uptrain
v0.7.1

UPTRAIN ist eine einheitliche Open-Source-Plattform zur Bewertung und Verbesserung der generativen KI-Anwendungen. Wir bieten Noten für mehr als 20 vorkonfigurierte Bewertungen (Abdeckung von Sprache, Code, Einbettung von Anwendungsfällen).

Upprain Dashboard ist eine webbasierte Oberfläche, die auf Ihrem lokalen Computer ausgeführt wird. Sie können das Dashboard verwenden, um Ihre LLM -Anwendungen zu bewerten, die Ergebnisse anzusehen und eine Ursachenanalyse durchzuführen.

Unterstützung für mehr als 20 vorkonfigurierte Bewertungen wie Reaktions Vollständigkeit, sachliche Genauigkeit, Kontextversicht usw.

Alle Bewertungen und Analysen werden lokal in Ihrem System ausgeführt, um sicherzustellen, dass die Daten niemals Ihre sichere Umgebung verlassen (mit Ausnahme von LLM -Aufrufen bei der Verwendung von Modellabstufungsprüfungen).

Experimentieren Sie mit verschiedenen Einbettungsmodellen wie Text-Embedding-3-Large/Small, Text-Embedding-3-ada, Baai/BGE-Large usw. Der Aufwärtsprüfer unterstützt Umarmungsgesichtsmodelle, replizierte Endpunkte oder benutzerdefinierte Modelle, die auf Ihrem Endpunkt gehostet werden.

Sie können eine Ursachenanalyse in Fällen mit negativem Benutzer -Feedback oder niedrigen Bewertungswerten durchführen, um zu verstehen, welcher Teil Ihrer LLM -Pipeline suboptimale Ergebnisse liefert. Schauen Sie sich die unterstützten RCA -Vorlagen an.

Wir ermöglichen Ihnen, OpenAI-, Anthropic-, Mistral-, Azure-Endpunkte oder Open-Source-LLMs von Azure zu verwenden, die auf AnyScale gehostet werden, um als Bewerter verwendet zu werden.

UPRAIN bietet unzählige Möglichkeiten zum Anpassen von Bewertungen . Sie können die Bewertungsmethode (Kette von Denke vs Classify), wenige Beispiele und Szenarienbeschreibung anpassen. Sie können auch benutzerdefinierte Bewerter erstellen.
Das Upstrain-Dashboard ist eine webbasierte Oberfläche, mit der Sie Ihre LLM-Anwendungen bewerten können. Es ist ein selbst gehostetes Armaturenbrett, das auf Ihrer lokalen Maschine ausgeführt wird. Sie müssen keinen Code schreiben, um das Dashboard zu verwenden. Sie können das Dashboard verwenden, um Ihre LLM -Anwendungen zu bewerten, die Ergebnisse anzusehen und eine Ursachenanalyse durchzuführen.
Stellen Sie vor Beginn sicher, dass Sie Docker auf Ihrem Computer installiert haben. Wenn nicht, können Sie es von hier aus installieren.
Die folgenden Befehle laden das Upstrain -Dashboard herunter und starten es auf Ihrem lokalen Computer.
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.shHINWEIS: UPRAIN Dashboard befindet sich derzeit in der Beta -Version . Wir würden Ihr Feedback lieben, um es zu verbessern.
Wenn Sie Entwickler sind und Up -Strain -Bewertungen in Ihre Anwendung integrieren möchten, können Sie das UPRAIN -Paket verwenden. Dies ermöglicht eine programmatischere Möglichkeit, Ihre LLM -Anwendungen zu bewerten.
pip install uptrainSie können Ihre Antworten über die Open-Source-Version bewerten, indem Sie Ihren OpenAI-API-Schlüssel zur Ausführung von Bewertungen bereitstellen.
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))Wenn Sie Fragen haben, nehmen Sie bitte unserer Slack -Community bei
Sprechen Sie direkt mit den Betreuungsbetriebsbädern, indem Sie hier einen Anruf buchen.

