uptrain
v0.7.1

O UpTrain é uma plataforma unificada de código aberto para avaliar e melhorar os aplicativos generativos de IA. Fornecemos notas para mais de 20 avaliações pré -configuradas (cobrindo idioma, código, incorporação de casos de uso), executam análises de causa raiz nos casos de falha e fornecem informações sobre como resolvê -las.

O Uptrain Painel é uma interface baseada na Web que é executada em sua máquina local . Você pode usar o painel para avaliar seus aplicativos LLM, visualizar os resultados e executar uma análise de causa raiz.

Suporte para mais de 20 avaliações pré-configuradas , como integridade da resposta, precisão factual, concisão de contexto etc.

Todas as avaliações e análises são executadas localmente no seu sistema, garantindo que os dados nunca deixem seu ambiente seguro (exceto para chamadas de LLM enquanto usam verificações de classificação de modelos)

Experimente diferentes modelos de incorporação, como embutir o texto-3-grande/pequeno, embebedando texto-3-Ada, Baai/BGE-Large, etc. O ativo suporta modelos Huggingface, pontos de extremidade replicados ou modelos personalizados hospedados no seu ponto final.

Você pode executar análises de causa raiz em casos com feedback negativo do usuário ou baixas pontuações de avaliação para entender qual parte do seu pipeline LLM está fornecendo resultados abaixo do ideal. Confira os modelos RCA suportados.

Permitimos que você use qualquer um dos pontos de extremidade OpenAI, Antrópico, Mistral, Openai do Azure ou LLMs de código aberto hospedados em qualquer escala para ser usada como avaliadores.

UpTrain fornece toneladas de maneiras de personalizar avaliações . Você pode personalizar o método de avaliação (cadeia de pensamento versus classificar), exemplos de poucos anos e descrição do cenário. Você também pode criar avaliadores personalizados.
O painel de atração principal é uma interface baseada na Web que permite avaliar seus aplicativos LLM. É um painel auto-hospedado que roda em sua máquina local. Você não precisa escrever nenhum código para usar o painel. Você pode usar o painel para avaliar seus aplicativos LLM, visualizar os resultados e executar uma análise de causa raiz.
Antes de começar, verifique se você instalou o Docker em sua máquina. Caso contrário, você pode instalá -lo a partir daqui.
Os seguintes comandos baixarão o painel de atração de subida e o iniciarão em sua máquina local.
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.shNOTA: O painel UpTrain está atualmente na versão beta . Adoraríamos seu feedback para melhorá -lo.
Se você é um desenvolvedor e deseja integrar as avaliações de atração de atração no seu aplicativo, você pode usar o pacote de atração principal. Isso permite uma maneira mais programática de avaliar seus aplicativos LLM.
pip install uptrainVocê pode avaliar suas respostas através da versão de código aberto, fornecendo sua chave de API do OpenAI para executar avaliações.
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))Se você tiver alguma dúvida, junte -se à nossa comunidade Slack
Fale diretamente com os mantenedores do atreto, reservando uma chamada aqui.

| Aval | Descrição |
|---|---|
| Reclamação da resposta | Gosses se a resposta respondeu a todos os aspectos da pergunta especificada. |
| Resposta Concisão | Classifica como concisa a resposta gerada ou se possui alguma informação irrelevante adicional para a pergunta feita. |
| Relevância da resposta | Notas quão relevante foi o contexto gerado para a pergunta especificada. |
| Validade da resposta | Notas se a resposta gerada for válida ou não. Uma resposta é considerada válida se contiver alguma informação. |
| Consistência da resposta | Nadas quão consistente é a resposta com a pergunta feita e com o contexto fornecido. |

| Aval | Descrição |
|---|---|
| Relevância do contexto | Notas quão relevante foi o contexto para a pergunta especificada. |
| Utilização do contexto | Notas como a resposta gerada foi completa para a pergunta especificada, dadas as informações fornecidas no contexto. |
| Precisão factual | Gosses se a resposta gerada é factualmente correta e fundamentada pelo contexto fornecido. |
| Concisão de contexto | Avalia o contexto conciso citado a partir de um contexto original para obter informações irrelevantes. |
| Remolando de contexto | Avalia a eficiência do contexto re -classificado comparado ao contexto original. |

| Aval | Descrição |
|---|---|
| Recursos de linguagem | Classifica a qualidade e a eficácia da linguagem em uma resposta, com foco em fatores como clareza, coerência, concisão e comunicação geral. |
| Tonalidade | Notas se a resposta gerada corresponde ao tom da persona necessária |

| Aval | Descrição |
|---|---|
| Holucinação de código | Gosses se o código presente na resposta gerada é fundamentada pelo contexto. |

| Aval | Descrição |
|---|---|
| Satisfação do usuário | Notas quão bem as preocupações do usuário são abordadas e avalia sua satisfação com base na conversa fornecida. |

