uptrain
v0.7.1

Uptrain은 생성 AI 애플리케이션을 평가하고 개선하기위한 오픈 소스 통합 플랫폼입니다. 우리는 20 개 이상의 미리 구성된 평가 등급 (언어, 코드, 사용 사례 커버)을 제공하고 실패 사례에 대한 근본 원인 분석을 수행하며이를 해결하는 방법에 대한 통찰력을 제공합니다.

Up 트레인 대시 보드는 로컬 컴퓨터 에서 실행되는 웹 기반 인터페이스입니다. 대시 보드를 사용하여 LLM 응용 프로그램을 평가하고 결과를보고 근본 원인 분석을 수행 할 수 있습니다.

응답 완전성, 사실 정확도, 컨텍스트 간결함 등과 같은 20 개 이상의 사전 구성된 평가 지원.

모든 평가 및 분석은 시스템에서 로컬로 실행되므로 데이터가 안전한 환경을 떠나지 않도록하십시오 (모델 채점 확인을 사용하는 동안 LLM 통화를 제외하고)

Text-embedding-3-Large/Small, Text-embedding-3-ADA, Baai/Bge-Large 등과 같은 다양한 임베딩 모델을 실험하십시오 . Uptrain은 엔드 포인트에서 호스팅 된 Huggingface 모델, 복제 엔드 포인트 또는 사용자 정의 모델을 지원합니다.

LLM 파이프 라인의 어느 부분이 차선책을 제공하는지 이해하기 위해 부정적인 사용자 피드백 또는 낮은 평가 점수가있는 사례에 대한 근본 원인 분석을 수행 할 수 있습니다. 지원되는 RCA 템플릿을 확인하십시오.

우리는 당신이 평가자로 사용하기 위해 모든 스케일에서 호스팅 된 OpenAi, 의인화, Mistral, Azure의 Openai 엔드 포인트 또는 오픈 소스 LLM을 사용할 수 있습니다.

Uptrain은 평가를 사용자 정의하는 수많은 방법을 제공합니다. 평가 방법 (사고 vs 분류), 몇 가지 예제 및 시나리오 설명을 사용자 정의 할 수 있습니다. 사용자 정의 평가자를 만들 수도 있습니다.
Uptrain 대시 보드는 LLM 응용 프로그램을 평가할 수있는 웹 기반 인터페이스입니다. 로컬 컴퓨터에서 실행되는 자체 호스트 대시 보드입니다. 대시 보드를 사용하려면 코드를 작성할 필요가 없습니다. 대시 보드를 사용하여 LLM 응용 프로그램을 평가하고 결과를보고 근본 원인 분석을 수행 할 수 있습니다.
시작하기 전에 기계에 Docker가 설치되어 있는지 확인하십시오. 그렇지 않은 경우 여기에서 설치할 수 있습니다.
다음 명령은 Uptrain 대시 보드를 다운로드하여 로컬 컴퓨터에서 시작합니다.
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.sh참고 : Up 트레인 대시 보드는 현재 베타 버전 입니다. 우리는 당신의 피드백을 좋아하여 그것을 개선합니다.
개발자이고 업 트레인 평가를 애플리케이션에 통합하려면 업 트레인 패키지를 사용할 수 있습니다. 이를 통해 LLM 애플리케이션을 평가할 수있는보다 프로그래밍 방식이 가능합니다.
pip install uptrainOpenAI API 키를 제공하여 평가를 실행하여 오픈 소스 버전을 통해 응답을 평가할 수 있습니다.
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))궁금한 점이 있으면 슬랙 커뮤니티에 가입하십시오.
여기에서 전화를 예약하여 Uptrain의 관리자와 직접 문의하십시오.

