uptrain
v0.7.1

Uptrain es una plataforma unificada de código abierto para evaluar y mejorar las aplicaciones generativas de IA. Proporcionamos calificaciones para más de 20 evaluaciones preconfiguradas (que cubren el lenguaje, el código, la incrustación de casos de uso), realizamos análisis de causa raíz en los casos de falla y damos información sobre cómo resolverlos.

El tablero de Train es una interfaz basada en la web que se ejecuta en su máquina local . Puede usar el tablero para evaluar sus aplicaciones LLM, ver los resultados y realizar un análisis de causa raíz.

Soporte para más de 20 evaluaciones preconfiguradas , como la integridad de la respuesta, la precisión objetiva, la concisión del contexto, etc.

Todas las evaluaciones y análisis se ejecutan localmente en su sistema, asegurando que los datos nunca dejen su entorno seguro (excepto las llamadas de LLM mientras usan controles de calificación de modelos)

Experimente con diferentes modelos de incrustación como texto-3-Large/pequeño, Embeding-3-ADA, BAAI/BGE-LARGE, etc. UpTrain admite modelos Huggingface, puntos finales replicados o modelos personalizados alojados en su punto final.

Puede realizar un análisis de causa raíz en casos con retroalimentación negativa del usuario o puntajes de evaluación bajos para comprender qué parte de su tubería LLM está dando resultados subóptimos. Echa un vistazo a las plantillas RCA compatibles.

Le permitimos usar cualquiera de los puntos finales de OpenAI de Azure o LLM de código abierto o LLM de código abierto alojados en cualquier escala para ser utilizados como evaluadores.

Uptrain proporciona toneladas de formas de personalizar las evaluaciones . Puede personalizar el método de evaluación (cadena de pensamiento frente a clasificación), ejemplos de pocos disparos y descripción del escenario. También puede crear evaluadores personalizados.
El tablero Uptrain es una interfaz basada en la web que le permite evaluar sus aplicaciones LLM. Es un tablero autohostado que se ejecuta en su máquina local. No necesita escribir ningún código para usar el tablero. Puede usar el tablero para evaluar sus aplicaciones LLM, ver los resultados y realizar un análisis de causa raíz.
Antes de comenzar, asegúrese de tener Docker instalado en su máquina. Si no, puede instalarlo desde aquí.
Los siguientes comandos descargarán el tablero de traín y lo iniciarán en su máquina local.
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.shNota: el tablero de tensiones de Uptrain se encuentra actualmente en la versión beta . Nos encantaría sus comentarios para mejorarlo.
Si es un desarrollador y desea integrar las evaluaciones de ascensación en su aplicación, puede usar el paquete Uptrain. Esto permite una forma más programática de evaluar sus aplicaciones LLM.
pip install uptrainPuede evaluar sus respuestas a través de la versión de código abierto proporcionando su tecla API OpenAI para ejecutar evaluaciones.
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))Si tiene alguna pregunta, únase a nuestra comunidad Slack
Hable directamente con los mantenedores de Uptrain reservando una llamada aquí.

| Evaluación | Descripción |
|---|---|
| Completa de respuesta | Grados si la respuesta ha respondido todos los aspectos de la pregunta especificada. |
| Respuesta Concisión | Califica cuán concisa es la respuesta generada o si tiene alguna información irrelevante adicional para la pregunta que se hace. |
| Relevancia de respuesta | Califica cuán relevante era el contexto generado a la pregunta especificada. |
| Validez de respuesta | Calificaciones si la respuesta generada es válida o no. Se considera que una respuesta es válida si contiene alguna información. |
| Consistencia de respuesta | Califica cuán consistente es la respuesta con la pregunta que se hace, así como con el contexto proporcionado. |

| Evaluación | Descripción |
|---|---|
| Relevancia del contexto | Califica cuán relevante era el contexto de la pregunta especificada. |
| Utilización del contexto | Grados cuán completa fue la respuesta generada para la pregunta especificada, dada la información proporcionada en el contexto. |
| Precisión objetiva | Calificaciones si la respuesta generada es objetiva y fundada por el contexto proporcionado. |
| Contexto concisión | Evalúa el contexto conciso citado desde un contexto original para información irrelevante. |
| Contexto que se está volviendo loco | Evalúa cuán eficiente es el contexto reiniciado con el contexto original. |

| Evaluación | Descripción |
|---|---|
| Características del idioma | Califica la calidad y efectividad del lenguaje en una respuesta, centrándose en factores como claridad, coherencia, concisión y comunicación general. |
| Tonalidad | Califica si la respuesta generada coincide con el tono de la personalidad requerida |

| Evaluación | Descripción |
|---|---|
| Alucinación de código | Califica si el código presente en la respuesta generada se basa en el contexto. |

| Evaluación | Descripción |
|---|---|
| Satisfacción del usuario | Califica qué tan bien se abordan las preocupaciones del usuario y evalúan su satisfacción en función de la conversación proporcionada. |