| Bewerten | Beschreibung |
|---|---|
| Reaktion Vollständigkeit | Noten, ob die Antwort alle Aspekte der angegebenen Frage beantwortet hat. |
| Reaktionsgeschwindigkeit | Grade Wie präzise die generierte Antwort ist oder ob zusätzliche irrelevante Informationen für die gestellte Frage enthalten. |
| Antwortrelevanz | Noten Wie relevant der generierte Kontext für die angegebene Frage war. |
| Antwortgültigkeit | Noten, wenn die generierte Antwort gültig ist oder nicht. Eine Antwort wird als gültig angesehen, wenn sie Informationen enthält. |
| Antwortkonsistenz | Grade, wie konsistent die Antwort mit der gestellten Frage sowie mit dem bereitgestellten Kontext ist. |

| Bewerten | Beschreibung |
|---|---|
| Kontextrelevanz | Noten Wie relevant der Kontext für die angegebene Frage war. |
| Kontextnutzung | Noten Wie vollständig die generierte Antwort für die angegebene Frage angesichts der im Kontext angegebenen Informationen war. |
| Sachliche Genauigkeit | Noten, ob die erzeugte Antwort sachlich korrekt ist und durch den bereitgestellten Kontext geerdet ist. |
| Kontextversicht | Bewertet den prägnanten Kontext, der aus einem ursprünglichen Kontext für irrelevante Informationen zitiert wird. |
| Kontext -Wiederbelebung | Bewertet, wie effizient der erneute Kontext mit dem ursprünglichen Kontext verglichen wird. |

| Bewerten | Beschreibung |
|---|---|
| Sprachmerkmale | Noten die Qualität und Wirksamkeit der Sprache in einer Reaktion und konzentriert sich auf Faktoren wie Klarheit, Kohärenz, SUKTIVE und allgemeine Kommunikation. |
| Tonalität | Noten, ob die generierte Antwort mit dem Ton der erforderlichen Person übereinstimmt |

| Bewerten | Beschreibung |
|---|---|
| Code -Halluzination | Noten, ob der in der generierte Antwort vorhandene Code durch den Kontext begründet ist. |

| Bewerten | Beschreibung |
|---|---|
| Benutzerzufriedenheit | Noten Wie gut die Bedenken des Benutzers angesprochen werden, und bewertet ihre Zufriedenheit auf der Grundlage der bereitgestellten Konversation. |

| Bewerten | Beschreibung |
|---|---|
| Benutzerdefinierte Richtlinie | Ermöglicht Ihnen eine Richtlinie und Noten an, wie gut der LLM bei der Angabe einer Antwort an der angegebenen Richtlinie haftet. |
| Benutzerdefinierte Eingabeaufforderungen | Ermöglicht Ihnen, Ihre eigenen Bewertungen zu erstellen. |

| Bewerten | Beschreibung |
|---|---|
| Reaktionsanpassung | Vergleicht und nimmt, wie gut die von der LLM erzeugte Antwort mit der bereitgestellten Grundwahrheit übereinstimmt. |

| Bewerten | Beschreibung |
|---|---|
| Sofortige Injektion | Noten, ob die Eingabeaufforderung des Benutzers ein Versuch ist, das LLM seine Systemaufforderungen anzuzeigen. |
| Jailbreak -Erkennung | Noten, ob die Eingabeaufforderung des Benutzers ein Versuch, Jailbreak zu besitzen (dh generieren illegale oder schädliche Antworten). |