| 평가 | 설명 |
|---|---|
| 응답 완전성 | 응답이 지정된 질문의 모든 측면에 답했는지 여부. |
| 응답 간결함 | 생성 된 응답이 얼마나 간결한 지 또는 질문에 대한 추가 관련없는 정보가 있는지 등급. |
| 응답 관련성 | 생성 된 컨텍스트가 지정된 질문과 얼마나 관련이 있는지 등급. |
| 응답 유효성 | 생성 된 응답이 유효 한 경우 등급. 응답은 정보가 포함 된 경우 유효한 것으로 간주됩니다. |
| 응답 일관성 | 답변이 얼마나 일관된 지에 대한 질문과 제공된 컨텍스트와 관련하여. |

| 평가 | 설명 |
|---|---|
| 맥락 관련성 | 컨텍스트가 지정된 질문과 얼마나 관련이 있는지 등급. |
| 컨텍스트 활용 | 컨텍스트에 제공된 정보를 고려할 때 생성 된 응답이 지정된 질문에 대한 성적. |
| 사실 정확도 | 생성 된 응답이 사실상 정확하고 제공된 컨텍스트에 의해 근거가 있는지 여부. |
| 문맥 간향 | 관련없는 정보에 대한 원래 컨텍스트에서 인용 된 간결한 컨텍스트를 평가합니다. |
| 컨텍스트 재실행 | 재고 된 컨텍스트가 원래 컨텍스트와 얼마나 효율적인지 평가합니다. |

| 평가 | 설명 |
|---|---|
| 언어 기능 | 명확성, 일관성, 간결함 및 전반적인 커뮤니케이션과 같은 요소에 중점을 둔 응답으로 언어의 품질과 효과를 평가합니다. |
| 색조 | 생성 된 응답이 필요한 페르소나의 어조와 일치하는지 등급 |

| 평가 | 설명 |
|---|---|
| 코드 환각 | 생성 된 응답에 존재하는 코드가 컨텍스트에 의해 근거가되는지 여부. |

| 평가 | 설명 |
|---|---|
| 사용자 만족도 | 사용자의 우려가 얼마나 잘 해결되고 제공된 대화에 따라 만족도를 평가합니다. |

| 평가 | 설명 |
|---|---|
| 맞춤형 가이드 라인 | 응답을 할 때 LLM이 제공된 가이드 라인을 얼마나 잘 준수하는지 가이드 라인 및 등급을 지정할 수 있습니다. |
| 커스텀 프롬프트 | 자신의 평가 세트를 만들 수 있습니다. |

| 평가 | 설명 |
|---|---|
| 응답 일치 | LLM에 의해 생성 된 응답이 제공된 근거 진실과 얼마나 잘 일치하는지 비교 및 등급. |

| 평가 | 설명 |
|---|---|
| 신속한 주입 | 사용자의 프롬프트가 LLM에 시스템 프롬프트를 공개하려는 시도 여부에 관계없이 성적. |
| 탈옥 탐지 | 사용자의 프롬프트가 탈옥을 시도하는지 여부는 등급입니다 (즉, 불법적이거나 유해한 응답을 생성). |

