uptrain
v0.7.1

UpTrain是一个开源统一平台,用于评估和改善生成AI应用程序。我们为20多个预先配置的评估(涵盖语言,代码,嵌入用例)提供成绩,对故障案例进行根本原因分析,并就如何解决这些方法进行见解。

UpTrain Dashboard是一个基于Web的接口,可在本地计算机上运行。您可以使用仪表板评估LLM应用程序,查看结果并执行根本原因分析。

支持20多个预先配置的评估,例如响应完整性,事实准确性,上下文简洁等。

所有评估和分析在您的系统上本地运行,确保数据永远不会离开您的安全环境(使用模型分级检查时LLM调用除外)

尝试不同的嵌入模型,例如Text-Embedding-3 Large/SMALL,Text-Embedding-3-ADA,BAAI/BGE-LARGE等。UPTRAIN支持Huggingface模型,重复端点或托管在您的端点上的自定义模型。

您可以对用户反馈负面反馈或低评估分数的案例进行根本原因分析,以了解LLM管道的哪一部分给出次优效果。查看支持的RCA模板。

我们允许您使用任何OpenAI,人类,Mistral,Azure的OpenAI端点或托管在Enyscale上的开源LLM,以用作评估者。

UPTRAIN提供了许多自定义评估的方法。您可以自定义评估方法(思想链与分类链),很少的示例和方案描述。您还可以创建自定义评估器。
UPTRAIN仪表板是一个基于Web的接口,可让您评估LLM应用程序。这是一个自托管仪表板,可在本地机器上运行。您无需编写任何代码即可使用仪表板。您可以使用仪表板评估LLM应用程序,查看结果并执行根本原因分析。
在开始之前,请确保您在计算机上安装了Docker。如果没有,您可以从这里安装它。
以下命令将下载UpTrain仪表板并在本地计算机上启动。
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.sh注意: Uptrain仪表板当前使用Beta版本。我们希望您的反馈以改善它。
如果您是开发人员,并且想将上将评估集成到您的应用程序中,则可以使用UPTRAIN软件包。这允许采用一种评估您的LLM应用程序的更具程序化方法。
pip install uptrain您可以通过提供OpenAI API键来运行评估来评估您的响应。
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))如果您有任何疑问,请加入我们的懈怠社区
通过在此处预订电话直接与Uptrain的维护者交谈。

| 评估 | 描述 |
|---|---|
| 响应完整性 | 评分响应是否回答了指定问题的所有方面。 |
| 响应简洁 | 评分生成的响应是多么简洁,或者是否有任何其他无关的信息来提出问题。 |
| 响应相关性 | 等级生成的上下文与指定的问题有多重要。 |
| 响应有效性 | 等级是否有效,是否有效。如果响应包含任何信息,则认为响应是有效的。 |
| 响应一致性 | 等级与提出的问题以及所提供的上下文的响应有多一致。 |

| 评估 | 描述 |
|---|---|
| 上下文相关性 | 等级与指定问题的上下文有多么重要。 |
| 上下文利用 | 鉴于上下文中提供的信息,对所指定的问题的生成响应的完整程度。 |
| 事实准确性 | 成绩是实际上是正确的,并以所提供的上下文为基础。 |
| 上下文简洁 | 评估从原始上下文中引用的简洁上下文,以获取无关紧要的信息。 |
| 上下文重读 | 评估将重新计算上下文与原始上下文进行比较的效率。 |

| 评估 | 描述 |
|---|---|
| 语言特征 | 评分语言在响应中的质量和有效性,重点是清晰,连贯性,简洁性和整体交流等因素。 |
| 音调 | 评分生成的响应是否与所需角色的基调相匹配 |

| 评估 | 描述 |
|---|---|
| 代码幻觉 | 等级是基于上下文基础的生成响应中存在的代码。 |

| 评估 | 描述 |
|---|---|
| 用户满意度 | 评分用户的问题如何解决,并根据提供的对话评估他们的满意度。 |

| 评估 | 描述 |
|---|---|
| 自定义指南 | 允许您指定指南,并分级LLM在给出响应时遵守提供的指南。 |
| 自定义提示 | 允许您创建自己的评估集。 |

