uptrain
v0.7.1

Uptrain est une plate-forme unifiée open source pour évaluer et améliorer les applications généatives d'IA. Nous fournissons des notes pour plus de 20 évaluations préconfigurées (couvrant la langue, le code, l'intégration des cas d'utilisation), effectuez une analyse des causes profondes sur les cas de défaillance et donnant un aperçu de la façon de les résoudre.

UpTrain Dashboard est une interface Web qui s'exécute sur votre machine locale . Vous pouvez utiliser le tableau de bord pour évaluer vos applications LLM, afficher les résultats et effectuer une analyse des causes profondes.

Support pour plus de 20 évaluations préconfigurées telles que l'exhaustivité de la réponse, la précision factuelle, la concision du contexte, etc.

Toutes les évaluations et analyses s'exécutent localement sur votre système, en vous garantissant que les données ne quittent jamais votre environnement sécurisé (à l'exception des appels LLM lors de l'utilisation de vérifications de classement du modèle)

Expérimentez avec différents modèles d'incorporation tels que le texte-incliné-3-grand / petit, le text-emballeur-3-Ada, le baai / bge-large, etc. Uptrain prend en charge les modèles de liaisons, les points d'évaluation répliqués ou les modèles personnalisés hébergés sur votre point final.

Vous pouvez effectuer une analyse des causes profondes sur les cas avec une rétroaction négative de l'utilisateur ou de faibles scores d'évaluation pour comprendre quelle partie de votre pipeline LLM donne des résultats sous-optimaux. Découvrez les modèles RCA pris en charge.

Nous vous permettons d'utiliser l'un des points de terminaison Openai, anthropic, Mistral, Azure Openai ou LLMS open-source hébergés sur toute échelle pour être utilisé comme évaluateurs.

UpTrain fournit des tonnes de façons de personnaliser les évaluations . Vous pouvez personnaliser la méthode d'évaluation (chaîne de pensée vs classifier), les exemples à quelques coups et la description du scénario. Vous pouvez également créer des évaluateurs personnalisés.
Le tableau de bord UpTrain est une interface Web qui vous permet d'évaluer vos applications LLM. Il s'agit d'un tableau de bord auto-hébergé qui s'exécute sur votre machine locale. Vous n'avez pas besoin d'écrire de code pour utiliser le tableau de bord. Vous pouvez utiliser le tableau de bord pour évaluer vos applications LLM, afficher les résultats et effectuer une analyse des causes profondes.
Avant de commencer, assurez-vous que Docker soit installé sur votre machine. Sinon, vous pouvez l'installer à partir d'ici.
Les commandes suivantes téléchargeront le tableau de bord UpTrain et le démarreront sur votre machine locale.
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.shRemarque: UpTrain Dashboard est actuellement en version bêta . Nous aimerions que vos commentaires l'améliorent.
Si vous êtes un développeur et que vous souhaitez intégrer des évaluations UpTrain dans votre application, vous pouvez utiliser le package UpTrain. Cela permet un moyen plus programmatique d'évaluer vos applications LLM.
pip install uptrainVous pouvez évaluer vos réponses via la version open source en fournissant votre clé API OpenAI pour exécuter des évaluations.
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))Si vous avez des questions, veuillez rejoindre notre communauté Slack
Parlez directement avec les mainteneurs d'Uptrain en réservant un appel ici.

| Évaluer | Description |
|---|---|
| Exhaustivité de la réponse | Crade si la réponse a répondu à tous les aspects de la question spécifiée. |
| Réponse concision | Grade à quel point la réponse générée est concise ou si elle a des informations supplémentaires non pertinentes pour la question posée. |
| Pertinence de réponse | Grades dans quelle mesure le contexte généré était pertinent pour la question spécifiée. |
| Validité de réponse | Grades si la réponse générée est valide ou non. Une réponse est considérée comme valide si elle contient des informations. |
| Cohérence de la réponse | Les notes de la réponse est cohérente avec la question posée ainsi qu'avec le contexte fourni. |

| Évaluer | Description |
|---|---|
| Pertinence contextuelle | Grades dans quelle mesure le contexte était pertinent pour la question spécifiée. |
| Utilisation du contexte | Grades à quel point la réponse générée a été complétée pour la question spécifiée, compte tenu des informations fournies dans le contexte. |
| Précision factuelle | Grades si la réponse générée est factuellement correcte et fondée sur le contexte fourni. |
| Contexte Concision | Évalue le contexte concis cité à partir d'un contexte original pour des informations non pertinentes. |
| Rerranage de contexte | Évalue l'efficacité du contexte remanié par rapport au contexte d'origine. |

| Évaluer | Description |
|---|---|
| Caractéristiques linguistiques | Crade la qualité et l'efficacité du langage dans une réponse, en se concentrant sur des facteurs tels que la clarté, la cohérence, la concision et la communication globale. |
| Tonalité | Note si la réponse générée correspond au ton de la personnalité requis |

| Évaluer | Description |
|---|---|
| Hallucination du code | Grade si le code présent dans la réponse générée est fondé sur le contexte. |

