uptrain
v0.7.1

Uptrain เป็นแพลตฟอร์มแบบครบวงจรโอเพ่นซอร์สเพื่อประเมินและปรับปรุงแอพพลิเคชั่น AI แบบกำเนิด เราให้คะแนนสำหรับการประเมินผลที่กำหนดไว้ล่วงหน้า 20+ ครั้ง (ครอบคลุมภาษา, รหัส, การฝังกรณีการใช้งาน), ดำเนินการวิเคราะห์สาเหตุที่แท้จริงเกี่ยวกับกรณีความล้มเหลวและให้ข้อมูลเชิงลึกเกี่ยวกับวิธีการแก้ไข

Uptrain Dashboard เป็นอินเทอร์เฟซบนเว็บที่ทำงานบน เครื่องในเครื่อง ของคุณ คุณสามารถใช้แดชบอร์ดเพื่อประเมินแอปพลิเคชัน LLM ของคุณดูผลลัพธ์และทำการวิเคราะห์สาเหตุที่แท้จริง

สนับสนุน การประเมินผลล่วงหน้า 20+ ครั้ง เช่นความสมบูรณ์ของการตอบสนองความถูกต้องตามข้อเท็จจริงความกระชับบริบท ฯลฯ

การประเมินและการวิเคราะห์ทั้งหมดทำงานในเครื่องในระบบของคุณเพื่อให้มั่นใจว่าข้อมูลไม่เคยออกจากสภาพแวดล้อมที่ปลอดภัยของคุณ (ยกเว้นการโทร LLM ในขณะที่ใช้การตรวจสอบการให้คะแนนแบบจำลอง)

การทดลองกับโมเดลการฝังที่แตกต่างกัน เช่นการฝังตัวข้อความ -3 ขนาดใหญ่/เล็ก, การฝังตัวข้อความ -3-ADA, BAAI/BGE-large ฯลฯ uptrain รองรับโมเดล HuggingFace, การทำซ้ำปลายทางหรือโมเดลที่กำหนดเองที่โฮสต์บนจุดสิ้นสุดของคุณ

คุณสามารถ ทำการวิเคราะห์สาเหตุที่แท้จริง ในกรณีที่มีความคิดเห็นเชิงลบของผู้ใช้หรือคะแนนการประเมินต่ำเพื่อทำความเข้าใจว่าส่วนใดของท่อ LLM ของคุณให้ผลลัพธ์ที่ไม่ดี ตรวจสอบเทมเพลต RCA ที่รองรับ

เราอนุญาตให้คุณใช้ OpenAI, มานุษยวิทยา, Mistral, จุดสิ้นสุดของ OpenAI ของ Azure หรือ LLM โอเพนซอร์ซที่โฮสต์บน OneScale เพื่อใช้เป็นผู้ประเมิน

Uptrain มีวิธี การปรับแต่งการประเมิน มากมาย คุณสามารถปรับแต่งวิธีการประเมินผล (ห่วงโซ่ของความคิดเทียบกับการจำแนก) ตัวอย่างไม่กี่นัดและคำอธิบายสถานการณ์ คุณยังสามารถสร้างผู้ประเมินที่กำหนดเอง
แผงควบคุม Uptrain เป็นอินเทอร์เฟซบนเว็บที่ช่วยให้คุณประเมินแอปพลิเคชัน LLM ของคุณ มันเป็นแดชบอร์ดโฮสต์ตัวเองที่ทำงานบนเครื่องในพื้นที่ของคุณ คุณไม่จำเป็นต้องเขียนรหัสใด ๆ เพื่อใช้แดชบอร์ด คุณสามารถใช้แดชบอร์ดเพื่อประเมินแอปพลิเคชัน LLM ของคุณดูผลลัพธ์และทำการวิเคราะห์สาเหตุที่แท้จริง
ก่อนที่คุณจะเริ่มตรวจสอบให้แน่ใจว่าคุณติดตั้ง Docker บนเครื่องของคุณ ถ้าไม่คุณสามารถติดตั้งได้จากที่นี่
คำสั่งต่อไปนี้จะดาวน์โหลดแดชบอร์ด Uptrain และเริ่มต้นบนเครื่องในเครื่องของคุณ
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.shหมายเหตุ: Dashboard Uptrain อยู่ใน รุ่นเบต้า เราจะรักความคิดเห็นของคุณเพื่อปรับปรุง
หากคุณเป็นนักพัฒนาซอฟต์แวร์และต้องการรวมการประเมินผลขั้นสูงเข้ากับแอปพลิเคชันของคุณคุณสามารถใช้แพ็คเกจ Uptrain ได้ สิ่งนี้ช่วยให้วิธีการเขียนโปรแกรมมากขึ้นในการประเมินแอปพลิเคชัน LLM ของคุณ
pip install uptrainคุณสามารถประเมินคำตอบของคุณผ่านเวอร์ชันโอเพนซอร์ซโดยการจัดหาคีย์ OpenAI API ของคุณเพื่อเรียกใช้การประเมินผล
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))หากคุณมีคำถามใด ๆ โปรดเข้าร่วมชุมชน Slack ของเรา
พูดโดยตรงกับผู้ดูแลระบบ uptrain โดยจองสายที่นี่

