vqazero
1.0.0
Rabiul Awal, Le Zhang et Aishwarya Agrawal
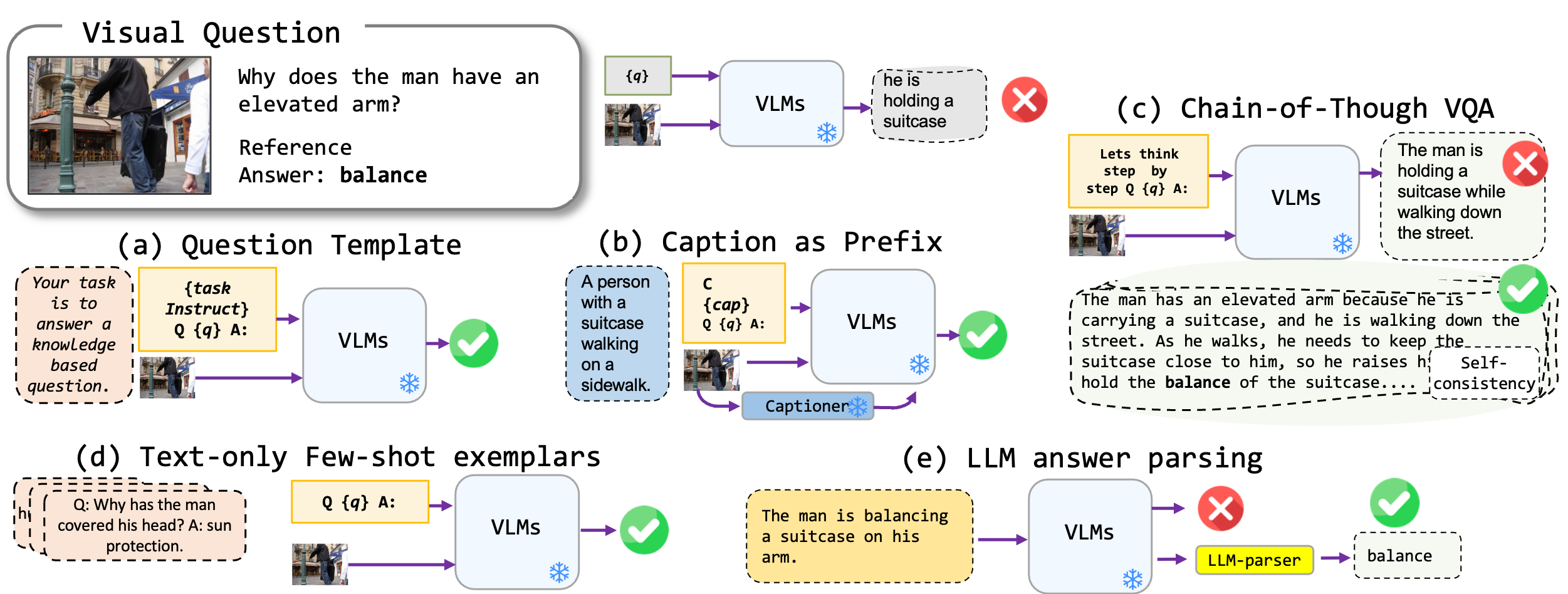
Nous explorons des techniques d'incitation sans réglage fin appliquées aux modèles de vision en langue, en particulier à l'état de la pointe de la technologie, Kosmos2, OpenFlamino et Llava d'instructions multimodales. Nous nous concentrons principalement sur les approches d'incitation suivantes:
Les modèles de vision existants (VLMS) présentent déjà de bonnes performances VQA à tirs zéro. Nos techniques d'incitation (en particulier le sous-titrage dans le VQA à quelques coups) entraînent une augmentation substantielle des performances entre les références. Cependant, bien que les modèles réglés par l'instruction montrent des capacités de raisonnement solides, nos tests ont révélé que ces capacités de raisonnement, en particulier la chaîne de pensées, sont déficientes en diverses références. Nous espérons que notre travail inspirera les recherches futures dans cette direction.
Nous prenons en charge les formats VQA suivants:
| Format | Description | Exemple |
|---|---|---|
| VQA standard | Format de tâche VQA standard. | Question : "Quelle est la principale activité des gens dans la scène?" Réponse : "Danser" |
| Légende VQA | Commence par une légende générée par le modèle, puis le format VQA standard. | Contexte : Un groupe de personnes en tenue traditionnelle danse autour d'un feu de joie. Question : "Quelle est la principale activité des gens dans la scène?" Réponse : "Danser" |
| VQA de la chaîne de pensées | Met en œuvre le format de la chaîne de pensées. | Question : "Quelle est la principale activité des gens dans la scène? Pensions étape par étape." Réponse : "Tout d'abord, étant donné qu'il y a un feu de joie, cela signifie souvent un rassemblement ou une fête. Ensuite, voir des gens en tenue traditionnelle implique un événement culturel. Fusion de ces observations, la principale activité est de danser autour du feu de joie." |
Nous avons une liste de modèles d'invite qui peuvent être utilisés avec différents formats VQA. Veuillez vérifier les prompts/templates/{dataset_name} .

Téléchargez et déziptez les fichiers dans l' dataset/ dossier pour les ensembles de données VQA. Pour Winoground , utilisez la bibliothèque datasets Hugging Face.
| OK-VQA | Aok-vqa | GQA | Winoground | Vqav2 | |
|---|---|---|---|---|---|
| Source | Allenai | Allenai | Stanford | Visage étreint | Vqa |
Pour exécuter le VQA standard, utilisez la commande suivante:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
Pour exécuter la légende VQA, utilisez la commande suivante:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
Pour exécuter le VQA de la chaîne de pensées, utilisez la commande suivante:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
Veuillez préparer le jeu de données Examplar dataset_zoo/nearest_neighbor.py et exécuter la commande suivante:
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
Compte tenu des contraintes des métriques de précision VQA dans le contexte de la génération de réponses ouvertes, nous proposons des scripts utilitaires dans evals/vicuna_llm_evals.py . En utilisant Vicuna LLM, ces scripts ont généré des réponses pour s'aligner sur les réponses de référence et les évaluer par la suite sur la base de la métrique VQA conventionnelle.
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
Nous rapportons les résultats de base et les meilleurs résultats. Veuillez vérifier le journal pour plus de résultats.
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | Openflamingo | Llave | |
|---|---|---|---|---|---|
| Base de base | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| Meilleur | 50,55 | 46.29 | 43.09 | 42.48 | 46.86 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | Openflamingo | Llave | |
|---|---|---|---|---|---|
| Base de base | 51.20 | 45,57 | 40,85 | 17.27 | 52.69 |
| Meilleur | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | Openflamingo | Llave | |
|---|---|---|---|---|---|
| Base de base | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| Meilleur | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | Openflamingo | Llave | |
|---|---|---|---|---|---|
| Base de base | 66.66 | 54,53 | 53,52 | 35.41 | 56.2 |
| Meilleur | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
Veuillez envoyer un courriel rabiul.awal [at] mila [dot] quebec pour toute question. Vous pouvez également ouvrir une demande de problème ou d'extraction pour ajouter plus de techniques d'incitation ou de nouveaux modèles multimodaux en langage de vision.
Si vous trouvez ce code utile, veuillez citer notre article:
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
La base de code est construite au-dessus des référentiels Transformers, Lavis, Llava et FastChat. Nous remercions les auteurs pour leur travail incroyable.