| Evaluación | Descripción |
|---|---|
| Guía personalizada | Le permite especificar una guía y calificar qué tan bien se adhiere el LLM a la guía proporcionada al dar una respuesta. |
| Indicaciones personalizadas | Le permite crear su propio conjunto de evaluaciones. |

| Evaluación | Descripción |
|---|---|
| Correspondencia de respuesta | Compara y califica qué tan bien la respuesta generada por el LLM se alinea con la verdad del suelo proporcionado. |

| Evaluación | Descripción |
|---|---|
| Inyección rápida | Califica si el aviso del usuario es un intento de hacer que el LLM revele sus indicaciones del sistema. |
| Detección de jailbreak | Califica si el aviso del usuario es un intento de jailbreak (es decir, generar respuestas ilegales o dañinas). |

| Evaluación | Descripción |
|---|---|
| Integridad de subcontrol | Evaluar si todas las subcuestiones generadas a partir de la consulta de un usuario, tomadas en conjunto, cubren todos los aspectos de la consulta del usuario o no |
| Precisión múltiple | Evaluar si las variantes generadas representan con precisión la consulta original |
| Marcos de evaluación | Proveedores de LLM | Paquetes LLM | Marcos de servicio | Observabilidad de LLM | Vector DBS |
|---|---|---|---|---|---|
| Operai Evals | Opadai | Llamado | Ollama | Langfuse | Qdrant |
| Azur | Juntos ai | Helicona | Faiss | ||
| Tirar | Escala | Zenovado | Croma | ||
| Mistral | Reproducir exactamente | ||||
| Cara de abrazo |
Pronto llegarán más integraciones. Si tiene una integración específica en mente, háganoslo saber creando un problema.
Las LLM más populares como GPT-4, GPT-3.5-TURBO, Claude-2.1, etc., son de código cerrado, es decir, a través de una API con muy poca visibilidad de lo que sucede debajo del capó. Hay muchos casos reportados de avance rápido (o GPT-4 que se vuelven perezoso) y el trabajo de investigación que explora la degradación en la calidad del modelo. Este punto de referencia es un intento de rastrear el cambio en el comportamiento del modelo evaluando su respuesta en un conjunto de datos fijo.
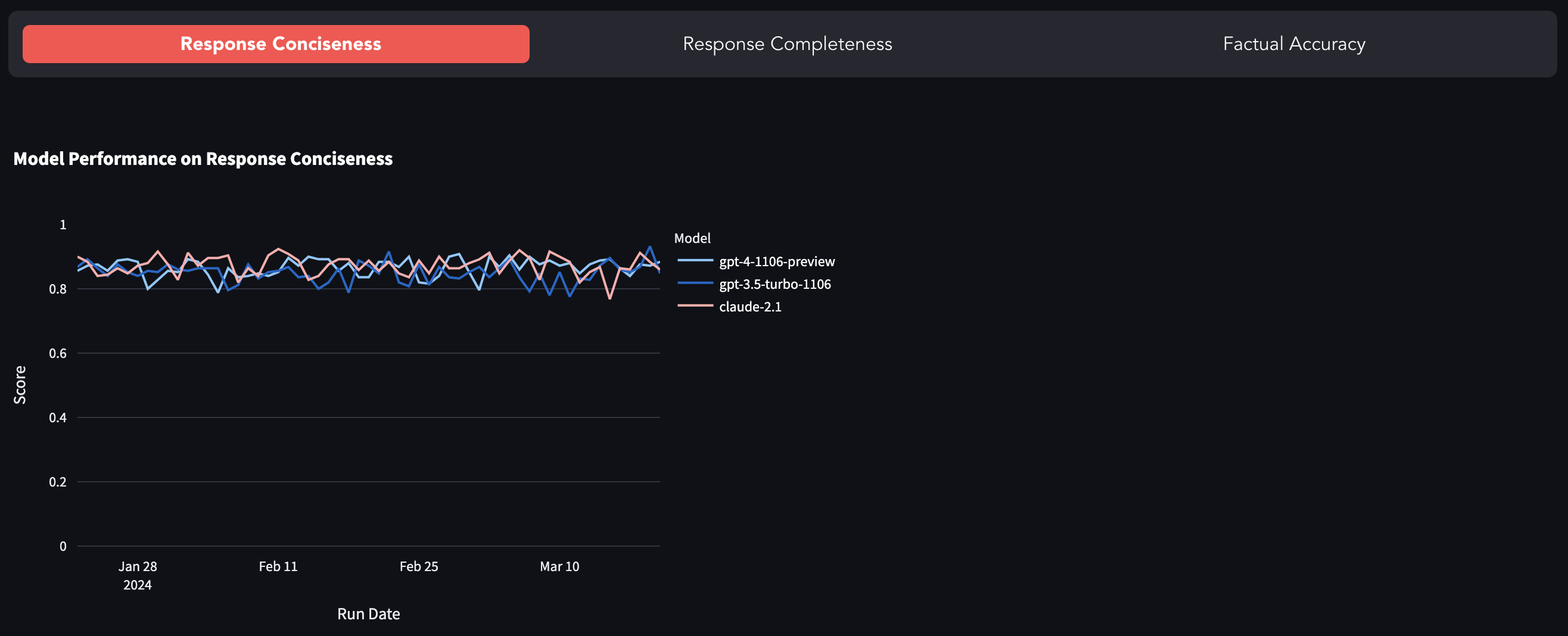
Puedes encontrar el punto de referencia aquí.
Después de haber trabajado con modelos ML y PNL durante los últimos 8 años, estábamos continuamente frustados con numerosas fallas ocultas en nuestros modelos que nos llevaron a construir Train. Taptrain se inició inicialmente como una herramienta de observabilidad ML con verificaciones para identificar la regresión en precisión.
Sin embargo, pronto lanzamos que los desarrolladores de LLM enfrenten un problema aún mayor: no hay una buena manera de medir la precisión de sus aplicaciones LLM, y mucho menos identificar la regresión.
También vimos el lanzamiento de Operai Evals, donde propusieron el uso de LLM para calificar las respuestas del modelo. Además, ganamos confianza para abordar esto después de leer cómo antrópico aprovecha RLAIF y se sumergió directamente en la investigación de evaluaciones de LLM (pronto estamos lanzando un depósito de investigaciones de evaluaciones impresionantes).