| 평가 | 설명 |
|---|---|
| 하위 정체 완전성 | 사용자의 쿼리에서 생성 된 모든 하위 질문이 함께 찍은 모든 하위 질문이 사용자 쿼리의 모든 측면을 포함하는지 여부를 평가하십시오. |
| 다중 정체 정확도 | 생성 된 변형이 원래 쿼리를 정확하게 나타내는 지 여부를 평가합니다. |
| 프레임 워크 평가 | LLM 제공 업체 | LLM 패키지 | 서빙 프레임 워크 | LLM 관찰 가능성 | 벡터 DBS |
|---|---|---|---|---|---|
| Openai Evals | Openai | llamaindex | 올라마 | langfuse | qdrant |
| 하늘빛 | 함께 ai | 헬리콘 | Faiss | ||
| 클로드 | 모든 규모 | 제노 | 크로마 | ||
| 미스트랄 | 뒤로 젖히다 | ||||
| 포옹 페이스 |
더 많은 통합이 곧 출시 될 예정입니다. 특정 통합을 염두에두면 문제를 만들어 알려주십시오.
GPT-4, GPT-3.5-Turbo, Claude-2.1 등과 같은 가장 인기있는 LLM은 폐쇄 소스이며, 즉 API를 통해 노출되어 후드 아래에서 발생하는 일에 대한 가시성이 거의 없습니다. 신속한 드리프트 (또는 GPT-4가 게으르다)와 모델 품질의 저하를 탐구하는 연구 작업의 보고서가 많이보고되었습니다. 이 벤치 마크는 고정 데이터 세트에서 응답을 평가하여 모델 동작의 변화를 추적하려는 시도입니다.
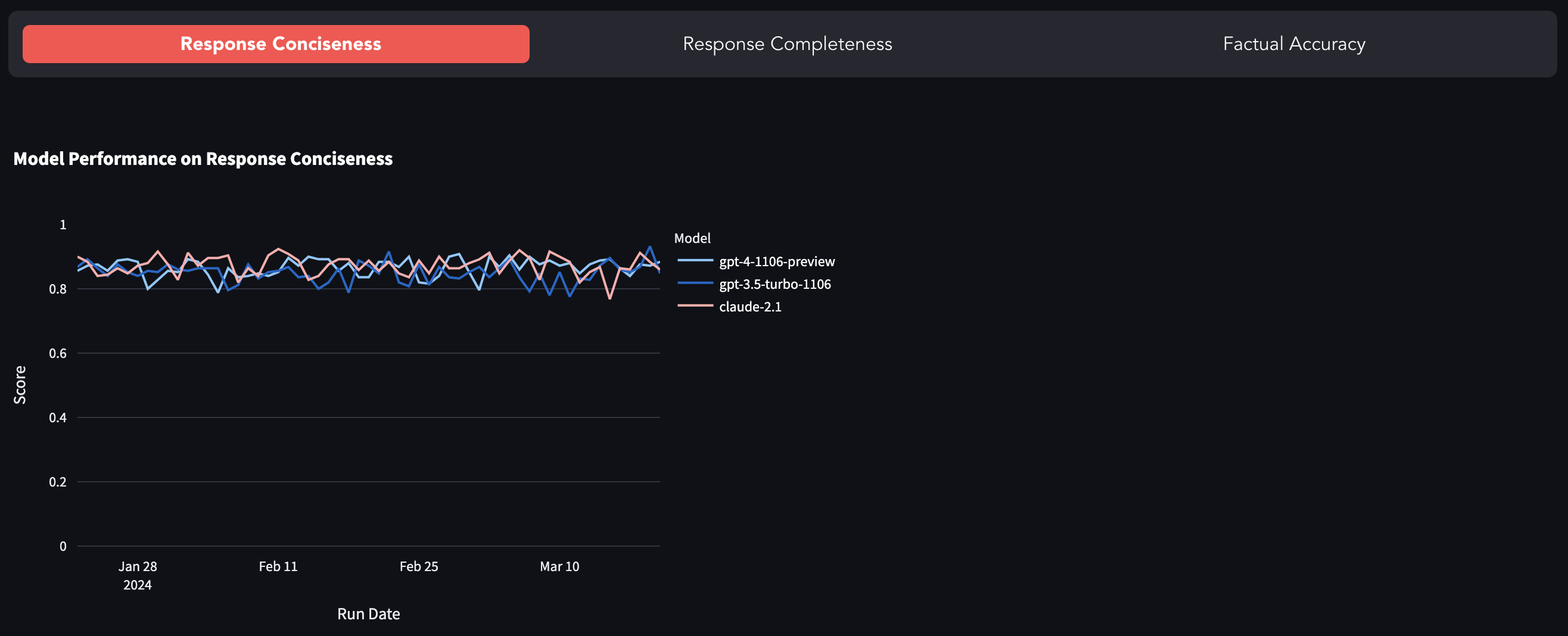
여기에서 벤치 마크를 찾을 수 있습니다.
지난 8 년간 ML 및 NLP 모델과 함께 일한 결과, 우리는 모델에 수많은 숨겨진 실패로 인해 계속해서 튀어 나와서 우리는 업 트레인을 구축하게했습니다. 업 트레인은 처음에 회귀를 정확하게 식별하기 위해 점검을 통해 ML 관측 성 도구로 시작되었습니다.
그러나 우리는 곧 LLM 개발자가 더 큰 문제에 직면하게된다고 곧 발표했습니다. 회귀를 식별하는 것은 물론 LLM 응용 프로그램의 정확도를 측정 할 수있는 좋은 방법이 없습니다.
우리는 또한 Openai EVAL의 출시를 보았으며, 여기서 모델 응답을 등급에 매료하기 위해 LLM의 사용을 제안했습니다. 또한, 우리는 인류가 RLAIF를 어떻게 활용하고 LLM 평가 연구에 바로 다이빙 한 방법을 읽은 후에 이에 접근 할 수있는 자신감을 얻었습니다 (곧 멋진 평가 연구의 저장소를 공개하고 있습니다).
그래서 오늘 오시기, Uptrain은 LLM 혼돈에 질서를 가져오고 지역 사회에 다시 기여하려는 우리의 시도입니다. 대다수의 개발자는 여전히 몇 가지 사례를 검토하여 직관과 제작 프롬프트 변경에 의존하지만 "평가 및 개선"을 믿기에 충분한 회귀 이야기가 공간이 성숙함에 따라 LLM 생태계의 핵심 부분이 될 것이라고 믿었습니다.