| 评估 | 描述 |
|---|---|
| 响应匹配 | 比较LLM与所提供的地面真相一致的响应对响应的良好状态。 |

| 评估 | 描述 |
|---|---|
| 提示注射 | 评分用户的提示是否试图使LLM揭示其系统提示。 |
| 越狱检测 | 评分用户的提示是尝试越狱的尝试(即产生非法或有害响应)。 |

| 评估 | 描述 |
|---|---|
| 子问题完整性 | 评估是否从用户查询中产生的所有子问题一起,涵盖用户查询的所有方面 |
| 多传奇准确性 | 评估生成的变体是否准确表示原始查询 |
| 评估框架 | LLM提供商 | LLM软件包 | 服务框架 | LLM可观察性 | 向量DBS |
|---|---|---|---|---|---|
| Openai Evals | Openai | Llamaindex | 霍拉马 | langfuse | QDRANT |
| azure | 一起 | Helicone | faiss | ||
| 克劳德 | 任何规模 | zeno | 色度 | ||
| Mistral | 复制 | ||||
| 拥抱面 |
更多的集成即将到来。如果您有特定的集成,请通过创建问题让我们知道。
最受欢迎的LLM如GPT-4,GPT-3.5-Turbo,Claude-2.1等是封闭消息,即通过API暴露,对引擎盖下发生的情况几乎没有可见性。据报道,有许多迅速漂移(或GPT-4变得懒惰)和研究工作探讨模型质量退化的研究。该基准是通过在固定数据集上评估其响应来跟踪模型行为的变化的尝试。
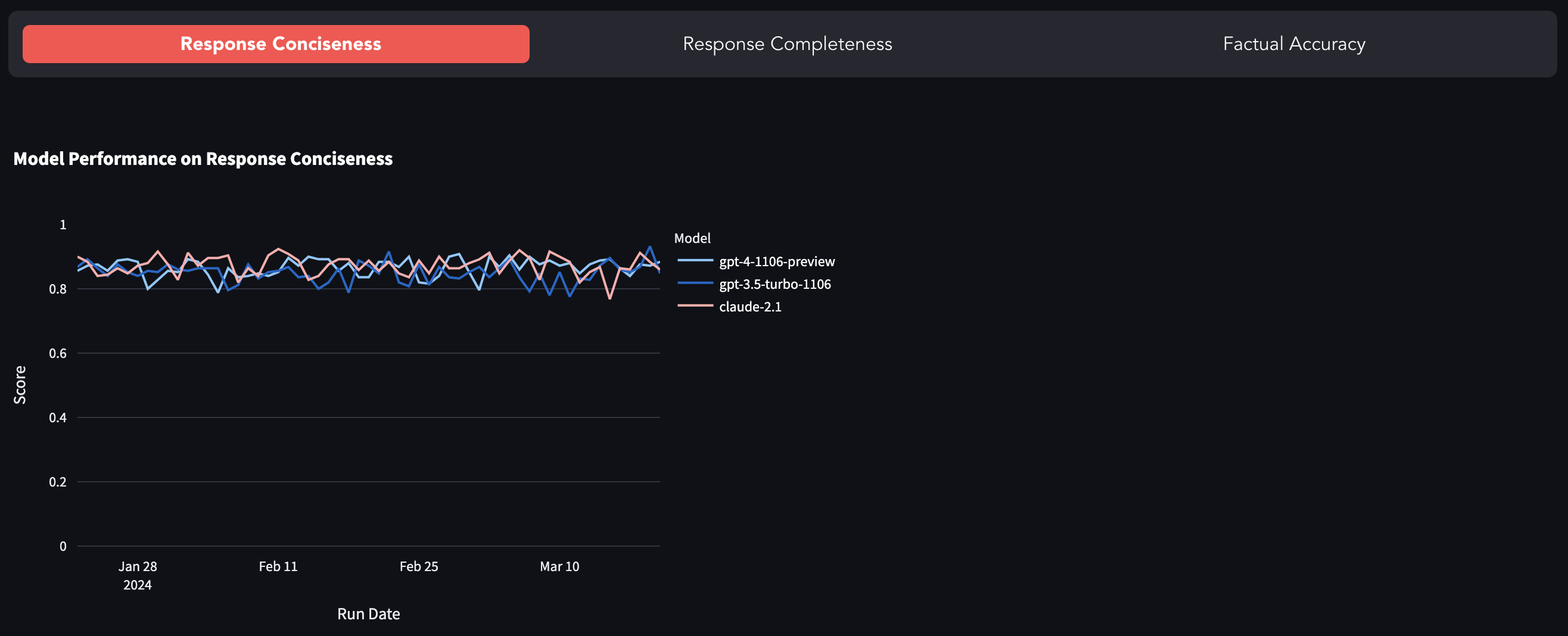
您可以在这里找到基准。
在过去的8年中,我们与ML和NLP模型合作过,在模型中,我们一直在不断地散布着许多隐藏的故障,从而导致我们建立了Uptrain。最初,UpTrain是作为ML可观察性工具开始的,该工具具有检查,以识别准确性的回归。
但是,我们很快发布了LLM开发人员面临更大的问题 - 没有一个很好的方法来衡量其LLM应用程序的准确性,更不用说识别回归了。
我们还看到了Openai Evals的释放,他们提出使用LLM来对模型响应进行评分。此外,我们在阅读了拟人化利用RLAIF并直接参与LLM评估研究之后,我们获得了对此的信心(我们很快就会释放出令人敬畏的评估研究的存储库)。
