vqazero
1.0.0
Rabiul Awal,Le Zhang和Aishwarya Agrawal
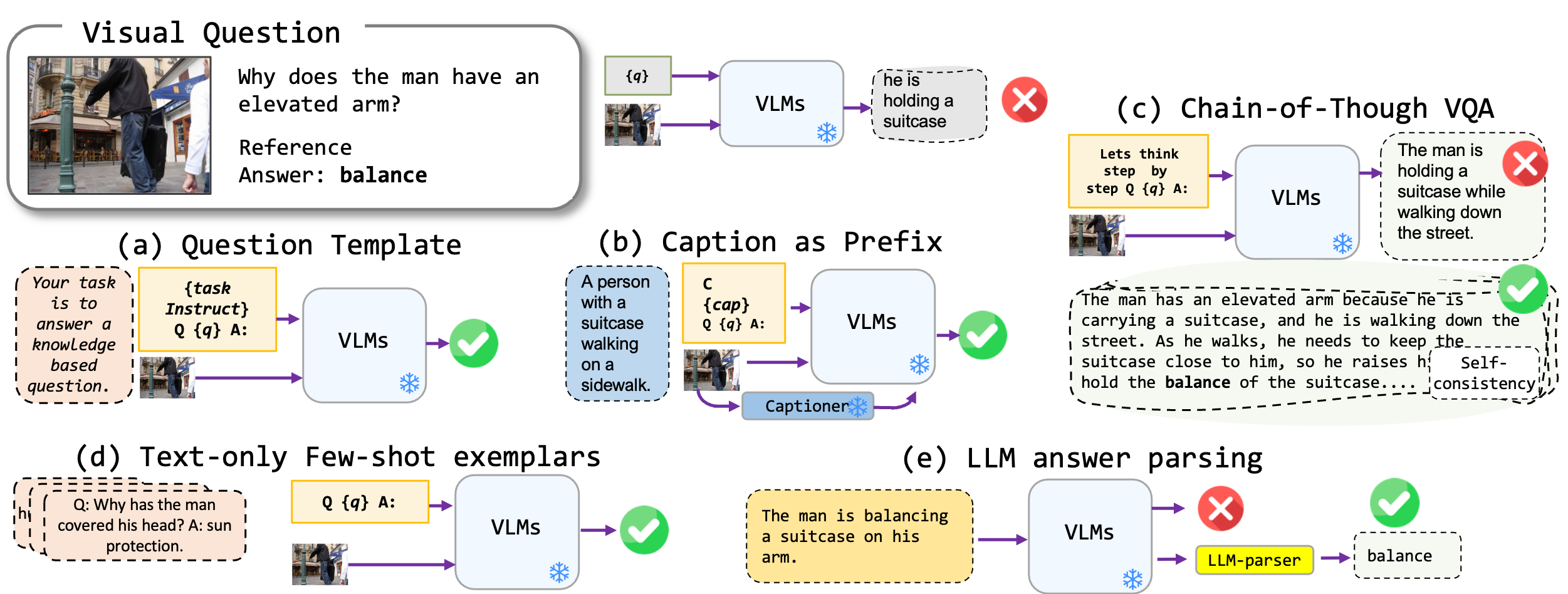
我們探討了無需微調的提示技術,該技術應用於視覺模型,特別是最先進的BLIP2,KOSMOS2,OpenFlamino和多模式指令調節的Llava。我們主要關注以下提示方法:
現有的視覺語言模型(VLMS)已經顯示出良好的零射擊VQA性能。我們的促進技術(尤其是在幾個射門的VQA中字幕)導致基準的大幅增長。但是,儘管據稱指導調節的模型表現出強大的推理能力,但我們的測試發現這些推理能力,尤其是思想鏈,在不同的基準中缺乏。我們希望我們的工作能夠激發未來的研究。
我們支持以下VQA格式:
| 格式 | 描述 | 例子 |
|---|---|---|
| 標準VQA | 標準VQA任務格式。 | 問題:“現場人民的主要活動是什麼?” 答:“跳舞” |
| 字幕VQA | 從模型生成的標題,然後是標準VQA格式開始。 | 背景:一群穿著傳統服裝的人在篝火旁跳舞。 問題:“現場人民的主要活動是什麼?” 答:“跳舞” |
| 經過思考的VQA鏈 | 實現經過思考的格式。 | 問題:“現場人民的主要活動是什麼?讓我們逐步思考。” 答:“首先,考慮到篝火,這通常表示聚會或節日。接下來,看到傳統服裝的人意味著文化事件。合併這些觀察,主要活動是在篝火旁跳舞。” |
我們有一個可以與不同VQA格式一起使用的提示模板列表。請檢查prompts/templates/{dataset_name} 。

下載並將文件解壓縮到VQA數據集的dataset/文件夾中。對於Winoground ,請使用擁抱面部datasets集庫。
| OK-VQA | AOK-VQA | GQA | Winoground | VQAV2 | |
|---|---|---|---|---|---|
| 來源 | 艾倫 | 艾倫 | 斯坦福大學 | 擁抱臉 | VQA |
要運行標準VQA,請使用以下命令:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
要運行字幕VQA,請使用以下命令:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
要運行經過思考的VQA,請使用以下命令:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
請準備extplar數據集dataset_zoo/nearest_neighbor.py並運行以下命令:
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
考慮到開放式答案生成的上下文中VQA準確度指標的限制,我們在evals/vicuna_llm_evals.py中提供實用腳本。使用Vicuna LLM,這些腳本過程生成了與參考響應保持一致的答案,並隨後根據常規的VQA指標對其進行評估。
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
我們報告基線和最佳設置結果。請檢查論文以獲取更多結果。
| Blip2 Flan-T5 | blip2選擇 | KOSMOS2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| 基線 | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| 最好的 | 50.55 | 46.29 | 43.09 | 42.48 | 46.86 |
| Blip2 Flan-T5 | blip2選擇 | KOSMOS2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| 基線 | 51.20 | 45.57 | 40.85 | 17.27 | 52.69 |
| 最好的 | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| Blip2 Flan-T5 | blip2選擇 | KOSMOS2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| 基線 | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| 最好的 | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| Blip2 Flan-T5 | blip2選擇 | KOSMOS2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| 基線 | 66.66 | 54.53 | 53.52 | 35.41 | 56.2 |
| 最好的 | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
請給rabiul.awal [at] mila [dot] quebec發送電子郵件至魁北克。您還可以打開問題或拉出請求,以添加更多提示技術或新的多模式視覺語言模型。
如果您發現此代碼有用,請引用我們的論文:
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
該代碼庫建立在變壓器,Lavis,Llava和FastChat存儲庫的頂部。我們感謝作者的出色工作。


