imbalanced dataset sampler
v0.1.2
Dalam banyak aplikasi pembelajaran mesin, kami sering menemukan dataset di mana beberapa jenis data dapat dilihat lebih dari jenis lain. Ambil identifikasi penyakit langka misalnya, mungkin ada sampel yang lebih normal daripada penyakit. Dalam kasus ini, kita perlu memastikan bahwa model terlatih tidak bias terhadap kelas yang memiliki lebih banyak data. Sebagai contoh, pertimbangkan dataset di mana ada 5 gambar penyakit dan 20 gambar normal. Jika model memprediksi semua gambar menjadi normal, akurasinya adalah 80%, dan skor F1 dari model tersebut adalah 0,88. Oleh karena itu, model memiliki kecenderungan tinggi untuk bias terhadap kelas 'normal'.
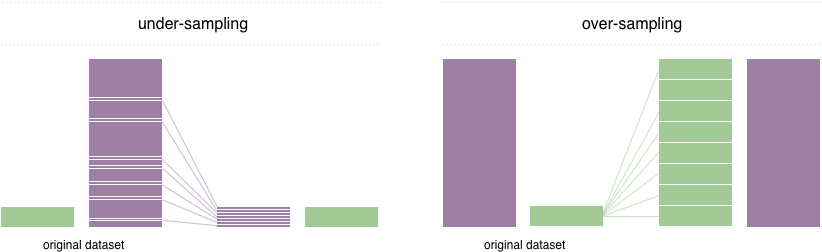
Untuk mengatasi masalah ini, teknik yang diadopsi secara luas disebut resampling. Ini terdiri dari menghilangkan sampel dari kelas mayoritas (kurang sampel) dan / atau menambahkan lebih banyak contoh dari kelas minoritas (over-sampling). Terlepas dari keuntungan menyeimbangkan kelas, teknik -teknik ini juga memiliki kelemahan mereka (tidak ada makan siang gratis). Implementasi over-sampling yang paling sederhana adalah menduplikasi catatan acak dari kelas minoritas, yang dapat menyebabkan overfitting. Dalam sampel di bawah, teknik paling sederhana melibatkan menghilangkan catatan acak dari kelas mayoritas, yang dapat menyebabkan hilangnya informasi.
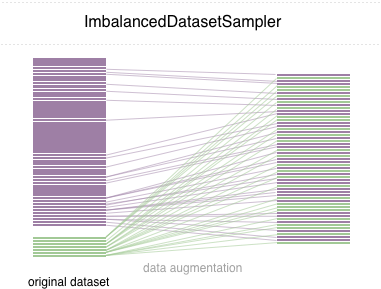
Dalam repo ini, kami mengimplementasikan pytorch sampler yang mudah digunakan ImbalancedDatasetSampler yang mampu
Untuk awal yang sederhana, instal paket melalui salah satu cara berikut:
pip install torchsampler Cukup berikan ImbalancedDatasetSampler untuk sampler parameter saat membuat DataLoader . Misalnya:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)Kemudian di setiap zaman, loader akan mencicipi seluruh dataset dan menimbang sampel Anda terbalik dengan kelas Anda yang muncul probabilitas.
