vqazero
1.0.0
Rabiul Awal, Le Zhang und Aishwarya Agrawal
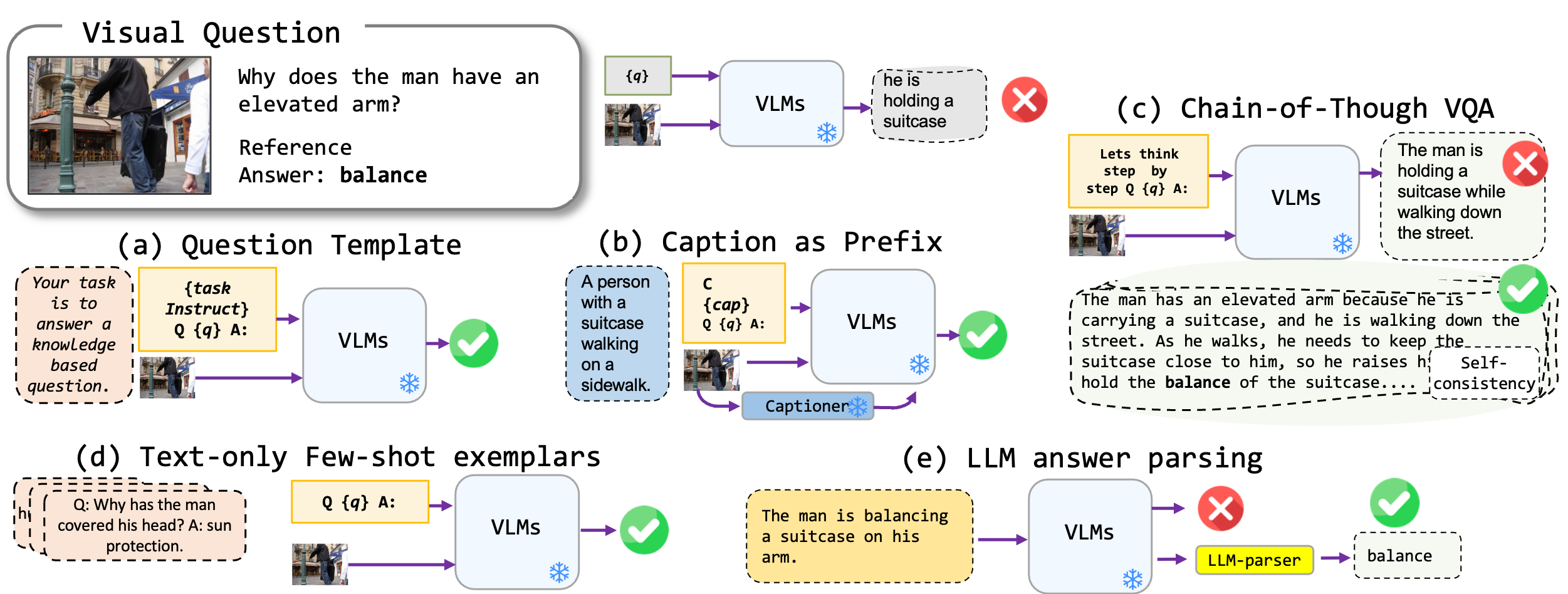
Wir untersuchen feinabstimmfreie Aufforderungstechniken, die auf Sichtsprachmodelle angewendet werden, insbesondere auf modernste Blip2-, Kosmos2-, OpenFlamino- und multimodale LLAVA. Wir konzentrieren uns hauptsächlich auf folgende Ansätze:
Vorhandene Sichtsprachmodelle (VLMs) zeigen bereits eine gute Null-Shot-VQA-Leistung. Unsere Aufforderungstechniken (insbesondere die Bildunterschrift in wenigen VQA) führen zu einer erheblichen Leistungssteigerung über die Benchmarks hinweg. Obwohl behauptet werden, dass modellierte Modelle starke Argumentationsfähigkeiten aufweisen, stellten unsere Tests fest, dass diese Argumentationsfähigkeiten, insbesondere die Gedankenkette, an verschiedenen Benchmarks mangelhaft sind. Wir hoffen, dass unsere Arbeit zukünftige Forschungen in diese Richtung inspirieren wird.
