imbalanced dataset sampler
v0.1.2
Во многих приложениях машинного обучения мы часто сталкиваемся с наборами данных, где некоторые типы данных можно увидеть больше, чем другие типы. Например, принять идентификацию редких заболеваний, вероятно, более нормальных образцов, чем заболевания. В этих случаях мы должны убедиться, что обученная модель не была смещена в сторону класса, который имеет больше данных. В качестве примера рассмотрим набор данных, где есть 5 изображений заболевания и 20 нормальных изображений. Если модель предсказывает, что все изображения являются нормальными, ее точность составляет 80%, а показатель F1 такой модели составляет 0,88. Следовательно, модель обладает высокой тенденцией к смещению к «нормальному» классу.
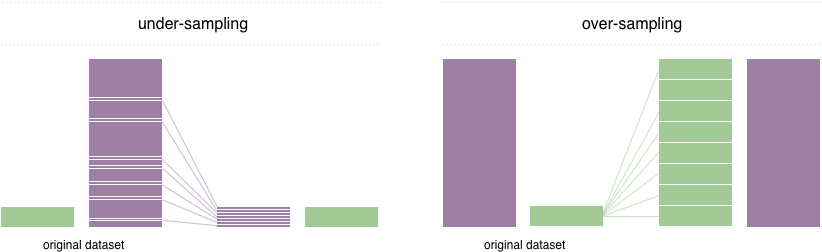
Чтобы решить эту проблему, широко принятая техника называется повторной выборкой. Он состоит из удаления образцов из класса большинства (недостаточная выборка) и / или добавления большего количества примеров из класса меньшинства (перепродажа). Несмотря на преимущество балансировки классов, эти методы также имеют свои слабости (бесплатного обеда нет). Самая простая реализация переполнения-дублировать случайные записи из класса меньшинства, что может вызвать переосмысление. В недостаточной выборке простейшая техника включает в себя удаление случайных записей из большинства, что может вызвать потерю информации.
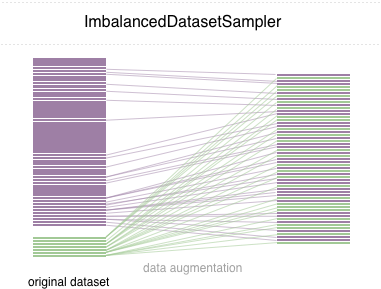
В этом репо, мы внедряем простую в использовании сэмплер Pytorch ImbalancedDatasetSampler , который способен
Для простого начала установить пакет с помощью одного из следующих способов:
pip install torchsampler Просто передайте ImbalancedDatasetSampler датчики для sampler параметров при создании DataLoader . Например:
from torchsampler import ImbalancedDatasetSampler
train_loader = torch . utils . data . DataLoader (
train_dataset ,
sampler = ImbalancedDatasetSampler ( train_dataset ),
batch_size = args . batch_size ,
** kwargs
)Затем в каждую эпоху погрузчик будет пробежать весь набор данных и вывещать ваши образцы обратно пропорционально вашему классу.
