uptrain
v0.7.1

UpTrain هي منصة موحدة مفتوحة المصدر لتقييم وتحسين تطبيقات الذكاء الاصطناعي. نحن نقدم درجات لـ 20+ تقييمات تم تكوينها مسبقًا (تغطي اللغة ، والرمز ، وعلامات التضمين) ، وأداء تحليل السبب الجذري في حالات الفشل وإعطاء رؤى حول كيفية حلها.

Uptrain Dashboard هي واجهة تعتمد على الويب تعمل على جهازك المحلي . يمكنك استخدام لوحة القيادة لتقييم تطبيقات LLM الخاصة بك ، وعرض النتائج ، وإجراء تحليل السبب الجذري.

دعم أكثر من 20 تقييمًا مسبقًا مثل اكتمال الاستجابة ، والدقة الواقعية ، وتوصيف السياق ، إلخ.

جميع التقييمات والتحليلات تعمل محليًا على نظامك ، مما يضمن عدم ترك البيانات بيئتك الآمنة (باستثناء مكالمات LLM أثناء استخدام اختبارات الدرجات النموذجية)

تجربة مع نماذج التضمين المختلفة مثل embedding-3-large/small ، embedding-3-ada ، baai/bge-large ، إلخ

يمكنك إجراء تحليل السبب الجذري على الحالات التي تحتوي على ملاحظات المستخدم السلبية أو درجات التقييم المنخفض لفهم أي جزء من خط أنابيب LLM الخاص بك يعطي نتائج دون المستوى الأمثل. تحقق من قوالب RCA المدعومة.

نحن نسمح لك باستخدام أي من نقاط نهاية Openai أو Anthropic أو Mistral أو Azure's Openai أو LLMs مفتوحة المصدر المستضاف على أي حال لاستخدامها كمقيمين.

يوفر Uptrain الكثير من الطرق لتخصيص التقييمات . يمكنك تخصيص طريقة التقييم (سلسلة الفكر VS) ، وأمثلة قليلة ، ووصف السيناريو. يمكنك أيضًا إنشاء تقييمات مخصصة.
لوحة معلومات UPTRAIN هي واجهة تعتمد على الويب تتيح لك تقييم تطبيقات LLM الخاصة بك. إنها لوحة معلومات مستضافة ذاتيًا تعمل على جهازك المحلي. لا تحتاج إلى كتابة أي رمز لاستخدام لوحة القيادة. يمكنك استخدام لوحة القيادة لتقييم تطبيقات LLM الخاصة بك ، وعرض النتائج ، وإجراء تحليل السبب الجذري.
قبل البدء ، تأكد من تثبيت Docker على جهازك. إذا لم يكن كذلك ، يمكنك تثبيته من هنا.
ستقوم الأوامر التالية بتنزيل لوحة معلومات Uptrain وبدء تشغيلها على الجهاز المحلي.
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.shملاحظة: Uptrain Dashboard هي حاليًا في إصدار بيتا . نود ملاحظاتك لتحسينها.
إذا كنت مطورًا وترغب في دمج تقييمات Uptrain في تطبيقك ، فيمكنك استخدام حزمة UpTrain. هذا يسمح لطريقة أكثر برمجية لتقييم تطبيقات LLM الخاصة بك.
pip install uptrainيمكنك تقييم ردودك عبر الإصدار مفتوح المصدر من خلال توفير مفتاح Openai API لتشغيل التقييمات.
from uptrain import EvalLLM , Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question' : 'Which is the most popular global sport?' ,
'context' : "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world." ,
'response' : 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM ( openai_api_key = OPENAI_API_KEY )
results = eval_llm . evaluate (
data = data ,
checks = [ Evals . CONTEXT_RELEVANCE , Evals . FACTUAL_ACCURACY , Evals . RESPONSE_COMPLETENESS ]
)
print ( json . dumps ( results , indent = 3 ))إذا كان لديك أي أسئلة ، يرجى الانضمام إلى مجتمع Slack الخاص بنا
تحدث مباشرة مع مشرفي Uptrain من خلال حجز مكالمة هنا.