| Bewerten | Beschreibung |
|---|---|
| Vollständigkeit der Unterablagerung | Bewerten Sie, ob alle Unterfragen, die aus der Abfrage eines Benutzers generiert wurden, zusammen alle Aspekte der Abfrage des Benutzers abdecken oder nicht |
| Multi-Quer-Genauigkeit | Bewerten Sie, ob die generierten Varianten die ursprüngliche Abfrage genau darstellen |
| Eval -Frameworks | LLM -Anbieter | LLM -Pakete | Servierrahmen | LLM -Beobachtbarkeit | Vektor DBS |
|---|---|---|---|---|---|
| Openai Evals | Openai | Llamaindex | Ollama | Langfuse | Qdrant |
| Azurblau | Zusammen ai | Helikon | Faiss | ||
| Claude | AnyScale | Zeno | Chroma | ||
| Mistral | Replizieren | ||||
| Umarmung |
Weitere Integrationen kommen in Kürze. Wenn Sie eine bestimmte Integration im Auge haben, teilen Sie uns dies bitte mit, indem Sie ein Problem erstellen.
Die beliebtesten LLMs wie GPT-4, GPT-3,5-Turbo, Claude-2.1 usw. sind geschlossen, dh über eine API mit nur sehr geringen Sichtbarkeit auf das, was unter der Motorhaube passiert. Es gibt viele gemeldete Fälle von sofortiger Drift (oder GPT-4 werden faul) und Forschungsarbeiten, die die Verschlechterung der Modellqualität untersuchen. Dieser Benchmark ist ein Versuch, die Änderung des Modellverhaltens durch Bewertung seiner Antwort auf einem festen Datensatz zu verfolgen.
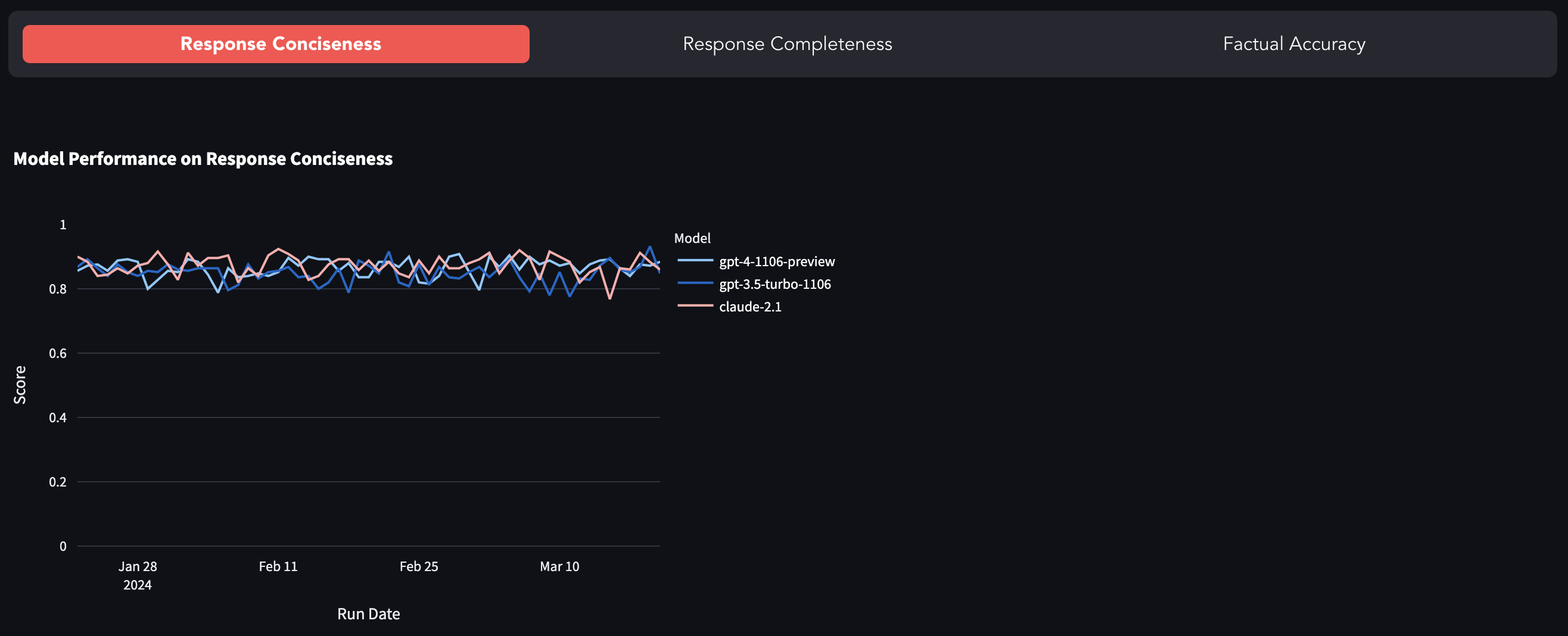
Hier finden Sie den Benchmark.
Nachdem wir in den letzten 8 Jahren mit ML- und NLP -Modellen zusammengearbeitet hatten, waren wir mit zahlreichen verborgenen Fehlern in unseren Modellen kontinuierlich verwirrt, was dazu führte, dass wir auf dem Gebäude aufgebaut wurden. Der Upstrang wurde zunächst als ML -Beobachtbarkeitsinstrument mit Überprüfungen zur Ermittlung der Regression in der Genauigkeit begonnen.
Wir haben jedoch bald veröffentlicht, dass LLM -Entwickler ein noch größeres Problem haben - es gibt keine gute Möglichkeit, die Genauigkeit ihrer LLM -Anwendungen zu messen, geschweige denn die Regression zu identifizieren.
Wir haben auch die Veröffentlichung von OpenAI Evals gesehen, wo sie die Verwendung von LLMs vorgeschlagen haben, um die Modellantworten zu bewerten. Darüber hinaus haben wir das Vertrauen gewonnen, dies zu nähern, nachdem wir gelesen hatten, wie anthropisch RLAIF nutzt und direkt in die LLM -Bewertungsforschung eintauchte (wir veröffentlichen bald ein Repository der fantastischen Bewertungsforschung).
Kommen Sie noch heute, Upstrain ist unser Versuch, LLM Chaos zu bestellen und in die Gemeinschaft zurückzukehren. Während die Mehrheit der Entwickler immer noch auf Angriffe intuitioniert und produziert wird, indem sie einige Fälle überprüfen, haben wir genug Regressionsgeschichten gehört, um zu glauben, dass "Bewertungen und Verbesserungen" ein wesentlicher Bestandteil des LLM -Ökosystems sein werden, wenn der Raum reift.
Durch robuste Bewertungen können Sie systematisch mit unterschiedlichen Konfigurationen experimentieren und Regressionen verhindern, indem Sie objektiv die beste Wahl auswählen.
