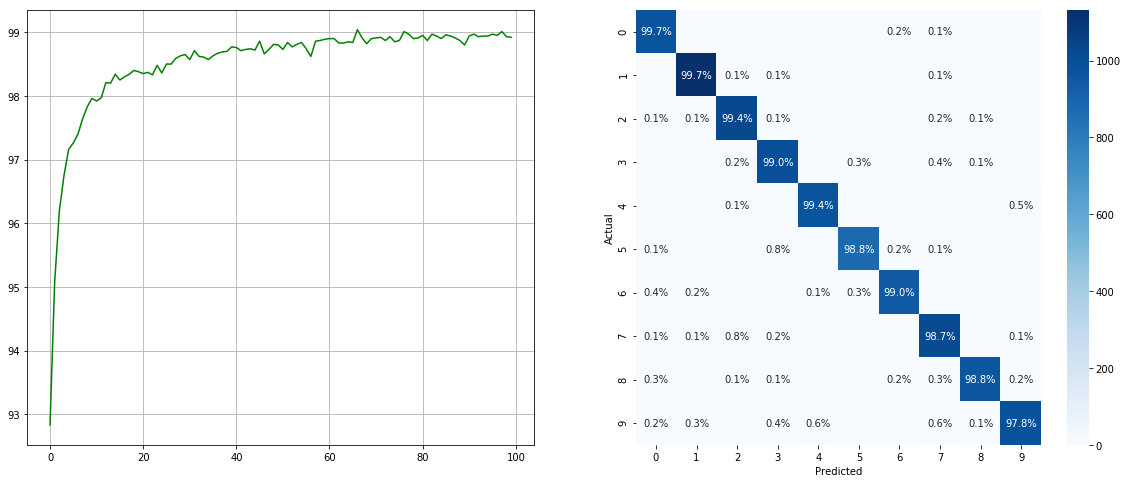 (Gauche: Test ACC dans chaque époque; Droite: Matrice de confusion)
(Gauche: Test ACC dans chaque époque; Droite: Matrice de confusion)
Sans échantillonneur de jeu de données déséquilibré:
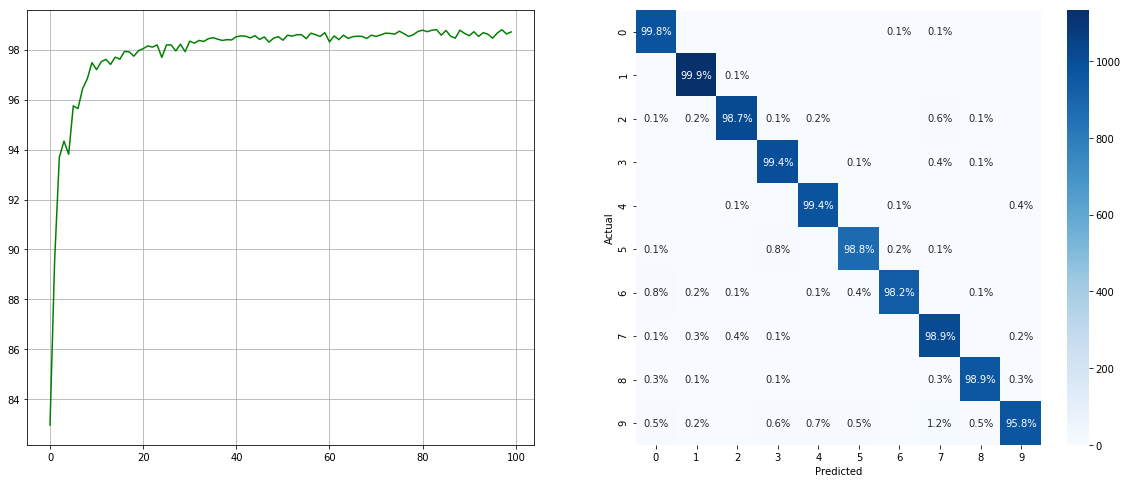 (Gauche: Test ACC dans chaque époque; Droite: Matrice de confusion)
(Gauche: Test ACC dans chaque époque; Droite: Matrice de confusion)
Notez qu'il existe des améliorations significatives pour les classes mineures telles que 2 6 9 , tandis que la précision des autres classes est préservée.
Nous apprécions toutes les contributions. Si vous prévoyez de contribuer aux fixations de bogues, veuillez le faire sans aucune discussion. Si vous prévoyez de contribuer de nouvelles fonctionnalités, fonctions utilitaires ou extensions, veuillez d'abord ouvrir un problème et discuter de la fonctionnalité avec nous.
MIT sous licence.