| تقييم | وصف |
|---|---|
| استجابة اكتمال | الدرجات ما إذا كانت الرد قد أجبت على جميع جوانب السؤال المحدد. |
| استجابة وصول | الدرجات مدى إيصال الاستجابة التي تم إنشاؤها أو إذا كان لديها أي معلومات إضافية غير ذات صلة للسؤال المطروح. |
| أهمية الاستجابة | الدرجات مدى أهمية السياق الذي تم إنشاؤه للسؤال المحدد. |
| صلاحية الاستجابة | الدرجات إذا كانت الاستجابة التي تم إنشاؤها صالحة أم لا. تعتبر الاستجابة صالحة إذا كانت تحتوي على أي معلومات. |
| اتساق الاستجابة | الدرجات مدى اتساق الرد مع السؤال الذي يتم طرحه وكذلك مع السياق المقدم. |

| تقييم | وصف |
|---|---|
| صلة السياق | الدرجات مدى صلة السياق بالسؤال المحدد. |
| استخدام السياق | الدرجات مدى إكمال الاستجابة التي تم إنشاؤها للسؤال المحدد ، بالنظر إلى المعلومات المقدمة في السياق. |
| دقة واقعية | الدرجات ما إذا كانت الاستجابة التي تم إنشاؤها صحيحة في الواقع وتستند إلى السياق المقدم. |
| سياق الإشراف | يقيم السياق الموجز المذكور من سياق أصلي للمعلومات غير ذات الصلة. |
| سياق إعادة | يقيم مدى كفاءة مقارنة السياق الذي تم إعادة صياغته بالسياق الأصلي. |

| تقييم | وصف |
|---|---|
| ميزات اللغة | يدرج جودة وفعالية اللغة في استجابة ، مع التركيز على عوامل مثل الوضوح والتماسك ودقة وتواصل الشامل. |
| نغمة | الدرجات ما إذا كانت الاستجابة التي تم إنشاؤها تتطابق مع نغمة الشخصية المطلوبة |

| تقييم | وصف |
|---|---|
| الهلوسة رمز | الدرجات ما إذا كان الكود الموجود في الاستجابة التي تم إنشاؤها يستند إلى السياق. |

| تقييم | وصف |
|---|---|
| رضا المستخدم | الدرجات مدى جودة مخاوف المستخدم وتقييم رضاهم بناءً على المحادثة المقدمة. |

| تقييم | وصف |
|---|---|
| المبدأ التوجيهي المخصص | يتيح لك تحديد المبدأ التوجيهي والدرجات مدى جودة LLM إلى المبدأ التوجيهي المقدم عند إعطاء رد. |
| مطالبات مخصصة | يتيح لك إنشاء مجموعة التقييم الخاصة بك. |

| تقييم | وصف |
|---|---|
| مطابقة الاستجابة | يقارن ويتدرج مدى توافق الاستجابة الناتجة عن LLM مع الحقيقة الأرضية المقدمة. |

| تقييم | وصف |
|---|---|
| الحقن الفوري | درجات ما إذا كانت موجه المستخدم هو محاولة لجعل LLM تكشف عن مطالبات نظامه. |
| الكشف عن جيلبريك | درجات ما إذا كانت موجه المستخدم محاولة لكسر الحماية (أي توليد ردود غير قانونية أو ضارة). |

