vqazero
1.0.0
Rabiul Awal, Le Zhang y Aishwarya Agrawal
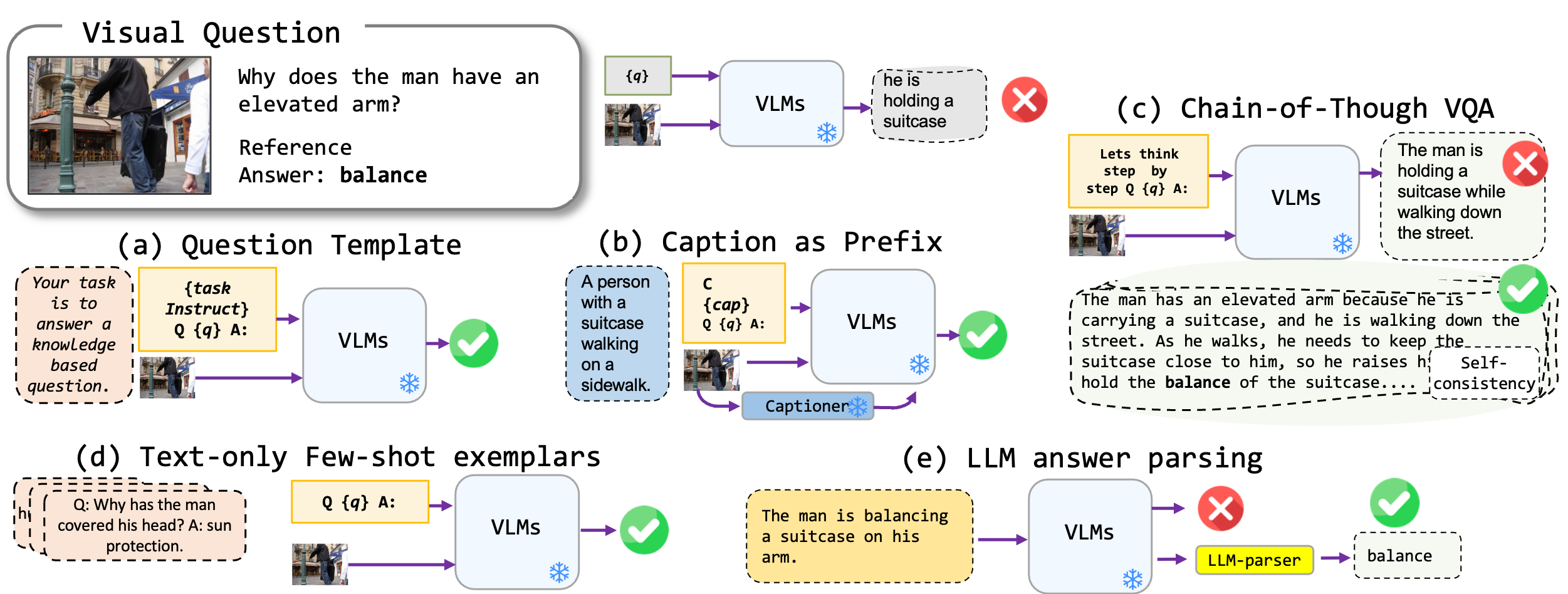
Exploramos las técnicas de solicitación sin ajuste fino aplicadas a los modelos en idioma de visión, específicamente Blip2 de vanguardia, Kosmos2, OpenFlamino y Llava multimodal ajustada a instrucciones. Nos centramos principalmente en los siguientes enfoques de solicitación:
Los modelos existentes en idioma de visión (VLMS) ya muestran un buen rendimiento de VQA de disparo cero. Nuestras técnicas de solicitación (especialmente subtitulios en VQA de pocos disparos) conducen a un aumento sustancial de rendimiento en los puntos de referencia. Sin embargo, aunque se afirma que los modelos ajustados a la instrucción muestran fuertes habilidades de razonamiento, nuestras pruebas encontraron que estas habilidades de razonamiento, particularmente la cadena de pensamiento, son deficientes en diversos puntos de referencia. Esperamos que nuestro trabajo inspire la investigación futura en esta dirección.