| การประเมิน | คำอธิบาย |
|---|---|
| ความสมบูรณ์ของการตอบสนอง | เกรดว่าการตอบสนองได้ตอบทุกแง่มุมของคำถามที่ระบุหรือไม่ |
| การตอบสนองกระชับ | เกรดว่าการตอบสนองที่สร้างขึ้นนั้นเป็นอย่างไรหรือมีข้อมูลที่ไม่เกี่ยวข้องเพิ่มเติมสำหรับคำถามที่ถาม |
| ความเกี่ยวข้องการตอบสนอง | เกรดความเกี่ยวข้องกับบริบทที่สร้างขึ้นคือคำถามที่ระบุไว้ |
| ความถูกต้องในการตอบสนอง | เกรดหากการตอบสนองที่สร้างขึ้นนั้นถูกต้องหรือไม่ การตอบสนองจะถูกพิจารณาว่าถูกต้องหากมีข้อมูลใด ๆ |
| การตอบสนองความสอดคล้อง | เกรดการตอบสนองที่สอดคล้องกับคำถามที่ถามเช่นเดียวกับบริบทที่ให้ไว้ |

| การประเมิน | คำอธิบาย |
|---|---|
| ความเกี่ยวข้องกับบริบท | เกรดความเกี่ยวข้องกับบริบทเป็นคำถามที่ระบุไว้อย่างไร |
| การใช้บริบท | เกรดการตอบสนองที่สร้างขึ้นนั้นสมบูรณ์สำหรับคำถามที่ระบุไว้โดยให้ข้อมูลที่ให้ไว้ในบริบท |
| ความถูกต้องตามข้อเท็จจริง | เกรดว่าการตอบสนองที่สร้างขึ้นนั้นถูกต้องตามความเป็นจริงและมีพื้นฐานมาจากบริบทที่ให้ไว้หรือไม่ |
| บริบทกระชับ | ประเมินบริบทที่กระชับที่อ้างถึงจากบริบทดั้งเดิมสำหรับข้อมูลที่ไม่เกี่ยวข้อง |
| การเปลี่ยนบริบท | ประเมินว่าบริบทที่มีประสิทธิภาพถูกเปรียบเทียบกับบริบทดั้งเดิมอย่างไร |

| การประเมิน | คำอธิบาย |
|---|---|
| คุณสมบัติภาษา | ให้คะแนนคุณภาพและประสิทธิผลของภาษาในการตอบสนองโดยมุ่งเน้นไปที่ปัจจัยต่าง ๆ เช่นความชัดเจนการเชื่อมโยงกันความกระชับและการสื่อสารโดยรวม |
| โทนเสียง | คะแนนว่าการตอบสนองที่สร้างขึ้นนั้นตรงกับน้ำเสียงของบุคคลที่ต้องการหรือไม่ |

| การประเมิน | คำอธิบาย |
|---|---|
| ภาพหลอนรหัส | เกรดว่ารหัสที่มีอยู่ในการตอบสนองที่สร้างขึ้นนั้นมีพื้นฐานมาจากบริบทหรือไม่ |

| การประเมิน | คำอธิบาย |
|---|---|
| ความพึงพอใจของผู้ใช้ | ให้คะแนนความกังวลของผู้ใช้ได้รับการแก้ไขและประเมินความพึงพอใจของพวกเขาตามการสนทนาที่ให้ไว้ |

| การประเมิน | คำอธิบาย |
|---|---|
| แนวทางที่กำหนดเอง | ช่วยให้คุณระบุแนวทางและให้คะแนนว่า LLM ปฏิบัติตามแนวทางที่ให้ไว้ได้ดีเพียงใดเมื่อให้การตอบกลับ |
| พรอมต์แบบกำหนดเอง | ช่วยให้คุณสร้างชุดการประเมินของคุณเอง |

