uptrain
v0.7.1

Uptrain -это унифицированная платформа с открытым исходным кодом для оценки и улучшения генеративных приложений искусственного интеллекта. Мы предоставляем оценки для более чем 20+ предварительных оценок (охватывающих язык, код, внедрение случаев использования), выполняем анализ первопричин в случаях сбоев и даем представление о том, как их разрешить.

Dashboard Uptrain-это веб-интерфейс, который работает на вашей локальной машине . Вы можете использовать приборную панель для оценки ваших приложений LLM, просмотра результатов и провести анализ основной причины.

Поддержка 20+ предварительно настроенных оценок , таких как полнота ответа, фактическая точность, контекст и т. Д.

Все оценки и анализ проводятся локально в вашей системе, гарантируя, что данные никогда не покидают вашу безопасную среду (за исключением вызовов LLM при использовании проверок на графики модели)

Экспериментируйте с различными моделями встраивания , такими как текстовое вмазвание-3-широкое/малое, текстовое вмазвание-3-Ada, BAAI/BGE-Large и т. Д.

Вы можете выполнить анализ основной причины по случаям с отрицательными отзывами пользователя или низкими оценками оценки, чтобы понять, какая часть вашего трубопровода LLM дает неоптимальные результаты. Проверьте поддерживаемые шаблоны RCA.

Мы позволяем вам использовать любой из OpenAI, антропных, Mistral, конечных точек Azure OpenAI или LLM, размещенных на AntyScale для использования в качестве оценщиков.

Uptrain предоставляет множество способов настройки оценки . Вы можете настроить метод оценки (цепочка мышления против классификации), несколько выстрелов и описание сценариев. Вы также можете создать пользовательских оценщиков.
Дополнительная панель Uptrain-это веб-интерфейс, который позволяет вам оценивать ваши приложения LLM. Это самостоятельная панель панели, которая работает на вашей локальной машине. Вам не нужно писать какой -либо код, чтобы использовать панель инструментов. Вы можете использовать приборную панель для оценки ваших приложений LLM, просмотра результатов и провести анализ основной причины.
Прежде чем начать, убедитесь, что на вашем компьютере установлен Docker. Если нет, вы можете установить его отсюда.
Следующие команды будут загружать панель мониторинга Uptrain и запустить ее на вашей локальной машине.
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.shПримечание. Дополнительная панель Uptrain в настоящее время находится в бета -версии . Мы хотели бы, чтобы ваш отзыв улучшил его.
Если вы являетесь разработчиком и хотите интегрировать оценки восходящих в своем приложении, вы можете использовать пакет восходящих. Это позволяет более программно оценить ваши приложения LLM.
pip install uptrainВы можете оценить свои ответы с помощью версии с открытым исходным кодом, предоставив свой ключ API OpenAI для проведения оценки.
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))Если у вас есть какие -либо вопросы, пожалуйста, присоединяйтесь к нашему сообществу Slack
Поговорите напрямую с содействиями восходящим перетком, забронируя здесь звонок.

| Оценка | Описание |
|---|---|
| Полнота ответа | Оценки независимо от того, ответил ли ответ на все аспекты указанного вопроса. |
| Ответ Краткость | Оценки, насколько краткий сгенерированный ответ или если он имеет какую -либо дополнительную не относящуюся к делу информации для заданного вопроса. |
| Ответ актуальность | Оценки, насколько актуальный был сгенерированный контекст для указанного вопроса. |
| Ответ достоверность | Оценки, если сгенерированный ответ действителен или нет. Ответ считается действительным, если он содержит какую -либо информацию. |
| Согласованность ответа | Оценки насколько последовательным ответом является заданный вопрос, а также с предоставленным контекстом. |

| Оценка | Описание |
|---|---|
| Контекст актуальности | Оценки, насколько актуален был контекст для указанного вопроса. |
| Использование контекста | Оценки насколько завершен сгенерированный ответ для указанного вопроса, учитывая информацию, представленную в контексте. |
| Фактическая точность | Оценки независимо от того, сгенерирован ли реакция, фактически правильным и основан на предоставленном контексте. |
| Контекст краткости | Оценивает краткий контекст, приведенный из исходного контекста для не относящейся к делу информации. |
| Контекст переигрывает | Оценивает, насколько эффективно переосмысленный контекст сравнивается с исходным контекстом. |

| Оценка | Описание |
|---|---|
| Языковые особенности | Оценки качества и эффективности языка в ответе, сосредоточившись на таких факторах, как ясность, когерентность, краткость и общее общение. |
| Тональность | Оценки, соответствует ли сгенерированный ответ требуемый тон персонажа |

| Оценка | Описание |
|---|---|
| Галлюцинация кода | Оценки, независимо от того, является ли код, присутствующий в сгенерированном ответе, основан на контексте. |