因此,今天来,Uptrain是我们为LLM混乱带来命令并向社区贡献的尝试。尽管大多数开发人员仍然通过审查几个案例来依靠直觉和生产迅速变化,但我们已经听到足够的回归故事来相信“评估和改进”将是LLM生态系统的关键部分,因为太空的成熟。
强大的评估使您可以系统地实验不同的配置,并通过帮助客观地选择最佳选择来防止任何回归。
它可以帮助您了解系统出错的位置,找到根本原因并修复它们 - 早在最终用户抱怨并可能耗尽之前。
及时注射和越狱检测等评估对于维持LLM应用程序的安全性至关重要。
评估可以帮助您提供透明度并与最终用户建立信任 - 如果您向企业出售,尤其是相关的。
我们了解到,在评估方面,没有一个大小的解决方案。我们越来越多地看到开发人员渴望修改评估提示或一组选择或少数镜头示例等。我们相信最好的开发人员体验在于开源,而不是暴露20个不同的参数。
促进创新:LLM评估领域和使用LLM-AS-A-Gudge的领域仍然很新生。我们几乎每天都会看到许多令人兴奋的研究正在进行,开源为我们和我们的社区提供了正确的平台,以实施这些技术并更快地进行创新。
我们一直在努力增强上升训练,您可以通过几种方式来贡献:
请注意任何要改进的问题或领域:如果您发现任何错误或有增强功能的想法,请在我们的GitHub存储库上创建一个问题。
直接贡献:如果您看到问题,则可以修复或进行改进以提出建议,请随时直接为存储库做出贡献。
请求自定义评估:如果您的应用程序需要量身定制的评估,请告诉我们,我们将其添加到存储库中。
与您的工具集成:需要与现有工具集成吗?伸出援手,我们将努力。
评估协助:如果您需要评估方面的帮助,请在我们的Slack频道上发布查询,我们将及时解决。
表示您的支持:通过在Github上主演以跟踪我们的进度,向您展示您的支持。
传播词:如果您喜欢我们建造的东西,请在Twitter上大喊大叫!
非常感谢您的贡献和支持!感谢您成为Uptrain旅程的一部分。
此存储库由Apache 2.0许可发布,我们致力于向Uptrain Opentrain开源存储库添加更多功能。如果您只想获得更多的驾驶体验,我们也有托管版本。请在此处预订演示电话。
我们正在公共场所建立上升趋势。通过在此处提供反馈来帮助我们改善。
我们欢迎对上升的贡献。请参阅我们的贡献指南以获取详细信息。