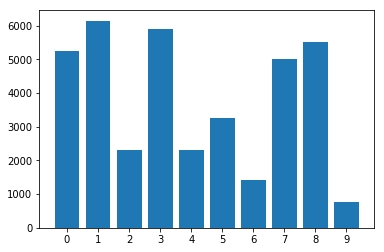
Distribusi kelas dalam dataset yang tidak seimbang:
Dengan dataset sampler yang tidak seimbang:
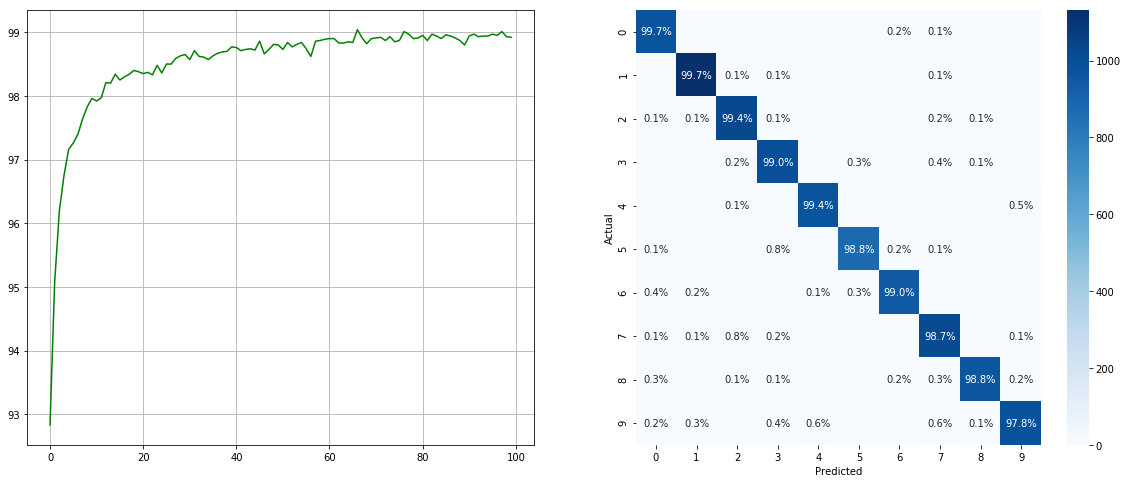 (kiri: uji acc di setiap zaman; kanan: matriks kebingungan)
(kiri: uji acc di setiap zaman; kanan: matriks kebingungan)
Tanpa sampler dataset yang tidak seimbang:
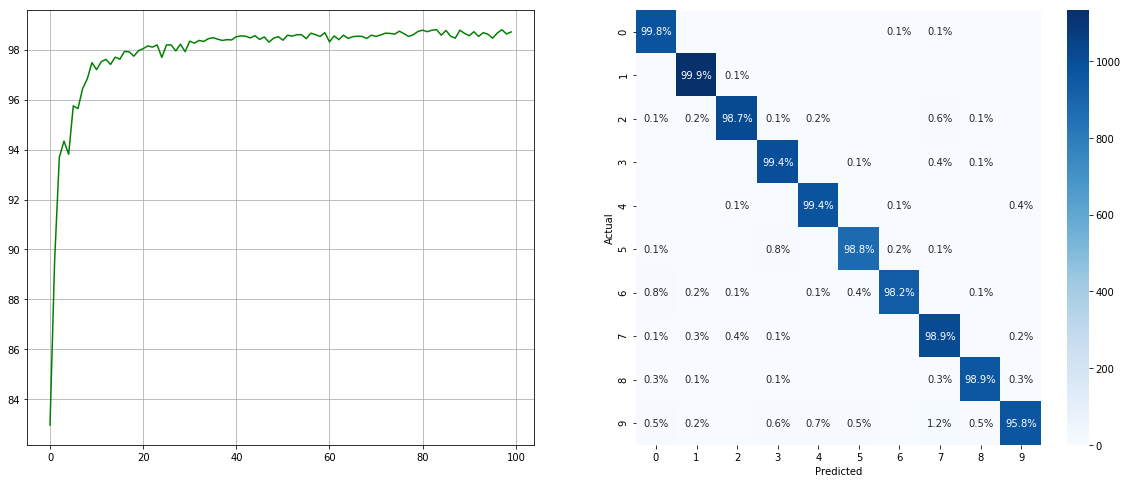 (kiri: uji acc di setiap zaman; kanan: matriks kebingungan)
(kiri: uji acc di setiap zaman; kanan: matriks kebingungan)
Perhatikan bahwa ada peningkatan yang signifikan untuk kelas minor seperti 2 6 9 , sedangkan keakuratan kelas lain dipertahankan.
Kami menghargai semua kontribusi. Jika Anda berencana untuk berkontribusi kembali perbaikan bug, silakan lakukan tanpa diskusi lebih lanjut. Jika Anda berencana untuk menyumbangkan fitur baru, fungsi utilitas atau ekstensi, silakan buka terlebih dahulu dan diskusikan fitur dengan kami.
MIT berlisensi.