Wir unterstützen die folgenden VQA -Formate:
| Format | Beschreibung | Beispiel |
|---|---|---|
| Standard VQA | Standard -VQA -Aufgabenformat. | Frage : "Was ist die Hauptaktivität der Menschen in der Szene?" Antwort : "Tanzen" |
| Bildunterschrift VQA | Beginnt mit einer Modell-generierten Bildunterschrift und dann mit dem Standard-VQA-Format. | Kontext : Eine Gruppe von Menschen in traditioneller Kleidung tanzt um ein Lagerfeuer. Frage : "Was ist die Hauptaktivität der Menschen in der Szene?" Antwort : "Tanzen" |
| VQA-Kette | Implementiert das übergedachte Format der Kette. | Frage : "Was ist die Hauptaktivität der Menschen in der Szene? Überlegen wir uns Schritt für Schritt." Antwort : "In Anbetracht dessen, dass es ein Lagerfeuer gibt, bedeutet dies häufig eine Versammlung oder Feste. Als nächstes impliziert das Sehen von Menschen in traditioneller Kleidung ein kulturelles Ereignis. Wenn man diese Beobachtungen verschmelzen, tanzt die Hauptaktivität am Lagerfeuer." |
Wir haben eine Liste von schnellen Vorlagen, die mit verschiedenen VQA -Formaten verwendet werden können. Bitte überprüfen Sie die prompts/templates/{dataset_name} .

Laden Sie die Dateien für die VQA -Datensätze in den dataset/ Ordner herunter und entpacken Sie sie. Verwenden Sie für WinOgroder die Bio -Bibliothek der umarmenden datasets .
| Ok-vqa | Aok-vqa | GQA | Winöhe | VQAV2 | |
|---|---|---|---|---|---|
| Quelle | Allenai | Allenai | Stanford | Umarmtes Gesicht | VQA |
Verwenden Sie den folgenden Befehl, um die Standard -VQA auszuführen:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
Verwenden Sie den folgenden Befehl, um die Bildunterschrift VQA auszuführen:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
Verwenden Sie den folgenden Befehl, um die VQA der Kette des Gedächtnisses auszuführen:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
Bitte erstellen Sie example dataset dataset_zoo/nearest_neighbor.py und führen Sie den folgenden Befehl aus:
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
In Anbetracht der Einschränkungen der VQA-Genauigkeitsmetriken im Kontext der offenen Antwortgenerierung bieten wir Dienstprogrammskripte in evals/vicuna_llm_evals.py an. Mit Vicuna LLM verarbeiten diese Skripte Antworten, um sich an Referenzantworten auszurichten, und bewerten sie anschließend anhand der herkömmlichen VQA -Metrik.
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
Wir melden die Basis- und besten Einstellungsergebnisse. Bitte überprüfen Sie das Papier, um weitere Ergebnisse zu erhalten.
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Grundlinie | 50.13 | 42.7 | 40.33 | 18.29 | 44,84 |
| Am besten | 50.55 | 46.29 | 43.09 | 42.48 | 46,86 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Grundlinie | 51.20 | 45,57 | 40.85 | 17.27 | 52.69 |
| Am besten | 54,98 | 49,39 | 43,60 | 44.13 | 52.32 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Grundlinie | 44,46 | 38.46 | 37.33 | 26.37 | 38.40 |
| Am besten | 47.01 | 41.99 | 40.13 | 41.00 | 42,65 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Grundlinie | 66,66 | 54,53 | 53,52 | 35.41 | 56,2 |
| Am besten | 71.37 | 62,81 | 57.33 | 58.0 | 65.32 |
Bitte senden Sie eine E -Mail an rabiul.awal [at] mila [dot] quebec für Fragen. Sie können auch eine Ausgabe eröffnen oder anrufen, um mehr Aufforderungstechniken oder neue multi-modal-Vision-Sprachen-Modelle hinzuzufügen.
Wenn Sie diesen Code nützlich finden, zitieren Sie bitte unser Papier:
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
Die Codebasis ist auf den Repositorys von Transformers, Lavis, Llava und Fastchat aufgebaut. Wir danken den Autoren für ihre tolle Arbeit.


