imbalanced dataset sampler
v0.1.2
In vielen Anwendungen für maschinelles Lernen stoßen wir häufig auf Datensätze, in denen einige Arten von Daten mehr als andere Typen gesehen werden können. Nehmen wir zum Beispiel die Identifizierung seltener Krankheiten, es gibt wahrscheinlich normalere Proben als Krankheiten. In diesen Fällen müssen wir sicherstellen, dass das geschulte Modell nicht in der Klasse mit mehr Daten voreingenommen ist. Betrachten Sie beispielsweise einen Datensatz, in dem 5 Krankheitsbilder und 20 normale Bilder vorhanden sind. Wenn das Modell vorhersagt, dass alle Bilder normal sind, beträgt seine Genauigkeit 80%und der F1-Score eines solchen Modells 0,88. Daher hat das Modell eine hohe Tendenz, sich in der "normalen" Klasse vorzulegen.
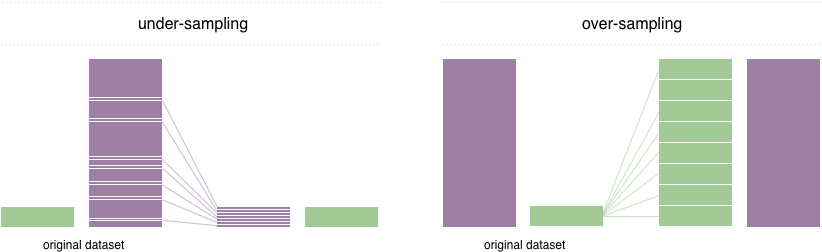
Um dieses Problem zu lösen, wird eine weit verbreitete Technik als Resampling bezeichnet. Es besteht darin, Proben aus der Mehrheitsklasse (Unterabtastung) zu entfernen und / oder weitere Beispiele aus der Minderheitenklasse (Überabtastung) hinzuzufügen. Trotz des Vorteils des Ausgleichsunterrichts haben diese Techniken auch ihre Schwächen (es gibt kein freies Mittagessen). Die einfachste Implementierung von Überampling besteht darin, zufällige Aufzeichnungen aus der Minderheitenklasse zu duplizieren, was zu Überanpassung führen kann. Beim Unterproben sind die einfachste Technik das Entfernen von zufälligen Aufzeichnungen aus der Mehrheitsklasse, was zu einem Informationsverlust führen kann.
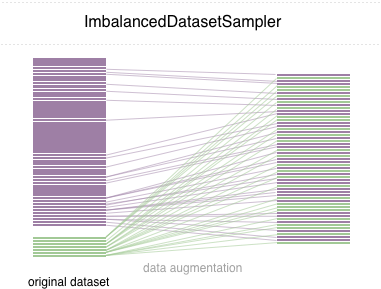
In diesem Repo implementieren wir einen benutzerfreundlichen Pytorch-Sampler ImbalancedDatasetSampler der dazu in der Lage ist
Für einen einfachen Start installieren Sie das Paket über eine der folgenden Möglichkeiten:
pip install torchsampler Geben Sie beim Erstellen eines DataLoader einfach einen ImbalancedDatasetSampler für den Parameter sampler übergeben. Zum Beispiel:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)In jeder Epoche probiert der Loader den gesamten Datensatz und belastet Ihre Proben umgekehrt auf Ihre Klasse, die die Wahrscheinlichkeit erscheint.
