uptrain
v0.7.1

UpTrain是一個開源統一平台,用於評估和改善生成AI應用程序。我們為20多個預先配置的評估(涵蓋語言,代碼,嵌入用例)提供成績,對故障案例進行根本原因分析,並就如何解決這些方法進行見解。

UpTrain Dashboard是一個基於Web的接口,可在本地計算機上運行。您可以使用儀表板評估LLM應用程序,查看結果並執行根本原因分析。

支持20多個預先配置的評估,例如響應完整性,事實準確性,上下文簡潔等。

所有評估和分析在您的系統上本地運行,確保數據永遠不會離開您的安全環境(使用模型分級檢查時LLM調用除外)

嘗試不同的嵌入模型,例如Text-Embedding-3 Large/SMALL,Text-Embedding-3-ADA,BAAI/BGE-LARGE等。 UPTRAIN支持Huggingface模型,重複端點或託管在您的端點上的自定義模型。

您可以對用戶反饋負面反饋或低評估分數的案例進行根本原因分析,以了解LLM管道的哪一部分給出次優效果。查看支持的RCA模板。

我們允許您使用任何OpenAI,人類,Mistral,Azure的OpenAI端點或託管在Enyscale上的開源LLM,以用作評估者。

UPTRAIN提供了許多自定義評估的方法。您可以自定義評估方法(思想鏈與分類鏈),很少的示例和方案描述。您還可以創建自定義評估器。
UPTRAIN儀表板是一個基於Web的接口,可讓您評估LLM應用程序。這是一個自託管儀表板,可在本地機器上運行。您無需編寫任何代碼即可使用儀表板。您可以使用儀表板評估LLM應用程序,查看結果並執行根本原因分析。
在開始之前,請確保您在計算機上安裝了Docker。如果沒有,您可以從這里安裝它。
以下命令將下載UpTrain儀表板並在本地計算機上啟動。
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.sh注意: Uptrain儀表板當前使用Beta版本。我們希望您的反饋以改善它。
如果您是開發人員,並且想將上將評估集成到您的應用程序中,則可以使用UPTRAIN軟件包。這允許採用一種評估您的LLM應用程序的更具程序化方法。
pip install uptrain您可以通過提供OpenAI API鍵來運行評估來評估您的響應。
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))如果您有任何疑問,請加入我們的懈怠社區
通過在此處預訂電話直接與Uptrain的維護者交談。

| 評估 | 描述 |
|---|---|
| 響應完整性 | 評分響應是否回答了指定問題的所有方面。 |
| 響應簡潔 | 評分生成的響應是多麼簡潔,或者是否有任何其他無關的信息來提出問題。 |
| 響應相關性 | 等級生成的上下文與指定的問題有多重要。 |
| 響應有效性 | 等級是否有效,是否有效。如果響應包含任何信息,則認為響應是有效的。 |
| 響應一致性 | 等級與提出的問題以及所提供的上下文的響應有多一致。 |

| 評估 | 描述 |
|---|---|
| 上下文相關性 | 等級與指定問題的上下文有多麼重要。 |
| 上下文利用 | 鑑於上下文中提供的信息,對所指定的問題的生成響應的完整程度。 |
| 事實準確性 | 成績是實際上是正確的,並以所提供的上下文為基礎。 |
| 上下文簡潔 | 評估從原始上下文中引用的簡潔上下文,以獲取無關緊要的信息。 |
| 上下文重讀 | 評估將重新計算上下文與原始上下文進行比較的效率。 |

| 評估 | 描述 |
|---|---|
| 語言特徵 | 評分語言在響應中的質量和有效性,重點是清晰,連貫性,簡潔性和整體交流等因素。 |
| 音調 | 評分生成的響應是否與所需角色的基調相匹配 |

| 評估 | 描述 |
|---|---|
| 代碼幻覺 | 等級是基於上下文基礎的生成響應中存在的代碼。 |

| 評估 | 描述 |
|---|---|
| 用戶滿意度 | 評分用戶的問題如何解決,並根據提供的對話評估他們的滿意度。 |

| 評估 | 描述 |
|---|---|
| 自定義指南 | 允許您指定指南,並分級LLM在給出響應時遵守提供的指南。 |
| 自定義提示 | 允許您創建自己的評估集。 |

