imbalanced dataset sampler
v0.1.2
En muchas aplicaciones de aprendizaje automático, a menudo nos encontramos con conjuntos de datos donde se pueden ver algunos tipos de datos más que otros tipos. Tome la identificación de enfermedades raras, por ejemplo, probablemente haya más muestras normales que las enfermedades. En estos casos, debemos asegurarnos de que el modelo capacitado no esté sesgado hacia la clase que tenga más datos. Como ejemplo, considere un conjunto de datos donde hay 5 imágenes de la enfermedad y 20 imágenes normales. Si el modelo predice que todas las imágenes son normales, su precisión es del 80%, y la puntuación F1 de dicho modelo es 0.88. Por lo tanto, el modelo tiene una alta tendencia a ser sesgado hacia la clase 'normal'.
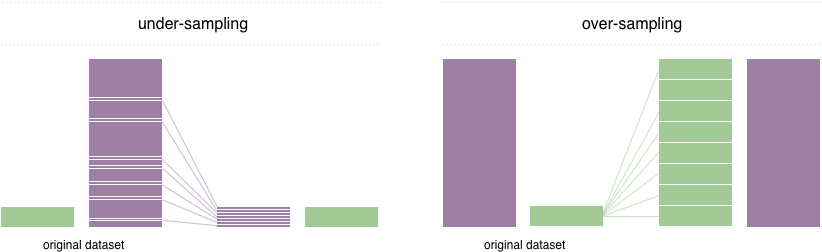
Para resolver este problema, una técnica ampliamente adoptada se llama remuestreo. Consiste en eliminar muestras de la clase mayoritaria (bajo muestreo) y / o agregar más ejemplos de la clase minoritaria (exhibición excesiva). A pesar de la ventaja de equilibrar las clases, estas técnicas también tienen sus debilidades (no hay almuerzo gratis). La implementación más simple de exhibición excesiva es duplicar registros aleatorios de la clase minoritaria, lo que puede causar un sobreajuste. En el bajo muestreo, la técnica más simple implica eliminar registros aleatorios de la clase mayoritaria, lo que puede causar pérdida de información.
En este repositorio, implementamos una muestra de pytorch fácil de usar ImbalancedDatasetSampler que puede
Para un simple inicio, instale el paquete a través de una de las siguientes formas:
pip install torchsampler Simplemente pase un ImbalancedDatasetSampler para el sampler de parámetros al crear un DataLoader . Por ejemplo:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
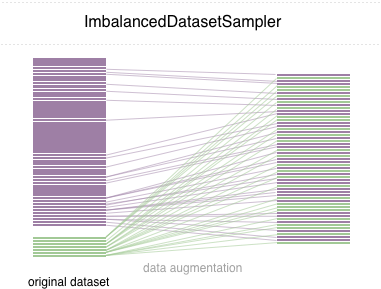
)Luego, en cada época, el cargador probará todo el conjunto de datos y pesará sus muestras inversamente a su clase de probabilidad de aparición.