| تقييم | وصف |
|---|---|
| اكتمال السبع الفرعي | قم بتقييم ما إذا كانت جميع الأسئلة الفرعية التي تم إنشاؤها من استعلام المستخدم ، مجتمعة ، تغطي جميع جوانب استعلام المستخدم أم لا |
| دقة متعددة الدرجات | تقييم ما إذا كانت المتغيرات التي تم إنشاؤها بدقة تمثل الاستعلام الأصلي |
| أطراف التقييم | موفري LLM | حزم LLM | أطر العمل | LLM الملاحظة | ناقلات DBS |
|---|---|---|---|---|---|
| Openai Evals | Openai | llamaindex | أولاما | Langfuse | Qdrant |
| أزور | معا منظمة العفو الدولية | هيليكون | فايس | ||
| كلود | anyscale | زنو | Chroma | ||
| خطأ | تكرار | ||||
| luggingface |
المزيد من عمليات التكامل ستأتي قريبًا. إذا كان لديك تكامل محدد في الاعتبار ، فيرجى إخبارنا بإنشاء مشكلة.
تعد LLMs الأكثر شعبية مثل GPT-4 و GPT-3.5-Turbo و Claude-2.1 وما إلى ذلك ، مغلقة المصدر ، أي مكشوفة عبر واجهة برمجة تطبيقات مع القليل جدًا من الرؤية على ما يحدث تحت الغطاء. هناك العديد من مثيلات الانجراف السريع (أو GPT-4 تصبح كسولًا) والأبحاث التي تستكشف التحلل في جودة النموذج. هذا المعيار هو محاولة لتتبع التغيير في سلوك النموذج من خلال تقييم استجابتها على مجموعة بيانات ثابتة.
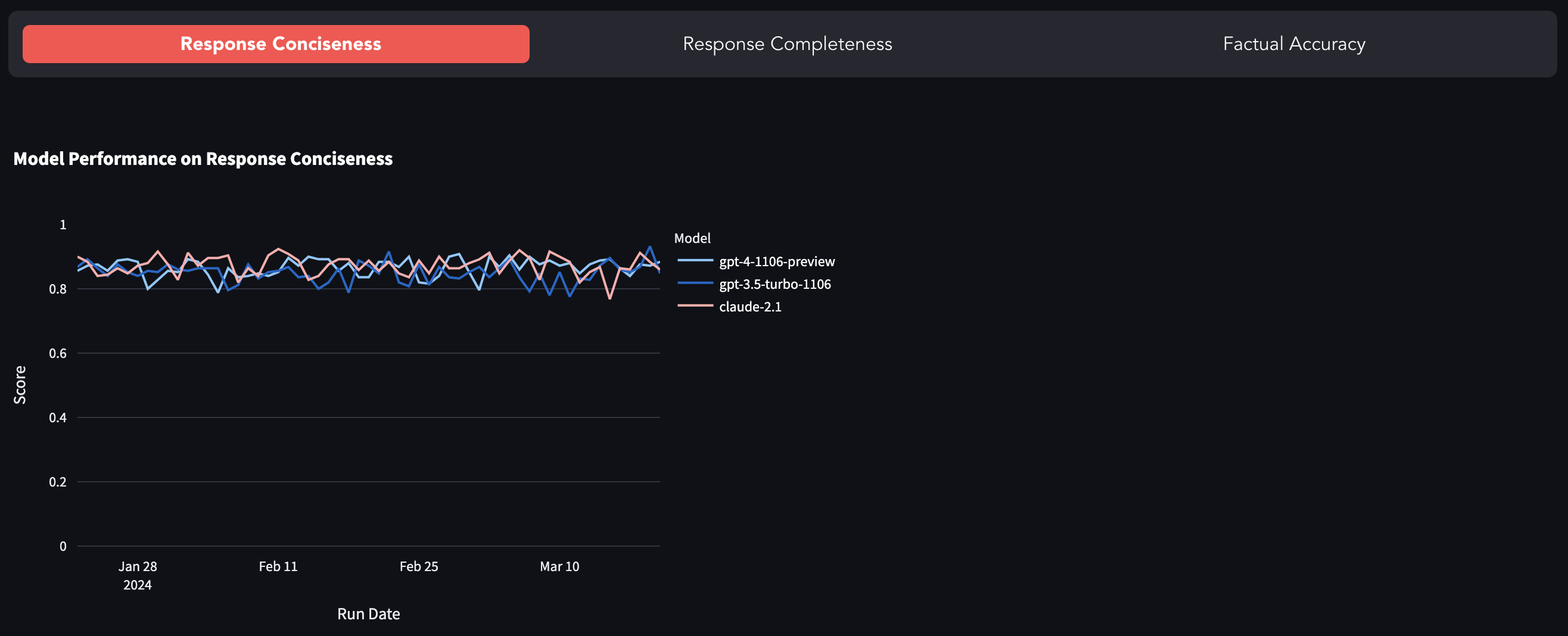
يمكنك العثور على المعيار هنا.
بعد أن عملنا مع نماذج ML و NLP على مدار السنوات الثماني الماضية ، تم تحريرنا بشكل مستمر مع العديد من الإخفاقات الخفية في نماذجنا مما أدى إلى بناء Uptrain. تم البدء في البداية كأداة قابلية للملاحظة ML مع اختبارات لتحديد الانحدار في الدقة.
ومع ذلك ، سرعان ما أصدرنا أن مطوري LLM يواجهون مشكلة أكبر - لا توجد طريقة جيدة لقياس دقة تطبيقات LLM الخاصة بهم ، ناهيك عن تحديد الانحدار.
رأينا أيضًا إطلاقًا من Openai Evals ، حيث اقترحوا استخدام LLMs لتصنيف الاستجابات النموذجية. علاوة على ذلك ، اكتسبنا الثقة في الاقتراب من هذا بعد قراءة كيفية استفادة الأنثروبور RLAIF والانغماس في أبحاث تقييم LLM (سرعان ما نطلق مستودعًا لأبحاث التقييمات الرائعة).
لذلك ، تعال اليوم ، Uptrain هي محاولتنا لتقديم النظام إلى فوضى LLM والمساهمة في المجتمع. في حين أن غالبية المطورين ما زالوا يعتمدون على التغييرات الفريدة للإنتاج والإنتاج من خلال مراجعة حالتين ، فقد سمعنا ما يكفي من قصص الانحدار للاعتقاد بأن "التقييمات والتحسين" ستكون جزءًا رئيسيًا من نظام LLM البيئي مع نضوج الفضاء.