Es hilft Ihnen zu verstehen, wo Ihre Systeme schief gehen, die Grundursachen (n) finden und sie beheben - lange bevor sich Ihre Endbenutzer beschweren und möglicherweise herausholen.
Bewertungen wie eine schnelle Injektion und Jailbreak -Erkennung sind wichtig, um die Sicherheit Ihrer LLM -Anwendungen aufrechtzuerhalten.
Bewertungen helfen Ihnen dabei, Transparenz bereitzustellen und Vertrauen bei Ihren Endbenutzern aufzubauen - insbesondere relevant, wenn Sie an Unternehmen verkaufen.
Wir verstehen, dass es bei Bewertungen keine einheitliche Lösung gibt. Wir sehen zunehmend den Wunsch von Entwicklern, die Bewertungsaufforderung oder die Reihe von Auswahlmöglichkeiten oder die wenigen Schussbeispiele usw. zu ändern. Wir glauben, dass die beste Entwicklererfahrung in Open-Source liegt, anstatt 20 verschiedene Parameter aufzudecken.
Foster Innovation : Das Gebiet der LLM-Bewertungen und die Verwendung von LLM-AS-A-Judge ist immer noch ziemlich entstehen. Wir sehen viele aufregende Forschungen, fast täglich, und Open-Source bietet uns und unserer Community die richtige Plattform, um diese Techniken umzusetzen und schneller zu innovieren.
Wir bemühen uns kontinuierlich, die Aufwärtstrag zu verbessern, und es gibt verschiedene Möglichkeiten, wie Sie einen Beitrag leisten können:
Beachten Sie alle Probleme oder Bereiche für Verbesserungen: Wenn Sie etwas falsch machen oder Ideen für Verbesserungen haben, erstellen Sie bitte ein Problem in unserem Github -Repository.
Direkt beitragen: Wenn Sie ein Problem sehen, können Sie Code -Verbesserungen beheben oder vorschlagen, um es vorzuschlagen, direkt zum Repository beizutragen.
Fordern Sie benutzerdefinierte Bewertungen an: Wenn für Ihre Bewerbung eine maßgeschneiderte Bewertung erforderlich ist, teilen Sie uns es mit, und wir werden sie dem Repository hinzufügen.
Integrieren Sie sich in Ihre Tools: Benötigen Sie eine Integration in Ihre vorhandenen Tools? Greifen Sie nach, und wir werden daran arbeiten.
Unterstützung bei Bewertungen: Wenn Sie Unterstützung bei Bewertungen benötigen, veröffentlichen Sie Ihre Abfrage auf unserem Slack -Kanal und wir werden sie umgehend beheben.
Zeigen Sie Ihre Unterstützung: Zeigen Sie Ihre Unterstützung, indem Sie uns auf Github aufnehmen, um unsere Fortschritte zu verfolgen.
Verbreiten Sie das Wort: Wenn Ihnen das gefällt, was wir gebaut haben, geben Sie uns einen Schrei auf Twitter!
Ihre Beiträge und Ihre Unterstützung werden sehr geschätzt! Vielen Dank, dass Sie ein Teil der Reise von Upstrain sind.
Dieses Repo wird unter Apache 2.0-Lizenz veröffentlicht und wir sind verpflichtet, dem Upstrain Open-Source-Repo weitere Funktionen hinzuzufügen. Wir haben auch eine verwaltete Version, wenn Sie nur ein Handelserlebnis wünschen. Bitte buchen Sie hier einen Demo -Anruf.
Wir bauen in der Öffentlichkeit auf. Helfen Sie uns, sich zu verbessern, indem Sie Ihr Feedback hier geben.
Wir begrüßen Beiträge zum Upstrain. Weitere Informationen finden Sie in unserem Beitragsanleitung.


