vqazero
1.0.0
Rabiul Awal, Le Zhang 및 Aishwarya Agrawal
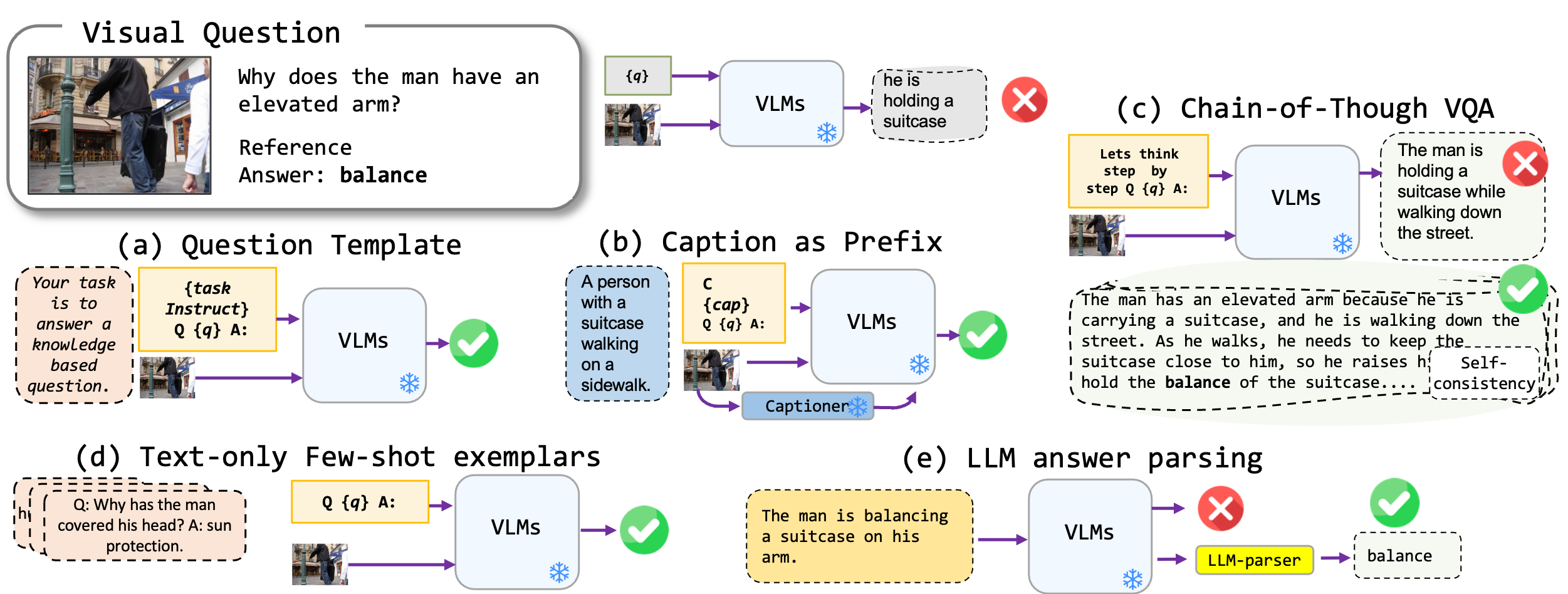
우리는 비전 언어 모델, 특히 최첨단 Blip2, Kosmos2, Openflamino 및 Multimodal Instruction-Tuned LLAVA에 적용되는 미세 조정이없는 프롬프트 기술을 탐구합니다. 우리는 주로 다음과 같은 프롬프트 접근법에 중점을 둡니다.
기존 비전 언어 모델 (VLMS)은 이미 좋은 제로 샷 VQA 성능을 보여줍니다. 우리의 프롬프트 기술 (특히 소수의 VQA에서 캡션)은 벤치 마크에서 실질적인 성능이 증가합니다. 그러나 교육 조정 모델은 강력한 추론 능력을 보여준 것으로 주장되지만, 우리의 테스트는 이러한 추론 능력, 특히 생각의 사슬이 다양한 벤치 마크가 부족하다는 것을 발견했습니다. 우리는 우리의 일 이이 방향으로 미래의 연구에 영감을주기를 바랍니다.