| Aval | Descrição |
|---|---|
| Diretriz personalizada | Permite especificar uma diretriz e classificar o quão bem o LLM adere à diretriz fornecida ao dar uma resposta. |
| Prompts personalizados | Permite criar seu próprio conjunto de avaliações. |

| Aval | Descrição |
|---|---|
| Correspondência de resposta | Compara e classifica o quão bem a resposta gerada pelo LLM se alinha com a verdade fundamental fornecida. |

| Aval | Descrição |
|---|---|
| Injeção imediata | Notas se o prompt do usuário é uma tentativa de fazer com que o LLM revele o sistema de seu sistema. |
| Detecção de jailbreak | Notas se o prompt do usuário é uma tentativa de jailbreak (ou seja, gerar respostas ilegais ou prejudiciais). |

| Aval | Descrição |
|---|---|
| Completude sub-interveio | Avalie se todas as sub-perguntas geradas a partir da consulta de um usuário, juntas, cobrem todos os aspectos da consulta do usuário ou não |
| Precisão multi-query | Avalie se as variantes geradas representam com precisão a consulta original |
| Estruturas de avaliação | Provedores de LLM | Pacotes LLM | Estruturas de serviço | Observabilidade LLM | Vector DBS |
|---|---|---|---|---|---|
| Openai Evals | Openai | Llamaindex | Ollama | Langfuse | QDRANT |
| Azure | Juntos ai | Helicone | FAISS | ||
| Claude | AnyScale | Zeno | Chroma | ||
| Mistral | Replicar | ||||
| Huggingface |
Mais integrações estão chegando em breve. Se você tiver uma integração específica em mente, informe -nos criando um problema.
Os LLMs mais populares como GPT-4, GPT-3.5-Turbo, Claude-2.1 etc. são de código fechado, ou seja, expostos através de uma API com muito pouca visibilidade do que acontece sob o capô. Existem muitos casos relatados de desvio imediato (ou GPT-4 se tornando preguiçoso) e trabalho de pesquisa explorando a degradação na qualidade do modelo. Este benchmark é uma tentativa de rastrear a mudança no comportamento do modelo, avaliando sua resposta em um conjunto de dados fixo.
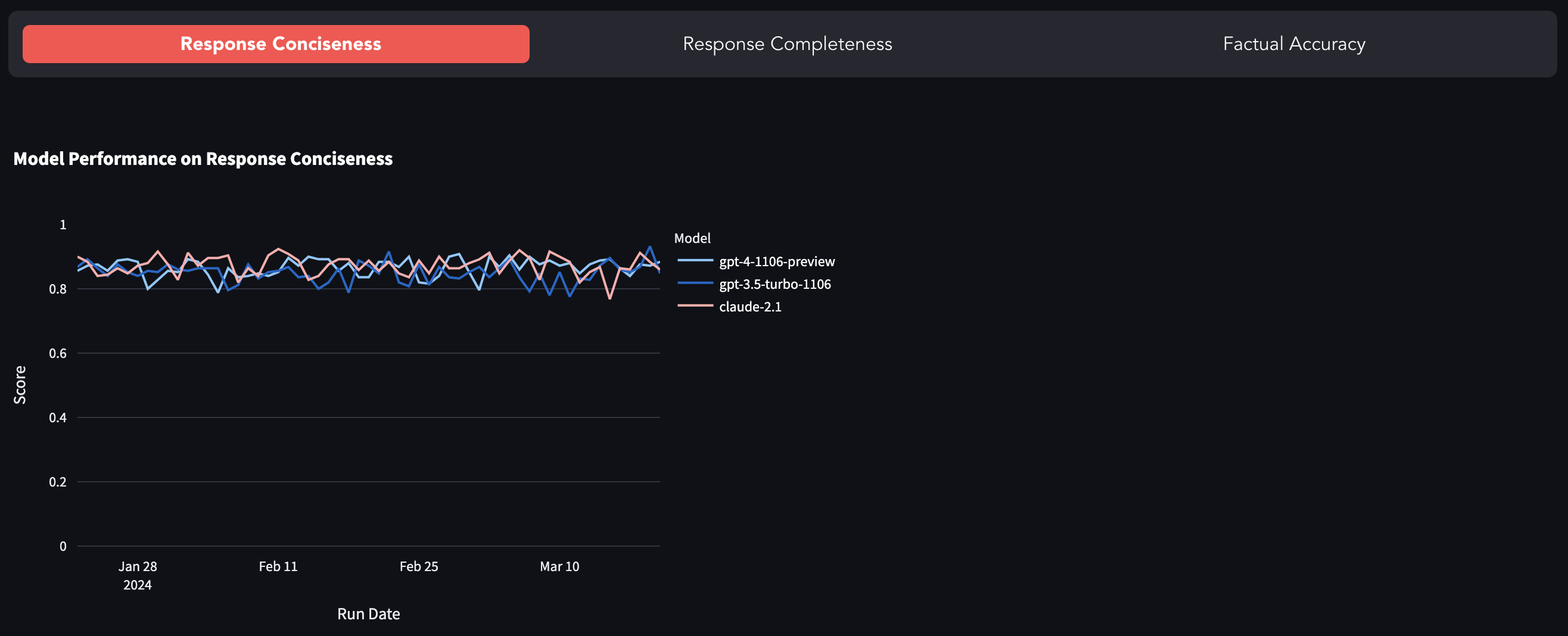
Você pode encontrar a referência aqui.
Tendo trabalhado com os modelos ML e PNL nos últimos 8 anos, fomos contínuos com inúmeras falhas ocultas em nossos modelos, o que nos levou a construir um aterro. O atreto foi iniciado inicialmente como uma ferramenta de observabilidade do ML com verificações para identificar a regressão na precisão.
No entanto, logo divulgamos que os desenvolvedores da LLM enfrentam um problema ainda maior - não há uma boa maneira de medir a precisão de seus aplicativos LLM, muito menos identificar a regressão.
Também vimos a liberação do Openai Evals, onde eles propuseram o uso do LLMS para classificar as respostas do modelo. Além disso, ganhamos confiança para abordar isso depois de ler como as alavancas antrópicas rlaif e mergulharam diretamente na pesquisa de avaliações da LLM (em breve estamos lançando um repositório de pesquisas de avaliações impressionantes).