| 評估 | 描述 |
|---|---|
| 響應匹配 | 比較LLM與所提供的地面真相一致的響應對響應的良好狀態。 |

| 評估 | 描述 |
|---|---|
| 提示注射 | 評分用戶的提示是否試圖使LLM揭示其係統提示。 |
| 越獄檢測 | 評分用戶的提示是嘗試越獄的嘗試(即產生非法或有害響應)。 |

| 評估 | 描述 |
|---|---|
| 子問題完整性 | 評估是否從用戶查詢中產生的所有子問題一起,涵蓋用戶查詢的所有方面 |
| 多傳奇準確性 | 評估生成的變體是否準確表示原始查詢 |
| 評估框架 | LLM提供商 | LLM軟件包 | 服務框架 | LLM可觀察性 | 向量DBS |
|---|---|---|---|---|---|
| Openai Evals | Openai | Llamaindex | 霍拉馬 | langfuse | QDRANT |
| azure | 一起 | Helicone | faiss | ||
| 克勞德 | 任何規模 | zeno | 色度 | ||
| Mistral | 複製 | ||||
| 擁抱面 |
更多的集成即將到來。如果您有特定的集成,請通過創建問題讓我們知道。
最受歡迎的LLM如GPT-4,GPT-3.5-Turbo,Claude-2.1等是封閉消息,即通過API暴露,對引擎蓋下發生的情況幾乎沒有可見性。據報導,有許多迅速漂移(或GPT-4變得懶惰)和研究工作探討模型質量退化的研究。該基準是通過在固定數據集上評估其響應來跟踪模型行為的變化的嘗試。
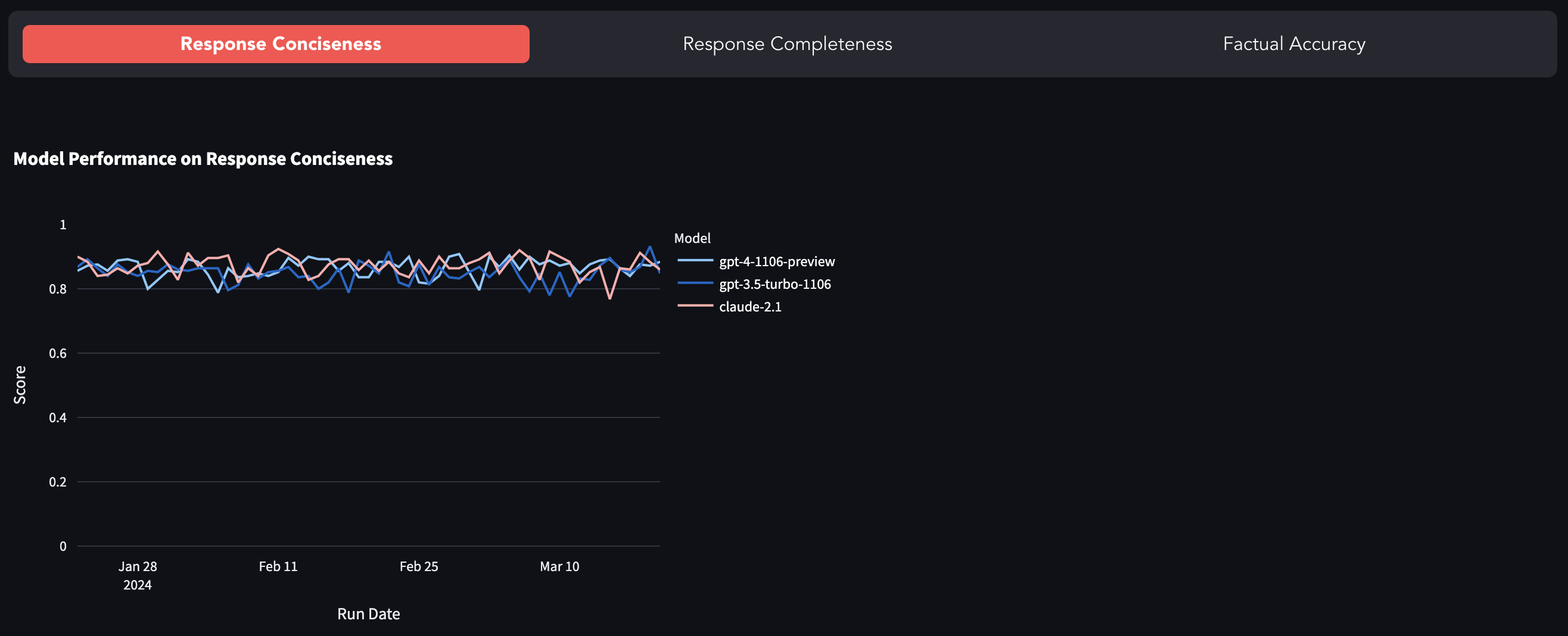
您可以在這裡找到基準。
在過去的8年中,我們與ML和NLP模型合作過,在模型中,我們一直在不斷地散佈著許多隱藏的故障,從而導致我們建立了Uptrain。最初,UpTrain是作為ML可觀察性工具開始的,該工具具有檢查,以識別準確性的回歸。
但是,我們很快發布了LLM開發人員面臨更大的問題 - 沒有一個很好的方法來衡量其LLM應用程序的準確性,更不用說識別回歸了。
我們還看到了Openai Evals的釋放,他們提出使用LLM來對模型響應進行評分。此外,我們在閱讀了擬人化利用RLAIF並直接參與LLM評估研究之後,我們獲得了對此的信心(我們很快就會釋放出令人敬畏的評估研究的存儲庫)。