| Évaluer | Description |
|---|---|
| Satisfaction de l'utilisateur | Les notes des préoccupations de l'utilisateur sont répondues et évalue leur satisfaction en fonction de la conversation fournie. |

| Évaluer | Description |
|---|---|
| Lignes directrices personnalisées | Vous permet de spécifier une directive et de noter la façon dont la LLM adhère à la directive fournie lors de la réaction. |
| Invites personnalisées | Vous permet de créer votre propre ensemble d'évaluations. |

| Évaluer | Description |
|---|---|
| Correspondance de réponse | Compare et note la façon dont la réponse générée par le LLM s'aligne sur la vérité fondée fournie. |

| Évaluer | Description |
|---|---|
| Injection rapide | Crade si l'invite de l'utilisateur est une tentative de faire en sorte que le LLM révèle ses invites système. |
| Détection de jailbreak | Les notes de l'invite de l'utilisateur sont une tentative de jailbreak (c'est-à-dire générer des réponses illégales ou nuisibles). |

| Évaluer | Description |
|---|---|
| Exhaustivité de la sous-question | Évaluez si toutes les sous-questions générées à partir de la requête d'un utilisateur, prises ensemble, couvrent tous les aspects de la requête de l'utilisateur ou non |
| Précision multi-Quey | Évaluez si les variantes générées représentent avec précision la requête d'origine |
| Cadres d'évaluation | Fournisseurs de LLM | Packages LLM | Frameworks de service | Observabilité LLM | DBS vectoriel |
|---|---|---|---|---|---|
| Openai Evals | Openai | Llamaindex | Ollla | Langfuse | Qdrant |
| Azuré | Ensemble ai | Hélicone | Fais | ||
| Claude | Tous les niveaux | Zeno | Chrome | ||
| Mistral | Reproduire | ||||
| Étreinte |
D'autres intégrations arrivent bientôt. Si vous avez une intégration spécifique à l'esprit, veuillez nous en informer en créant un problème.
Les LLM les plus populaires comme GPT-4, GPT-3.5-turbo, claude-2.1 etc., sont de source fermée, à savoir exposée via une API avec très peu de visibilité sur ce qui se passe sous le capot. Il existe de nombreux cas rapportés de dérive rapide (ou de GPT-4 devenant paresseux) et des travaux de recherche explorant la dégradation de la qualité du modèle. Cette référence est une tentative de suivre le changement de comportement du modèle en évaluant sa réponse sur un ensemble de données fixe.
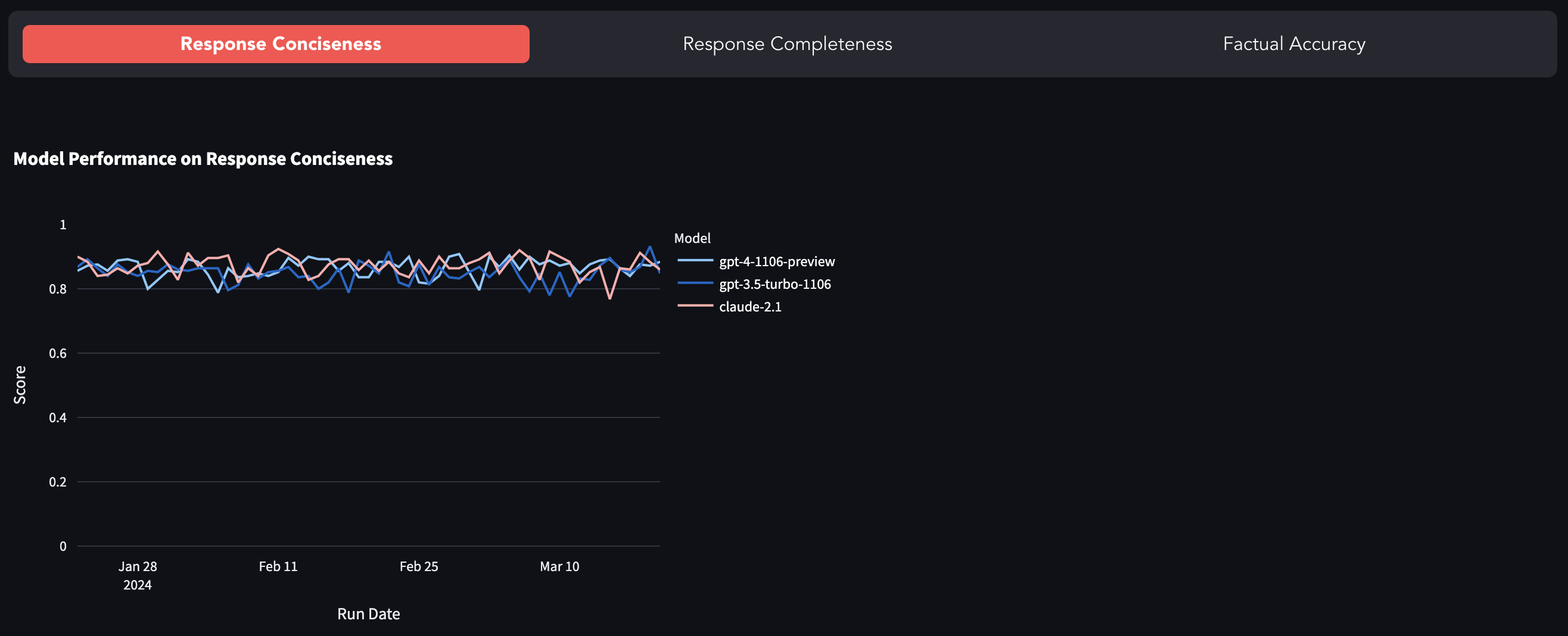
Vous pouvez trouver l'indice de référence ici.
Ayant travaillé avec des modèles ML et NLP au cours des 8 dernières années, nous étions continuellement frustés par de nombreux échecs cachés dans nos modèles qui nous ont conduit à construire Uptrain. UPTrain a été initialement démarré comme un outil d'observabilité ML avec des contrôles pour identifier la régression de la précision.
Cependant, nous avons rapidement libéré que les développeurs LLM sont confrontés à un problème encore plus important - il n'y a pas de bon moyen de mesurer la précision de leurs applications LLM, et encore moins d'identifier la régression.
Nous avons également vu la libération d'Openai Evals, où ils ont proposé l'utilisation de LLMS pour noter les réponses du modèle. En outre, nous avons gagné en confiance pour aborder cela après avoir lu comment anthropique exploite RLAIF et plongé directement dans la recherche sur les évaluations LLM (nous publions bientôt un référentiel de recherches d'évaluations impressionnantes).
