imbalanced dataset sampler
v0.1.2
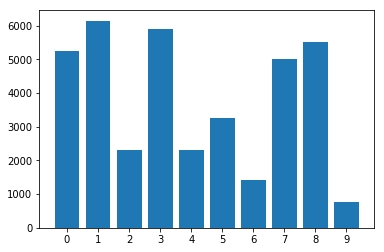
多くの機械学習アプリケーションでは、多くの場合、他のタイプよりもいくつかのタイプのデータが見られるかもしれないデータセットに出くわします。たとえば、まれな疾患の特定を取り入れてください。おそらく病気のサンプルよりも正常なサンプルがあります。これらの場合、訓練されたモデルがより多くのデータを持つクラスに偏っていないことを確認する必要があります。例として、5つの疾患画像と20の通常の画像があるデータセットを検討してください。モデルがすべての画像が正常であると予測する場合、その精度は80%であり、そのようなモデルのF1スコアは0.88です。したがって、モデルは「通常の」クラスに偏っている傾向が高くなります。
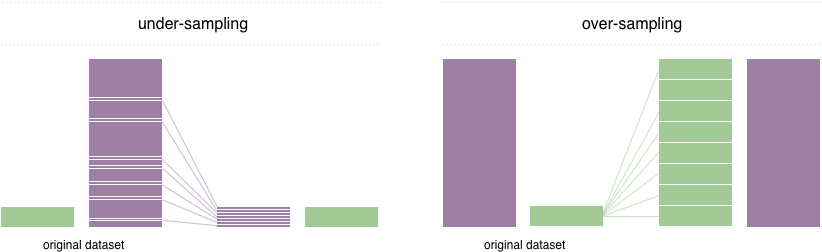
この問題を解決するために、広く採用されている手法は再サンプリングと呼ばれます。多数派のクラスからサンプルを削除(サンプリングを下回っています)、および /または少数派クラス(過剰なサンプリング)からの例を追加することで構成されています。クラスのバランスをとることの利点にもかかわらず、これらのテクニックには弱点もあります(無料の昼食はありません)。過剰サンプリングの最も単純な実装は、マイノリティクラスのランダムレコードを複製することであり、これにより過剰適合を引き起こす可能性があります。サンプリングを下回っている場合、最も単純な手法では、多数派クラスからランダムレコードを削除することが含まれ、情報の損失を引き起こす可能性があります。
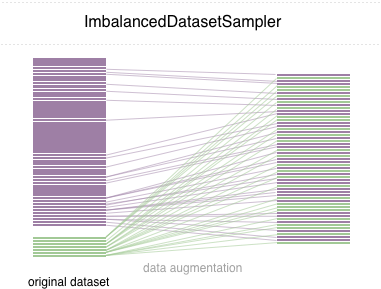
このレポでは、使いやすいPytorchサンプラーのImbalancedDatasetSamplerを実装します。
単純なスタートのために、次の方法のいずれかを介してパッケージをインストールします。
pip install torchsampler DataLoaderを作成するときに、パラメーターsamplerのImbalancedDatasetSampler DataSetSAmplerを渡すだけです。例えば:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)次に、各エポックで、ローダーはデータセット全体をサンプリングし、サンプルの重量をクラスに逆に計量します。
不均衡なデータセット内のクラスの分布:
不均衡なデータセットサンプラーで:
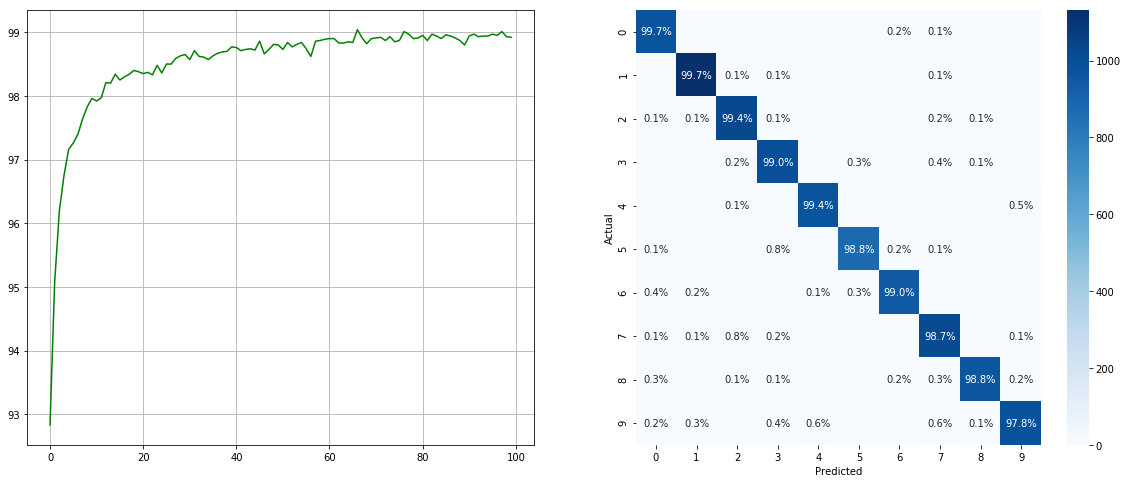 (左:各エポックのテストACC;右:混乱マトリックス)
(左:各エポックのテストACC;右:混乱マトリックス)
不均衡なデータセットサンプラーなし:
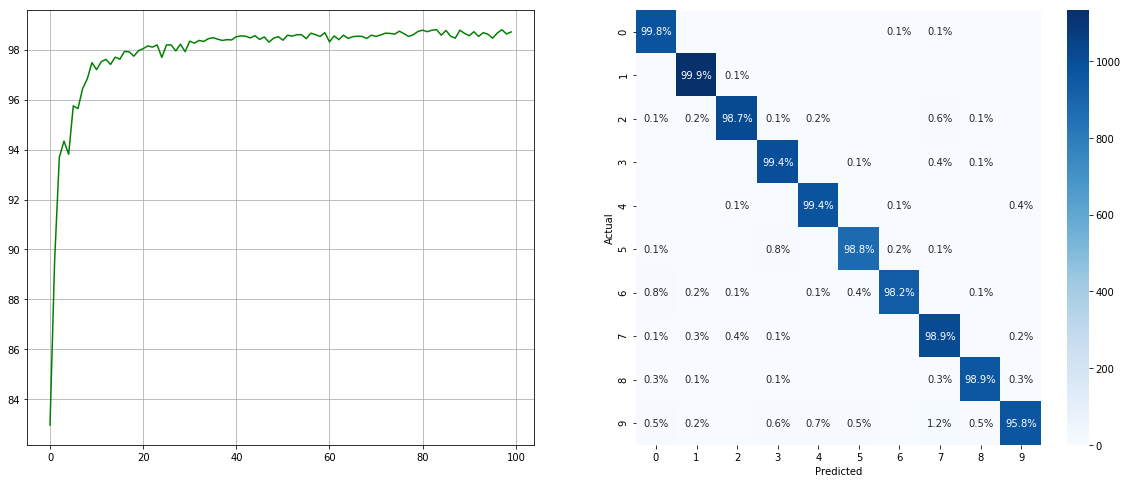 (左:各エポックのテストACC;右:混乱マトリックス)
(左:各エポックのテストACC;右:混乱マトリックス)
2 6 9などのマイナークラスには大幅な改善があり、他のクラスの精度は保持されていることに注意してください。
すべての貢献に感謝します。バックバグフィックスを提供することを計画している場合は、これ以上議論することなくそうしてください。新機能、ユーティリティ関数、または拡張機能を提供する場合は、まず問題を開いて、機能について話し合ってください。
MITライセンス。