강력한 평가를 통해 다른 구성을 체계적으로 실험하고 최선의 선택을 객관적으로 선택하도록 도와 주면 회귀를 방지 할 수 있습니다.
시스템이 잘못 될 곳을 이해하고 근본 원인을 찾고 수정하는 데 도움이됩니다. 최종 사용자가 불만을 제기하고 잠재적으로 휘젓기 전까지.
LLM 응용 프로그램의 안전과 보안을 유지하려면 신속한 주입 및 탈옥 탐지와 같은 평가가 필수적입니다.
평가를 통해 최종 사용자와 투명성을 제공하고 신뢰를 구축하는 데 도움이됩니다. 특히 기업에 판매하는 경우 관련이 있습니다.
우리는 평가와 관련하여 하나의 크기에 맞는 솔루션이 없다는 것을 이해합니다. 우리는 개발자가 평가 프롬프트 또는 선택의 세트 또는 몇 가지 샷 예제 등을 수정하려는 욕구를 점점 더 많이보고 있습니다. 우리는 최상의 개발자 경험이 20 가지 매개 변수를 노출시키는 대신 오픈 소스에 있다고 생각합니다.
포스터 혁신 : LLM 평가 분야와 LLM-AS-A-Judge 사용 분야는 여전히 초기입니다. 우리는 거의 매일 매일 흥미로운 연구가 일어나고 있으며 오픈 소스는 우리와 지역 사회에 올바른 플랫폼을 제공하고 이러한 기술을 구현하고 더 빨리 혁신 할 수있는 올바른 플랫폼을 제공합니다.
우리는 지속적으로 업 트레인을 향상시키기 위해 노력하고 있으며, 기여할 수있는 몇 가지 방법이 있습니다.
개선을위한 문제 나 영역에 주목하십시오. 잘못된 것을 발견하거나 향상에 대한 아이디어가 있으면 GitHub 저장소에 문제를 만들어주십시오.
직접 기여 : 문제가있는 경우 코드 개선을 제안하기 위해 코드 개선을 할 수 있습니다. 리포지토리에 직접 기여하십시오.
사용자 정의 평가 요청 : 응용 프로그램에 맞춤형 평가가 필요한 경우 알려 주시면 저장소에 추가하겠습니다.
도구와 통합 : 기존 도구와 통합이 필요하십니까? 손을 뻗어 우리는 작업 할 것입니다.
평가에 대한 지원 : 평가에 대한 도움이 필요한 경우 쿼리를 슬랙 채널에 게시하면 즉시 해결하겠습니다.
귀하의 지원을 보여주십시오 : Github에 우리를 주연시켜 우리의 진행 상황을 추적하여 지원을 보여주십시오.
말씀을 전하십시오 : 우리가 만든 것을 좋아한다면 트위터에서 외침을주십시오!
귀하의 기여와 지원은 대단히 감사합니다! Uptrain의 여정에 참여해 주셔서 감사합니다.
이 repo는 Apache 2.0 라이센스에 따라 게시되며 Uptrain Open-Source Repo에 더 많은 기능을 추가하기 위해 노력하고 있습니다. 더 많은 경험을 원한다면 관리 버전도 있습니다. 여기에서 데모 전화를 예약하십시오.
우리는 공개적으로 Uptrain을 구축하고 있습니다. 여기에서 피드백을 제공하여 개선을 도와줍니다.
우리는 Uptrain에 대한 기여를 환영합니다. 자세한 내용은 기여 가이드를 참조하십시오.