| Оценка | Описание |
|---|---|
| Удовлетворение пользователя | Оценки того, насколько хорошо решаются проблемы пользователя, и оценивает их удовлетворение на основе предоставленного разговора. |

| Оценка | Описание |
|---|---|
| Пользовательское руководство | Позволяет вам указать руководство и оценивать, насколько хорошо LLM придерживается предоставленного руководства при предоставлении ответа. |
| Пользовательские подсказки | Позволяет создавать свой собственный набор оценок. |

| Оценка | Описание |
|---|---|
| Сопоставление ответов | Сравнивает и оценивает, насколько хорошо отклик, генерируемый LLM, выравнивается с предоставленной наземной истиной. |

| Оценка | Описание |
|---|---|
| Быстрое впрыск | Оценки того, является ли подсказка пользователя попыткой заставить LLM раскрыть свои системы системы. |
| Обнаружение джейлбрейка | Оценки, независимо от того, является ли приглашение пользователя попыткой джейлбрейка (то есть генерирует незаконные или вредные ответы). |

| Оценка | Описание |
|---|---|
| Полнота субпрозраивания | Оцените, оцените ли все подростки, сгенерированные из запроса пользователя, взяты вместе, охватывают все аспекты запроса пользователя или нет |
| Многопрофильная точность | Оцените, точно ли варианты генерируют исходный запрос |
| Оценка фреймворки | LLM -поставщики | LLM Пакеты | Служные рамки | LLM наблюдаемость | Вектор DBS |
|---|---|---|---|---|---|
| Openai evals | Openai | Lmamaindex | Оллама | Langfuse | Qdrant |
| Лазур | Вместе ай | Геликон | Файсс | ||
| Клод | AnyScale | Зено | Хрома | ||
| Мистраль | Реплицировать | ||||
| Объятие |
Скоро наступит больше интеграций. Если у вас есть конкретная интеграция, пожалуйста, сообщите нам об этом, создав проблему.
Наиболее популярные LLM, такие как GPT-4, GPT-3,5-Turbo, Claude-2.1 и т. Д.,-это закрытый источник, т.е. открыты через API с очень небольшим видимостью того, что происходит под капотом. Есть много сообщений о том, как быстрая дрейф (или GPT-4 стала ленивым) и исследовательской работы, изучающей деградацию в качеством модели. Этот эталон является попыткой отслеживать изменение поведения модели, оценивая его ответ на фиксированном наборе данных.
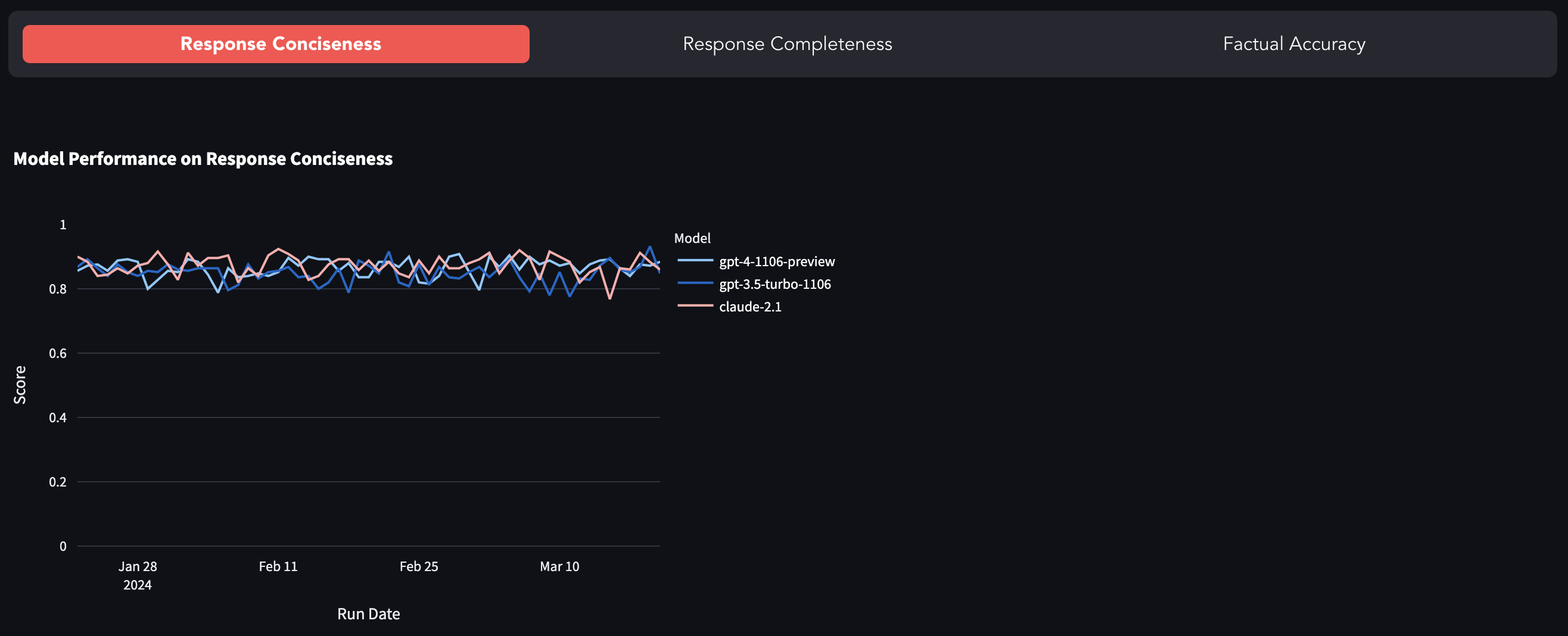
Вы можете найти эталон здесь.
Проработав с моделями ML и NLP в течение последних 8 лет, мы были постоянно прищеплены из -за многочисленных скрытых сбоев в наших моделях, которые привели к тому, что мы построили восходящий брейн. Впресс первоначально начался как инструмент наблюдаемости ML с проверками для идентификации регрессии по точности.
Однако вскоре мы выпустили, что разработчики LLM сталкиваются с еще большей проблемой - нет хорошего способа измерить точность их приложений LLM, не говоря уже о регрессии.
Мы также увидели выпуск Openai Evals, где они предложили использовать LLM для оценки ответов на модели. Кроме того, мы приобрели уверенность в том, чтобы подойти к этому после прочтения, как антропический использует RLAIF и погрузился в исследование оценок LLM (мы вскоре выпускаем хранилище исследований удивительных оценок).