| การประเมิน | คำอธิบาย |
|---|---|
| การจับคู่การตอบสนอง | เปรียบเทียบและให้คะแนนว่าการตอบสนองที่สร้างขึ้นโดย LLM นั้นสอดคล้องกับความจริงพื้นฐานที่ดีเพียงใด |

| การประเมิน | คำอธิบาย |
|---|---|
| ฉีดทันที | เกรดว่าพรอมต์ของผู้ใช้เป็นความพยายามที่จะทำให้ LLM เปิดเผยพร้อมกับระบบของระบบหรือไม่ |
| การตรวจจับการแหกคุก | เกรดไม่ว่าพรอมต์ของผู้ใช้จะเป็นความพยายามในการแหกคุก (เช่นสร้างการตอบกลับที่ผิดกฎหมายหรือเป็นอันตราย) |

| การประเมิน | คำอธิบาย |
|---|---|
| ความสมบูรณ์แบบของคำถามย่อย | ประเมินว่าคำถามย่อยทั้งหมดที่สร้างขึ้นจากแบบสอบถามของผู้ใช้นำมารวมกันครอบคลุมทุกด้านของแบบสอบถามของผู้ใช้หรือไม่ |
| ความแม่นยำหลายคำถาม | ประเมินว่าตัวแปรที่สร้างขึ้นอย่างถูกต้องแสดงถึงการสืบค้นต้นฉบับหรือไม่ |
| เฟรมเวิร์กประเมิน | ผู้ให้บริการ LLM | แพ็คเกจ LLM | เฟรมเวิร์กที่ให้บริการ | ความสามารถในการสังเกต LLM | DBS เวกเตอร์ |
|---|---|---|---|---|---|
| Openai Evals | Openai | llamainedex | โอลลา | Langfuse | qdrant |
| สีฟ้า | AI ร่วมกัน | helicone | คน | ||
| ไคลด์ | ทุกอย่าง | เซโนะ | โครมา | ||
| ผิดพลาด | ทำซ้ำ | ||||
| กอด |
การบูรณาการเพิ่มเติมกำลังจะมาเร็ว ๆ นี้ หากคุณมีการบูรณาการเฉพาะในใจโปรดแจ้งให้เราทราบโดยการสร้างปัญหา
LLM ที่ได้รับความนิยมมากที่สุดเช่น GPT-4, GPT-3.5-turbo, Claude-2.1 ฯลฯ เป็นแหล่งปิดคือการเปิดเผยผ่าน API ที่มีทัศนวิสัยน้อยมากในสิ่งที่เกิดขึ้นภายใต้ประทุน มีการรายงานหลายครั้งของการดริฟท์ที่รวดเร็ว (หรือ GPT-4 กลายเป็นขี้เกียจ) และงานวิจัยสำรวจการเสื่อมสภาพของคุณภาพของแบบจำลอง เกณฑ์มาตรฐานนี้เป็นความพยายามในการติดตามการเปลี่ยนแปลงพฤติกรรมของโมเดลโดยการประเมินการตอบสนองในชุดข้อมูลคงที่
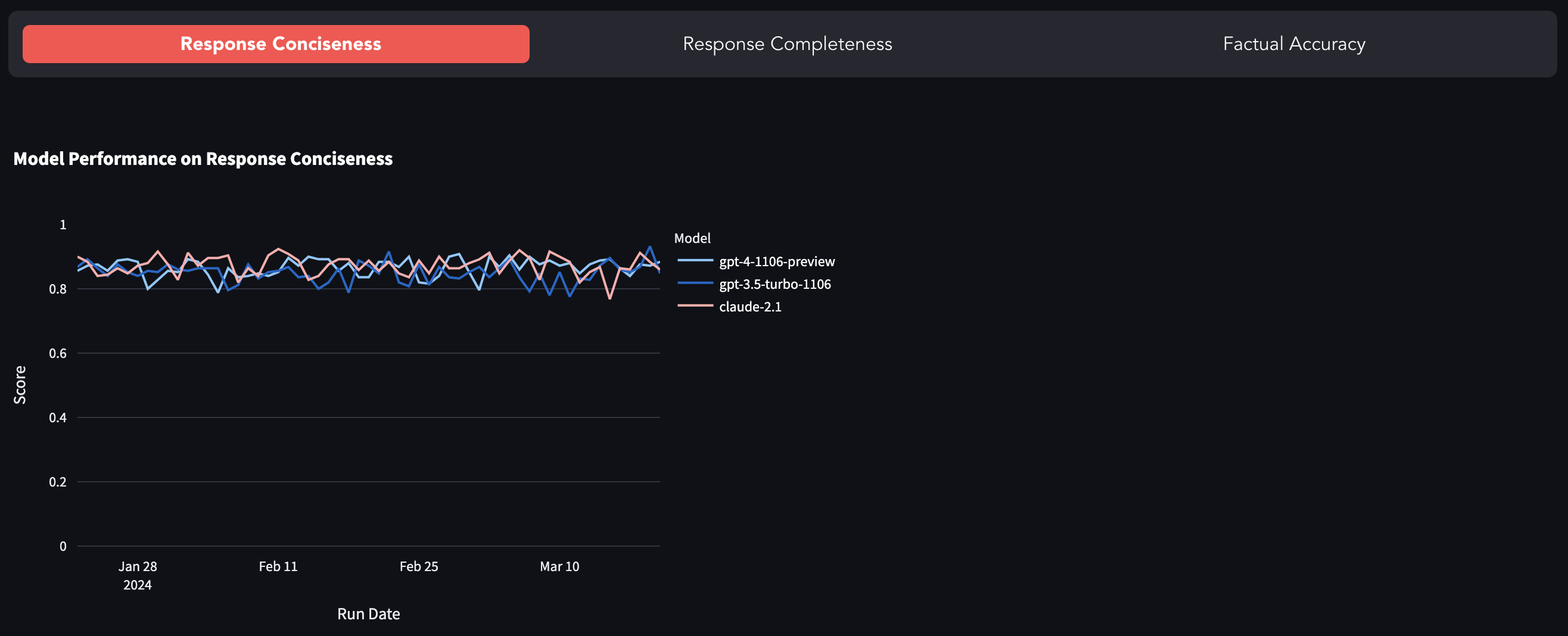
คุณสามารถค้นหาเกณฑ์มาตรฐานได้ที่นี่