因此,今天來,Uptrain是我們為LLM混亂帶來命令並向社區貢獻的嘗試。儘管大多數開發人員仍然通過審查幾個案例來依靠直覺和生產迅速變化,但我們已經聽到足夠的回歸故事來相信“評估和改進”將是LLM生態系統的關鍵部分,因為太空的成熟。
強大的評估使您可以系統地實驗不同的配置,並通過幫助客觀地選擇最佳選擇來防止任何回歸。
它可以幫助您了解系統出錯的位置,找到根本原因並修復它們 - 早在最終用戶抱怨並可能耗盡之前。
及時注射和越獄檢測等評估對於維持LLM應用程序的安全性至關重要。
評估可以幫助您提供透明度並與最終用戶建立信任 - 如果您向企業出售,尤其是相關的。
我們了解到,在評估方面,沒有一個大小的解決方案。我們越來越多地看到開發人員渴望修改評估提示或一組選擇或少數鏡頭示例等。我們相信最好的開發人員體驗在於開源,而不是暴露20個不同的參數。
促進創新:LLM評估領域和使用LLM-AS-A-Gudge的領域仍然很新生。我們幾乎每天都會看到許多令人興奮的研究正在進行,開源為我們和我們的社區提供了正確的平台,以實施這些技術並更快地進行創新。
我們一直在努力增強上升訓練,您可以通過幾種方式來貢獻:
請注意任何要改進的問題或領域:如果您發現任何錯誤或有增強功能的想法,請在我們的GitHub存儲庫上創建一個問題。
直接貢獻:如果您看到問題,則可以修復或進行改進以提出建議,請隨時直接為存儲庫做出貢獻。
請求自定義評估:如果您的應用程序需要量身定制的評估,請告訴我們,我們將其添加到存儲庫中。
與您的工具集成:需要與現有工具集成嗎?伸出援手,我們將努力。
評估協助:如果您需要評估方面的幫助,請在我們的Slack頻道上發布查詢,我們將及時解決。
表示您的支持:通過在Github上主演以跟踪我們的進度,向您展示您的支持。
傳播詞:如果您喜歡我們建造的東西,請在Twitter上大喊大叫!
非常感謝您的貢獻和支持!感謝您成為Uptrain旅程的一部分。
此存儲庫由Apache 2.0許可發布,我們致力於向Uptrain Opentrain開源存儲庫添加更多功能。如果您只想獲得更多的駕駛體驗,我們也有託管版本。請在此處預訂演示電話。
我們正在公共場所建立上升趨勢。通過在此處提供反饋來幫助我們改善。
我們歡迎對上升的貢獻。請參閱我們的貢獻指南以獲取詳細信息。