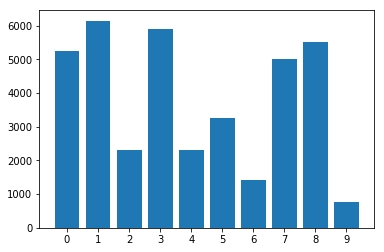
Распределение классов в дисбалансированном наборе данных:
С помощью несбалансированного пробоотборника набора данных:
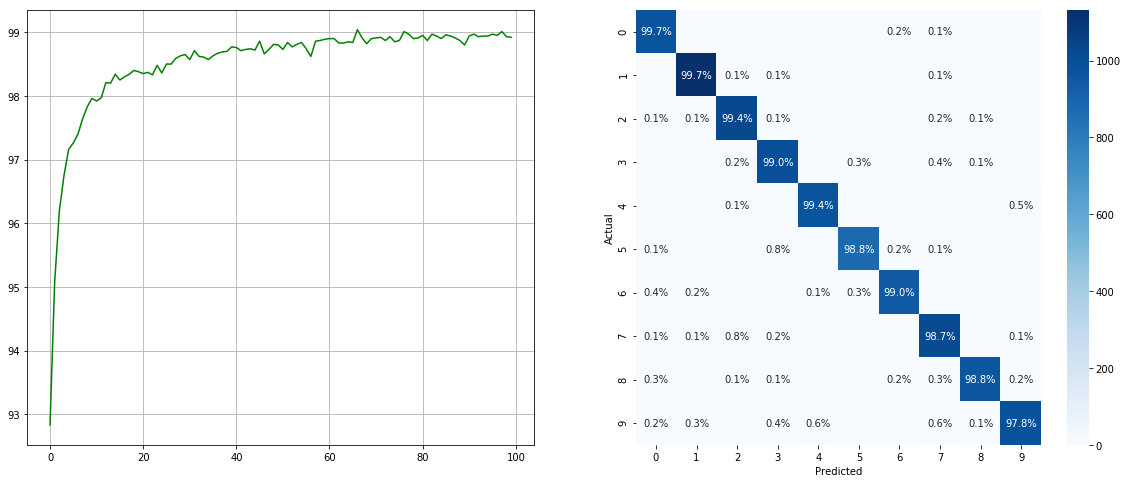 (Слева: тест в каждой эпохе; справа: матрица путаницы)
(Слева: тест в каждой эпохе; справа: матрица путаницы)
Без несбалансированного сэмплера набора данных:
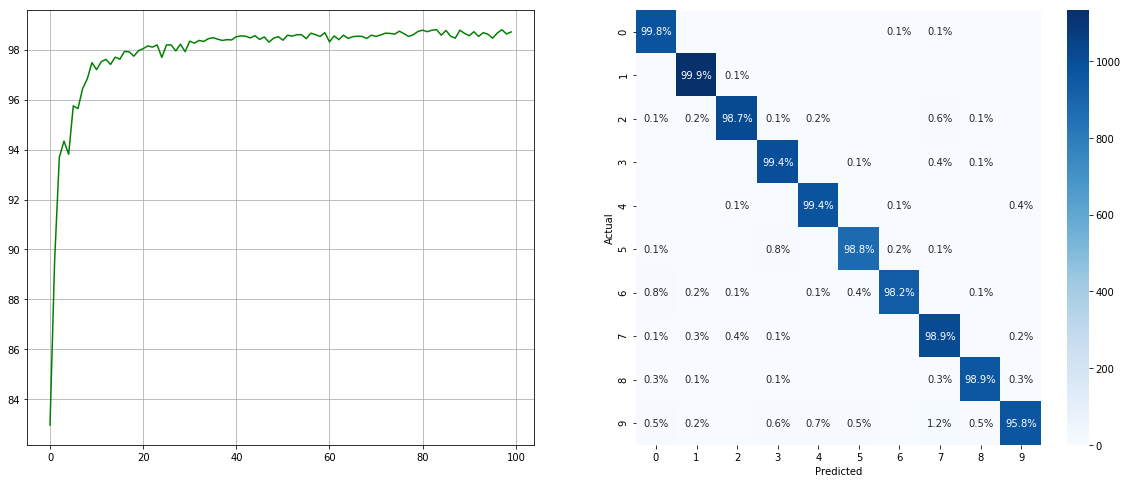 (Слева: тест в каждой эпохе; справа: матрица путаницы)
(Слева: тест в каждой эпохе; справа: матрица путаницы)
Обратите внимание, что существуют значительные улучшения для небольших классов, таких как 2 6 9 , в то время как точность других классов сохраняется.
Мы ценим все вклад. Если вы планируете внести обратный вклад в фиксам ошибок, пожалуйста, сделайте это без дальнейшего обсуждения. Если вы планируете внести новые функции, функции утилиты или расширения, сначала откройте проблему и обсудите эту функцию с нами.
MIT лицензирован.