หลังจากทำงานกับโมเดล ML และ NLP ในช่วง 8 ปีที่ผ่านมาเราได้รับความนิยมอย่างต่อเนื่องกับความล้มเหลวที่ซ่อนอยู่มากมายในโมเดลของเราซึ่งนำไปสู่การสร้างความตื่นเต้น uptrain เริ่มต้นในขั้นต้นเป็นเครื่องมือการสังเกต ML พร้อมการตรวจสอบเพื่อระบุการถดถอยในความแม่นยำ
อย่างไรก็ตามในไม่ช้าเราก็ปล่อยตัวว่านักพัฒนา LLM ประสบปัญหาที่ยิ่งใหญ่กว่า - ไม่มีวิธีที่ดีในการวัดความแม่นยำของแอปพลิเคชัน LLM ของพวกเขา
นอกจากนี้เรายังเห็นการเปิดตัวของ Openai Evals ซึ่งพวกเขาเสนอการใช้ LLM เพื่อให้การตอบสนองแบบจำลอง นอกจากนี้เรายังได้รับความมั่นใจในการเข้าหาสิ่งนี้หลังจากอ่านว่ามานุษยวิทยาใช้ประโยชน์จาก RLAIF และพุ่งเข้าหาการวิจัยการประเมิน LLM ได้อย่างไร
ดังนั้นมาวันนี้ Uptrain คือความพยายามของเราที่จะนำคำสั่งให้ LLM Chaos และมีส่วนร่วมกลับไปสู่ชุมชน ในขณะที่นักพัฒนาส่วนใหญ่ยังคงพึ่งพาสัญชาตญาณและการเปลี่ยนแปลงการเปลี่ยนแปลงโดยการตรวจสอบสองกรณีเราได้ยินเรื่องราวการถดถอยเพียงพอที่จะเชื่อว่า "การประเมินและการปรับปรุง" จะเป็นส่วนสำคัญของระบบนิเวศ LLM เมื่อพื้นที่เติบโต
การประเมินที่แข็งแกร่งช่วยให้คุณสามารถทดสอบการกำหนดค่าที่แตกต่างกันอย่างเป็นระบบและป้องกันการถดถอยใด ๆ โดยช่วยเลือกตัวเลือกที่ดีที่สุดอย่างเป็นกลาง
มันช่วยให้คุณเข้าใจว่าระบบของคุณผิดพลาดที่ไหนค้นหาสาเหตุที่แท้จริงและแก้ไข - นานก่อนที่ผู้ใช้ปลายทางของคุณจะบ่นและอาจทำให้เกิดการปั่นป่วน
การประเมินเช่นการฉีดทันทีและการตรวจจับการแหกคุกเป็นสิ่งจำเป็นในการรักษาความปลอดภัยและความปลอดภัยของแอปพลิเคชัน LLM ของคุณ
การประเมินผลช่วยให้คุณให้ความโปร่งใสและสร้างความไว้วางใจกับผู้ใช้ปลายทางของคุณโดยเฉพาะอย่างยิ่งที่เกี่ยวข้องหากคุณขายให้กับองค์กร
เราเข้าใจว่า ไม่มีวิธีแก้ปัญหาขนาดเดียวที่เหมาะกับทุกคน เมื่อมันมาถึงการประเมิน เราเห็นความปรารถนาจากนักพัฒนามากขึ้นในการปรับเปลี่ยนพรอมต์การประเมินหรือชุดของตัวเลือกหรือตัวอย่างช็อตไม่กี่ตัวอย่าง ฯลฯ เราเชื่อว่าประสบการณ์นักพัฒนาที่ดีที่สุดอยู่ในโอเพ่นซอร์สแทนที่จะเปิดเผยพารามิเตอร์ที่แตกต่างกัน 20 พารามิเตอร์