Então, venha hoje, o ativo é nossa tentativa de trazer ordem ao caos do LLM e contribuir de volta para a comunidade. Embora a maioria dos desenvolvedores ainda confie na intuição e nas mudanças de produção, revisando alguns casos, ouvimos histórias de regressão suficientes para acreditar que "avaliações e melhorias" serão uma parte essencial do ecossistema LLM à medida que o espaço amadurece.
Avaliações robustas permitem experimentar sistematicamente diferentes configurações e evitar regressões, ajudando a selecionar objetivamente a melhor opção.
Ajuda a entender onde seus sistemas estão errando, encontre as causas da raiz e a corrige - muito antes de os usuários finais reclamarem e potencialmente agitar.
Avaliações como injeção imediata e detecção de jailbreak são essenciais para manter a segurança de seus aplicativos LLM.
As avaliações ajudam você a fornecer transparência e criar confiança com seus usuários finais - especialmente relevantes se você estiver vendendo para empresas.
Entendemos que não existe uma solução única quando se trata de avaliações. Estamos cada vez mais vendo o desejo dos desenvolvedores de modificar o prompt de avaliação ou o conjunto de opções ou os poucos exemplos de tiro, etc. Acreditamos que a melhor experiência do desenvolvedor está de código aberto, em vez de expor 20 parâmetros diferentes.
Foster inovação : o campo das avaliações do LLM e o uso de LLM-AS-A-JUDGE ainda é bastante nascente. Vemos muitas pesquisas emocionantes acontecendo, quase diariamente, e ser de código aberto fornece a plataforma certa para nós e nossa comunidade para implementar essas técnicas e inovar mais rapidamente.
Estamos continuamente nos esforçando para melhorar o atrito, e há várias maneiras de contribuir:
Observe quaisquer problemas ou áreas de melhoria: se você encontrar algo errado ou tiver idéias para aprimoramentos, crie um problema em nosso repositório do GitHub.
Contribua diretamente: se você vir um problema, poderá corrigir ou ter melhorias de código para sugerir, sinta -se à vontade para contribuir diretamente para o repositório.
Solicite avaliações personalizadas: se o seu aplicativo exigir uma avaliação personalizada, informe -nos e o adicionaremos ao repositório.
Integre -se às suas ferramentas: precisa de integração com suas ferramentas existentes? Estenda a mão e vamos trabalhar nisso.
Assistência com avaliações: se você precisar de assistência com as avaliações, poste sua consulta em nosso canal Slack e resolveremos prontamente.
Mostre seu apoio: mostre seu apoio nos estrelando no Github para acompanhar nosso progresso.
Espalhe a palavra: se você gosta do que construímos, dê -nos um grito no Twitter!
Suas contribuições e apoio são muito apreciados! Obrigado por fazer parte da jornada do atreto.
Este repositório é publicado na licença Apache 2.0 e estamos comprometidos em adicionar mais funcionalidades ao repositório de código aberto. Também temos uma versão gerenciada se você quiser apenas uma experiência mais prática. Por favor, reserve uma chamada de demonstração aqui.
Estamos construindo ativo em público. Ajude -nos a melhorar, dando seu feedback aqui .
Congratulamo -nos com contribuições para o atreto. Consulte nosso guia de contribuição para obter detalhes.