Apoyamos los siguientes formatos VQA:
| Formato | Descripción | Ejemplo |
|---|---|---|
| VQA estándar | Formato de tarea VQA estándar. | Pregunta : "¿Cuál es la actividad principal de las personas en la escena?" Respuesta : "Bailar" |
| Leyenda VQA | Comienza con una leyenda generada por el modelo, luego el formato VQA estándar. | Contexto : un grupo de personas con atuendo tradicional bailan alrededor de una hoguera. Pregunta : "¿Cuál es la actividad principal de las personas en la escena?" Respuesta : "Bailar" |
| VQA de la cadena de pensamiento | Implementa el formato de cadena de pensamiento. | Pregunta : "¿Cuál es la actividad principal de las personas en la escena? Pensemos paso a paso". Respuesta : "Primero, teniendo en cuenta que hay una hoguera, esto a menudo significa una reunión o festividad. Luego, ver a las personas con atuendo tradicional implica un evento cultural. Fusionando estas observaciones, la actividad principal es bailar alrededor de la hoguera". |
Tenemos una lista de plantillas de inmediato que se pueden usar con diferentes formatos VQA. Verifique las prompts/templates/{dataset_name} .

Descargue y descomprima los archivos en el dataset/ carpeta para los conjuntos de datos VQA. Para Winogound , use la Biblioteca datasets de abrazaderas.
| Ok-vqa | AOK-VQA | GQA | Gangüenza | VQAV2 | |
|---|---|---|---|---|---|
| Fuente | Allenai | Allenai | Stanford | Cara abrazada | VQA |
Para ejecutar el VQA estándar, use el siguiente comando:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
Para ejecutar el subtítulo VQA, use el siguiente comando:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
Para ejecutar el VQA de la cadena de pensamiento, use el siguiente comando:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
Prepare el conjunto de datos del conjunto de datos dataset_zoo/nearest_neighbor.py y ejecute el siguiente comando:
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
Teniendo en cuenta las limitaciones de las métricas de precisión VQA en el contexto de la generación de respuestas abiertas, ofrecemos scripts de utilidad en evals/vicuna_llm_evals.py . Utilizando Vicuna LLM, estos scripts Process generaron respuestas para alinearse con las respuestas de referencia y posteriormente evaluarlas en función de la métrica VQA convencional.
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
Reportamos los resultados de base y la mejor configuración. Consulte el documento para obtener más resultados.
| Blip2 flan-t5 | Blip2 opt | Kosmos2 | Openflamingo | Llava | |
|---|---|---|---|---|---|
| Base | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| Mejor | 50.55 | 46.29 | 43.09 | 42.48 | 46.86 |
| Blip2 flan-t5 | Blip2 opt | Kosmos2 | Openflamingo | Llava | |
|---|---|---|---|---|---|
| Base | 51.20 | 45.57 | 40.85 | 17.27 | 52.69 |
| Mejor | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| Blip2 flan-t5 | Blip2 opt | Kosmos2 | Openflamingo | Llava | |
|---|---|---|---|---|---|
| Base | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| Mejor | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| Blip2 flan-t5 | Blip2 opt | Kosmos2 | Openflamingo | Llava | |
|---|---|---|---|---|---|
| Base | 66.66 | 54.53 | 53.52 | 35.41 | 56.2 |
| Mejor | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
Envíe un correo electrónico rabiul.awal [at] mila [dot] quebec para cualquier pregunta. También puede abrir una solicitud de problema o extraer para agregar más técnicas de solicitud o nuevos modelos de lenguaje de visión multimodal.
Si encuentra útil este código, cite nuestro documento:
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
La base de código se basa en la parte superior de los repositorios de Transformers, Lavis, Llava y Fastchat. Agradecemos a los autores por su increíble trabajo.