تسمح لك التقييمات القوية بتجربة تكوينات مختلفة بشكل منهجي ومنع أي انحدار من خلال المساعدة بموضوعية في تحديد الخيار الأفضل بموضوعية.
يساعدك ذلك على فهم أين تخطئ أنظمتك ، والعثور على السبب الجذري (الأسباب) وإصلاحها - قبل وقت طويل من الشكوى للمستخدمين النهائيين ويحتمل أن يخرجوا.
تعد تقييمات مثل الحقن السريع والكشف عن السجن ضرورية للحفاظ على سلامة وأمن تطبيقات LLM الخاصة بك.
تساعدك التقييمات على توفير الشفافية وبناء الثقة مع مستخدمي النهائيين - وخاصة ذات صلة إذا كنت تبيع للمؤسسات.
نحن نفهم أنه لا يوجد حل واحد يناسب الجميع عندما يتعلق الأمر بالتقييمات. نرى بشكل متزايد الرغبة من المطورين في تعديل موجه التقييم أو مجموعة الخيارات أو أمثلة القلائل القليلة ، وما إلى ذلك. نعتقد أن أفضل تجربة مطور تكمن في المصدر المفتوح ، بدلاً من تعريض 20 معلمة مختلفة.
Foster Innovation : لا يزال مجال تقييمات LLM واستخدام LLM-As-A-Jugfl ناشئًا. نرى الكثير من الأبحاث المثيرة التي تحدث ، على أساس يومي تقريبًا ، وتوفير المصدر المفتوح للمنصة المناسبة لنا ومجتمعنا لتنفيذ تلك التقنيات والابتكار بشكل أسرع.
نحن نسعى جاهدين بشكل مستمر لتعزيز الصعود ، وهناك عدة طرق يمكنك المساهمة:
لاحظ أي مشكلات أو مجالات للتحسين: إذا اكتشفت أي شيء خاطئ أو لديك أفكار للتحسينات ، فيرجى إنشاء مشكلة في مستودع GitHub الخاص بنا.
المساهمة مباشرة: إذا رأيت مشكلة ، فيمكنك إصلاح أو إجراء تحسينات في التعليمات البرمجية ، لا تتردد في المساهمة مباشرة في المستودع.
اطلب تقييمات مخصصة: إذا كان التطبيق الخاص بك يتطلب تقييمًا مخصصًا ، فأخبرنا ، وسنضيفه إلى المستودع.
الاندماج مع أدواتك: هل تحتاج إلى تكامل مع أدواتك الحالية؟ تواصل ، وسنعمل عليه.
المساعدة في التقييمات: إذا كنت بحاجة إلى مساعدة في التقييمات ، فقم بنشر استعلامك على قناة Slack الخاصة بنا ، وسنحلها على الفور.
أظهر دعمكم: أظهر دعمكم من خلال بطولةنا على Github لتتبع تقدمنا.
انشر الكلمة: إذا أعجبك ما قمنا بإنشائه ، فامنحنا صيحة على Twitter!
يتم تقدير مساهماتك ودعمك بشكل كبير! شكرا لكونك جزءًا من رحلة Uptrain.
يتم نشر هذا الريبو بموجب ترخيص Apache 2.0 ونحن ملتزمون بإضافة المزيد من الوظائف إلى ريبو المصدر المفتوح. لدينا أيضًا إصدار مُدار إذا كنت تريد فقط تجربة أكثر من اليدين. الرجاء حجز مكالمة تجريبية هنا.
نحن نبني Uptrain في الأماكن العامة. ساعدنا في التحسن من خلال إعطاء ملاحظاتك هنا .
نرحب بالمساهمات في Uptrain. يرجى الاطلاع على دليل المساهمة لدينا للحصول على التفاصيل.