Alors, venez aujourd'hui, Uptrain est notre tentative de transmettre l'ordre au chaos LLM et de contribuer à la communauté. Bien qu'une majorité de développeurs comptent toujours sur l'intuition et les changements provités de production en examinant quelques cas, nous avons entendu suffisamment d'histoires de régression pour croire que "les évaluations et l'amélioration" seront un élément clé de l'écosystème LLM à mesure que l'espace mûrit.
Des évaluations robustes vous permettent d'expérimenter systématiquement avec différentes configurations et d'empêcher toute régressions en aidant à sélectionner objectivement le meilleur choix.
Il vous aide à comprendre où se déroulent vos systèmes, à trouver la (s) cause (s) et à les réparer - bien avant que vos utilisateurs finaux ne se plaignent et potentiellement se produire.
Des évaluations telles que l'injection rapide et la détection de jailbreak sont essentielles pour maintenir la sécurité et la sécurité de vos applications LLM.
Les évaluations vous aident à assurer la transparence et à renforcer la confiance avec vos utilisateurs finaux - particulièrement pertinents si vous vendez aux entreprises.
Nous comprenons qu'il n'y a pas de solution unique lorsqu'il s'agit d'évaluations. Nous voyons de plus en plus le désir des développeurs pour modifier l'invite d'évaluation ou l'ensemble de choix ou les quelques exemples de tir, etc. Nous pensons que la meilleure expérience de développeur réside dans l'ouverture, au lieu d'exposer 20 paramètres différents.
Foster Innovation : Le domaine des évaluations LLM et l'utilisation de LLM-AS-A-A-Judge sont encore assez naissants. Nous voyons beaucoup de recherches passionnantes se produire, presque quotidiennement et être open-source nous fournit la bonne plate-forme et notre communauté pour mettre en œuvre ces techniques et innover plus rapidement.
Nous nous efforçons continuellement d'améliorer Uptrain, et il existe plusieurs façons de contribuer:
Remarquez tout problème ou domaine d'amélioration: si vous repérez quelque chose de mal ou si vous avez des idées d'améliorations, veuillez créer un problème sur notre référentiel GitHub.
Contribuer directement: si vous voyez un problème que vous pouvez résoudre ou avoir des améliorations de code à suggérer, n'hésitez pas à contribuer directement au référentiel.
Demandez des évaluations personnalisées: si votre application nécessite une évaluation sur mesure, faites-le nous savoir, et nous l'ajouterons au référentiel.
Intégrer à vos outils: Besoin d'intégration avec vos outils existants? Tendez la main et nous y travaillerons.
Assistance aux évaluations: Si vous avez besoin d'aide pour les évaluations, publiez votre requête sur notre canal Slack et nous le résoudrons rapidement.
Montrez votre support: montrez votre support en nous mettant en vedette sur GitHub pour suivre nos progrès.
Passez le mot: si vous aimez ce que nous avons construit, donnez-nous un cri sur Twitter!
Vos contributions et votre soutien sont grandement appréciés! Merci d'avoir fait partie du voyage d'Uptrain.
Ce dépôt est publié sous la licence Apache 2.0 et nous nous engageons à ajouter plus de fonctionnalités au dépôt de source ouverte UpTrain. Nous avons également une version gérée si vous voulez juste une expérience plus pratique. Veuillez réserver un appel de démonstration ici.
Nous construisons UpTrain en public. Aidez-nous à nous améliorer en donnant vos commentaires ici .
Nous accueillons les contributions à Uptrain. Veuillez consulter notre guide de contribution pour plus de détails.