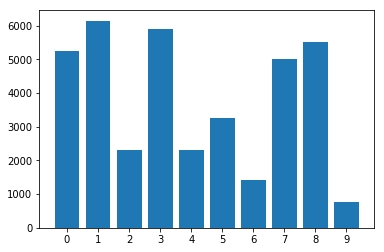
Verteilung von Klassen im unausgeglichenen Datensatz:
Mit unausgewogenem Datensatz -Sampler:
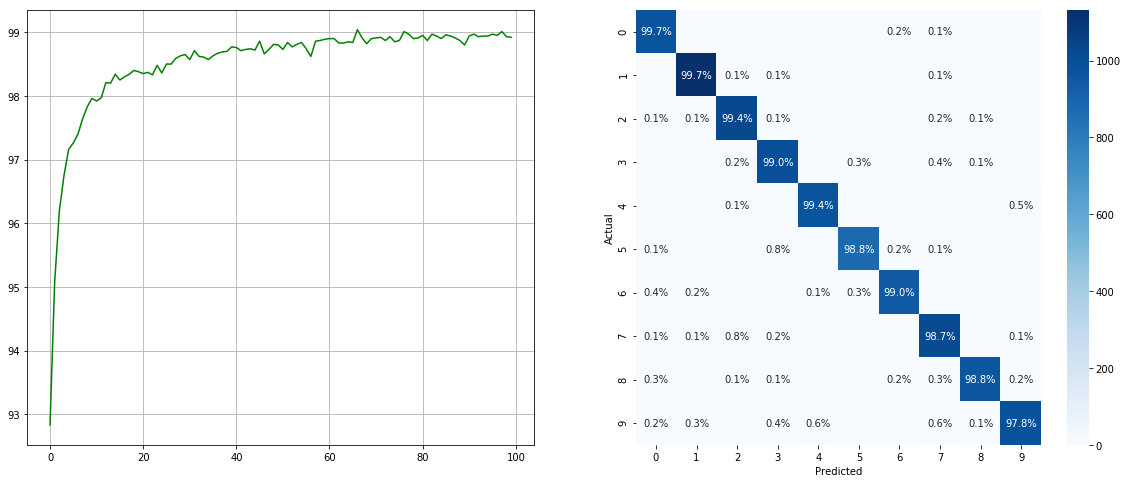 (links: Test ACC in jeder Epoche; rechts: Verwirrungsmatrix)
(links: Test ACC in jeder Epoche; rechts: Verwirrungsmatrix)
Ohne unausgeglichenen Datensatz -Sampler:
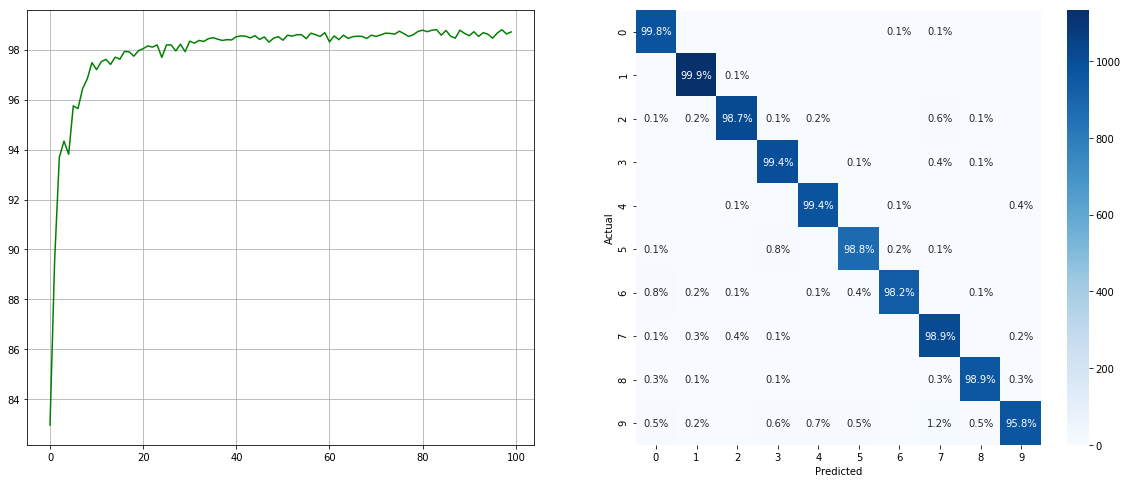 (links: Test ACC in jeder Epoche; rechts: Verwirrungsmatrix)
(links: Test ACC in jeder Epoche; rechts: Verwirrungsmatrix)
Beachten Sie, dass es für kleinere Klassen wie 2 6 9 erhebliche Verbesserungen gibt, während die Genauigkeit der anderen Klassen erhalten bleibt.
Wir schätzen alle Beiträge. Wenn Sie planen, Back-Bug-Fixes beizutragen, tun Sie dies bitte ohne weitere Diskussion. Wenn Sie vorhaben, neue Funktionen, Versorgungsfunktionen oder Erweiterungen beizutragen, eröffnen Sie bitte zunächst ein Problem und diskutieren Sie die Funktion mit uns.
MIT lizenziert.