นวัตกรรมอุปถัมภ์ : สาขาการประเมิน LLM และการใช้ LLM-as-a-Judge ยังคงเป็นที่ตั้งของค่อนข้างค่อนข้าง เราเห็นการวิจัยที่น่าตื่นเต้นเกิดขึ้นเกือบทุกวันและการเป็นโอเพนซอร์ซเป็นแพลตฟอร์มที่เหมาะสมสำหรับเราและชุมชนของเราในการใช้เทคนิคเหล่านั้นและสร้างสรรค์สิ่งใหม่ ๆ เร็วขึ้น
เรามุ่งมั่นอย่างต่อเนื่องเพื่อเพิ่มความก้าวหน้าและมีหลายวิธีที่คุณสามารถมีส่วนร่วม:
สังเกตปัญหาหรือพื้นที่ใด ๆ สำหรับการปรับปรุง: หากคุณเห็นสิ่งผิดปกติหรือมีแนวคิดสำหรับการปรับปรุงโปรดสร้างปัญหาเกี่ยวกับที่เก็บ GitHub ของเรา
มีส่วนร่วมโดยตรง: หากคุณเห็นปัญหาคุณสามารถแก้ไขหรือมีการปรับปรุงรหัสเพื่อแนะนำอย่าลังเลที่จะมีส่วนร่วมโดยตรงกับที่เก็บ
ขอการประเมินที่กำหนดเอง: หากแอปพลิเคชันของคุณต้องการการประเมินที่เหมาะสมแจ้งให้เราทราบและเราจะเพิ่มลงในที่เก็บ
รวมเข้ากับเครื่องมือของคุณ: ต้องการการรวมเข้ากับเครื่องมือที่มีอยู่ของคุณหรือไม่? เอื้อมมือออกไปและเราจะดำเนินการกับมัน
ความช่วยเหลือเกี่ยวกับการประเมินผล: หากคุณต้องการความช่วยเหลือในการประเมินผลโพสต์ข้อความค้นหาของคุณในช่อง Slack ของเราและเราจะแก้ไขได้ทันที
แสดงการสนับสนุนของคุณ: แสดงการสนับสนุนของคุณโดยนำแสดงโดยเราใน GitHub เพื่อติดตามความคืบหน้าของเรา
กระจายคำว่า: ถ้าคุณชอบสิ่งที่เราสร้างขึ้นให้เราตะโกนบน Twitter!
การมีส่วนร่วมและการสนับสนุนของคุณได้รับการชื่นชมอย่างมาก! ขอบคุณที่เป็นส่วนหนึ่งของการเดินทางของ Uptrain
repo นี้ได้รับการเผยแพร่ภายใต้ใบอนุญาต Apache 2.0 และเรามุ่งมั่นที่จะเพิ่มฟังก์ชันการทำงานมากขึ้นใน repo โอเพนซอร์ส uptrain นอกจากนี้เรายังมีเวอร์ชันที่มีการจัดการหากคุณต้องการประสบการณ์การใช้งานมากขึ้น กรุณาจองการสาธิตที่นี่
เรากำลังสร้าง uptrain ในที่สาธารณะ ช่วยเราปรับปรุงโดยให้ความคิดเห็นของคุณ ที่นี่
เรายินดีต้อนรับการมีส่วนร่วมในการก้าวไปข้างหน้า โปรดดูคู่มือการบริจาคของเราสำหรับรายละเอียด