Entonces, venga hoy, Uptrain es nuestro intento de traer orden al caos de LLM y contribuir de nuevo a la comunidad. Si bien la mayoría de los desarrolladores aún dependen de la intuición y la producción de cambios rápidos al revisar un par de casos, hemos escuchado suficientes historias de regresión para creer que "evaluaciones y mejoras" serán una parte clave del ecosistema LLM a medida que el espacio madura.
Las evaluaciones robustas le permiten experimentar sistemáticamente con diferentes configuraciones y evitar cualquier regresión ayudando a seleccionar objetivamente la mejor opción.
Le ayuda a comprender a dónde van sus sistemas, encontrar las causas raíz y solucionarlos, mucho antes de que sus usuarios finales se quejen y potencialmente se agitan.
Las evaluaciones como la inyección rápida y la detección de jailbreak son esenciales para mantener la seguridad de sus aplicaciones LLM.
Las evaluaciones lo ayudan a proporcionar transparencia y generar confianza con sus usuarios finales, especialmente relevantes si está vendiendo a las empresas.
Entendemos que no hay una solución única para todos cuando se trata de evaluaciones. Cada vez más vemos el deseo de los desarrolladores de modificar el aviso de evaluación o el conjunto de opciones o los pocos ejemplos de disparos, etc. Creemos que la mejor experiencia de desarrollador radica en el código abierto, en lugar de exponer 20 parámetros diferentes.
Foster Innovation : The Field of LLM Evaluations y el uso de LLM-AS-A-Judge sigue siendo bastante incipiente. Vemos que ocurren muchas investigaciones emocionantes, casi a diario y ser de código abierto proporciona la plataforma adecuada a nosotros y a nuestra comunidad para implementar esas técnicas e innovar más rápido.
Nos esforzamos continuamente por mejorar el altrin, y hay varias formas en que puede contribuir:
Observe cualquier problema o área de mejora: si ve algo malo o tiene ideas para mejoras, cree un problema en nuestro repositorio de GitHub.
Contribuya directamente: si ve un problema, puede solucionar o tener mejoras en el código para sugerir, no dude en contribuir directamente al repositorio.
Solicite evaluaciones personalizadas: si su aplicación requiere una evaluación personalizada, háganoslo saber y la agregaremos al repositorio.
Integrar con sus herramientas: ¿Necesita integración con sus herramientas existentes? Alcance y trabajaremos en ello.
Asistencia con las evaluaciones: si necesita ayuda con las evaluaciones, publique su consulta en nuestro canal Slack y la resolveremos de inmediato.
Muestre su apoyo: Muestre su apoyo protagonizándonos en Github para rastrear nuestro progreso.
Corre la voz: si te gusta lo que hemos construido, ¡danos un agradecimiento en Twitter!
¡Sus contribuciones y apoyo son muy apreciados! Gracias por ser parte del viaje de Uptrain.
Este repositorio se publica bajo la licencia Apache 2.0 y estamos comprometidos a agregar más funcionalidades al repositorio de código abierto. También tenemos una versión administrada si solo desea una experiencia más sin duda. Reserve una llamada de demostración aquí.
Estamos construyendo Train en público. Ayúdanos a mejorar dando sus comentarios aquí .
Agradecemos las contribuciones a Taptrain. Consulte nuestra Guía de contribución para obtener más detalles.