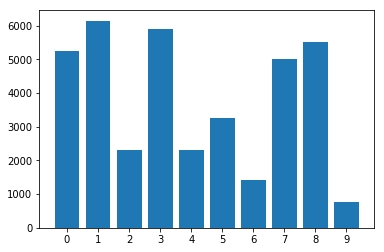
Distribución de clases en el conjunto de datos desequilibrado:
Con muestreador de conjunto de datos desequilibrado:
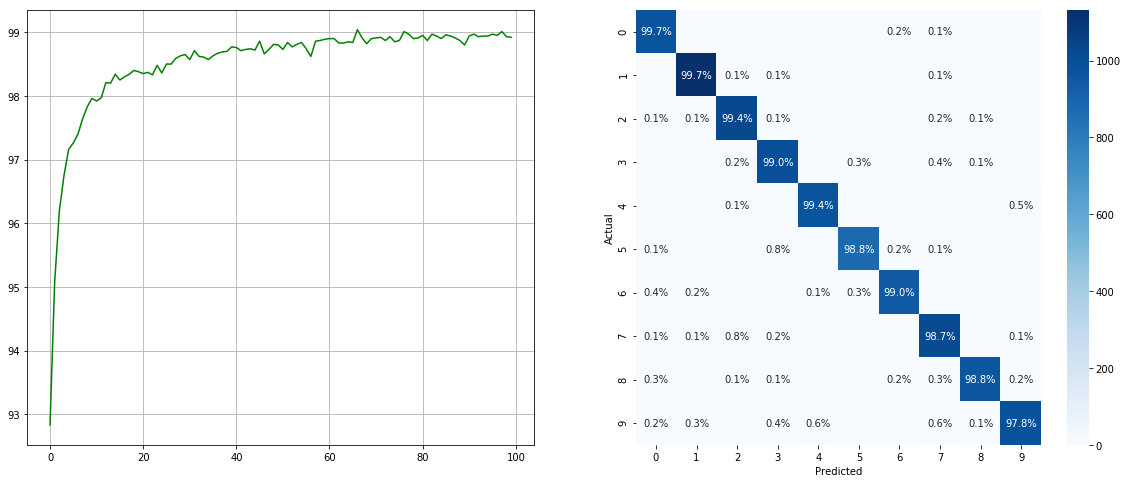 (Izquierda: prueba ACC en cada época; derecha: matriz de confusión)
(Izquierda: prueba ACC en cada época; derecha: matriz de confusión)
Sin muestras de conjunto de datos desequilibrados:
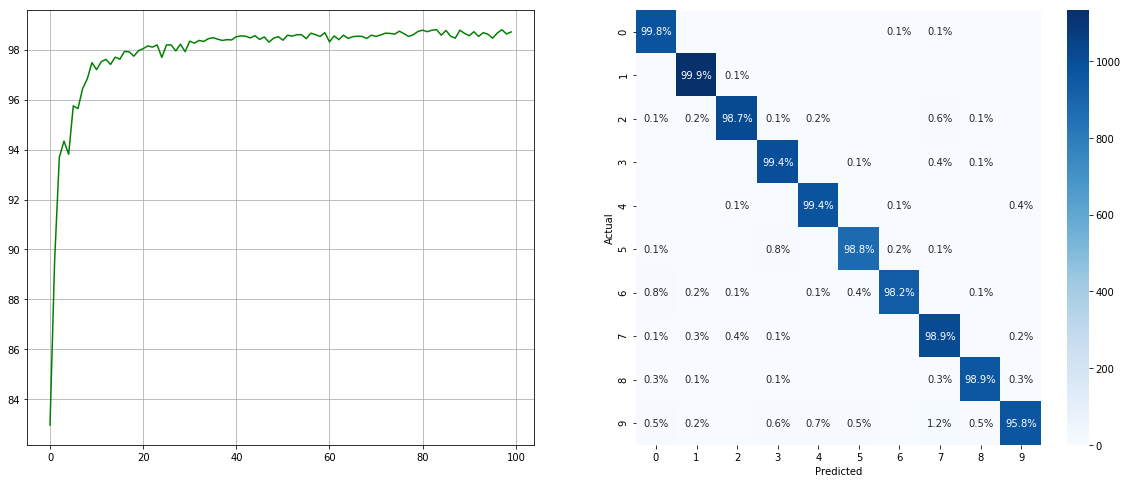 (Izquierda: prueba ACC en cada época; derecha: matriz de confusión)
(Izquierda: prueba ACC en cada época; derecha: matriz de confusión)
Tenga en cuenta que hay mejoras significativas para clases menores como 2 6 9 , mientras que se conserva la precisión de las otras clases.
Apreciamos todas las contribuciones. Si planea contribuir con las fiajas de errores, hágalo sin más discusión. Si planea contribuir con nuevas funciones, funciones de utilidad o extensiones, primero abra un problema y discuta la función con nosotros.
MIT con licencia.