Итак, приходите сегодня, Uptrain - это наша попытка принести порядок в хаос LLM и внести свой вклад в сообщество. В то время как большинство разработчиков по -прежнему полагаются на интуицию и быстрое изменение производства, просмотрев несколько случаев, мы слышали достаточно историй регрессии, чтобы полагать, что «оценки и улучшение» станут ключевой частью экосистемы LLM, поскольку пространство созревает.
Надежные оценки позволяют систематически экспериментировать с различными конфигурациями и предотвратить любые регрессии, помогая объективно выбрать лучший выбор.
Это помогает вам понять, куда ваши системы идут не так, найдите основную причину и исправьте их - задолго до того, как ваши конечные пользователи будут жаловаться и потенциально вытекают.
Оценки, такие как быстрое впрыск и обнаружение джейлбрейка, необходимы для поддержания безопасности и безопасности ваших приложений LLM.
Оценки помогут вам обеспечить прозрачность и укрепить доверие с вашими конечными пользователями, особенно актуальными, если вы продаете предприятиям.
Мы понимаем, что нет единого решения для всех, когда дело доходит до оценки. Мы все чаще видим желание разработчиков изменить подсказку оценки или набор вариантов или несколько примеров выстрела и т. Д.
Фостер инновации : область оценок LLM и использование LLM-As-A-a-Judge все еще довольно зарождающееся. Мы видим много интересных исследований, которые происходят почти на ежедневной основе, и быть открытым исходным кодом предоставляет нам и нашему сообществу подходящую платформу для реализации этих методов и быстрее внедрять инновации.
Мы постоянно стремимся улучшить восходящий блок, и есть несколько способов внести свой вклад:
Обратите внимание на любые проблемы или области для улучшения: если вы заметите что -то не так или имеете идеи для улучшений, пожалуйста, создайте проблему в нашем репозитории GitHub.
Внесите напрямую: если вы видите проблему, которую вы можете исправить или иметь улучшения кода, не стесняйтесь вносить непосредственный вклад в репозиторий.
Запросите пользовательские оценки: если ваш приложение требует адаптированной оценки, сообщите нам об этом, и мы добавим его в репозиторий.
Интегрируйте с вашими инструментами: нужна интеграция с существующими инструментами? Обратитесь, и мы поработаем над этим.
Помощь с оценками: если вам нужна помощь в оценке, опубликуйте свой запрос на нашем канале Slack, и мы будем быстро его решить.
Покажите свою поддержку: Покажите свою поддержку, сыграв главную роль в GitHub, чтобы отслеживать наш прогресс.
Распространите слово: если вам нравится то, что мы построили, дайте нам крик в Twitter!
Ваш вклад и поддержка очень ценятся! Спасибо за то, что вы являетесь частью путешествия вверх.
Этот репо публикуется по лицензии Apache 2.0, и мы стремимся добавить больше функциональных возможностей в репо с открытым исходным кодом. У нас также есть управляемая версия, если вы просто хотите получить более неповторимый опыт. Пожалуйста, забронируйте демо -звонок здесь.
Мы строим восходящий на публике. Помогите нам улучшить, предоставив здесь ваши отзывы.
Мы приветствуем вклад в восходящий. Пожалуйста, смотрите наше руководство по вкладу для получения подробной информации.