다음 VQA 형식을 지원합니다.
| 체재 | 설명 | 예 |
|---|---|---|
| 표준 VQA | 표준 VQA 작업 형식. | 질문 : "현장에서 사람들의 주요 활동은 무엇입니까?" 답 : "춤" |
| 캡션 VQA | 모델 생성 캡션으로 시작한 다음 표준 VQA 형식으로 시작합니다. | 맥락 : 전통적인 복장을 가진 사람들이 모닥불 주위에서 춤을 추고 있습니다. 질문 : "현장에서 사람들의 주요 활동은 무엇입니까?" 답 : "춤" |
| 생각한 체인 VQA | 생각한 사슬 형식을 구현합니다. | 질문 : "현장에서 사람들의 주요 활동은 무엇입니까? 단계별로 생각합시다." 답변 : "먼저, 모닥불이 있다는 것을 고려할 때, 이것은 종종 모임이나 축제를 의미합니다. 다음으로, 전통적인 복장의 사람들을 보는 것은 문화적 사건을 암시합니다. 이러한 관찰을 통합하면, 주요 활동은 모닥불 주위에서 춤을 추고 있습니다." |
다른 VQA 형식으로 사용할 수있는 프롬프트 템플릿 목록이 있습니다. prompts/templates/{dataset_name} 확인하십시오.

VQA 데이터 세트의 dataset/ 폴더에 파일을 다운로드하여 압축 해제하십시오. Winoground 의 경우 Hugging Face datasets 라이브러리를 사용하십시오.
| OK-VQA | AOK-VQA | GQA | winoground | vqav2 | |
|---|---|---|---|---|---|
| 원천 | 알레나이 | 알레나이 | 스탠포드 | 포옹 얼굴 | VQA |
표준 VQA를 실행하려면 다음 명령을 사용하십시오.
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
캡션 vqa를 실행하려면 다음 명령을 사용하십시오.
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
생각한 체인 VQA를 실행하려면 다음 명령을 사용하십시오.
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
예시적인 데이터 세트 데이터 dataset_zoo/nearest_neighbor.py 준비하고 다음 명령을 실행하십시오.
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
개방형 답변 생성의 맥락에서 VQA 정확도 메트릭의 제약을 고려할 때 evals/vicuna_llm_evals.py 에서 유틸리티 스크립트를 제공합니다. Vicuna LLM을 사용 하여이 스크립트 프로세스는 기준 응답과 정렬하여 기존 VQA 메트릭을 기반으로 평가하기 위해 답변을 생성했습니다.
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
우리는 기준선과 최상의 설정 결과를보고합니다. 더 많은 결과는 논문을 확인하십시오.
| blip2 flan-t5 | Blip2 opt | KOSMOS2 | Openflamingo | llava | |
|---|---|---|---|---|---|
| 기준선 | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| 최상의 | 50.55 | 46.29 | 43.09 | 42.48 | 46.86 |
| blip2 flan-t5 | Blip2 opt | KOSMOS2 | Openflamingo | llava | |
|---|---|---|---|---|---|
| 기준선 | 51.20 | 45.57 | 40.85 | 17.27 | 52.69 |
| 최상의 | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| blip2 flan-t5 | Blip2 opt | KOSMOS2 | Openflamingo | llava | |
|---|---|---|---|---|---|
| 기준선 | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| 최상의 | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| blip2 flan-t5 | Blip2 opt | KOSMOS2 | Openflamingo | llava | |
|---|---|---|---|---|---|
| 기준선 | 66.66 | 54.53 | 53.52 | 35.41 | 56.2 |
| 최상의 | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
궁금한 점이 있으면 rabiul.awal [at] mila [dot] quebec 이메일을 보내주십시오. 또한 더 많은 프롬프트 기술 또는 새로운 다중 모달 비전 언어 모델을 추가하기 위해 문제를 열거 나 풀어 요청을 할 수도 있습니다.
이 코드가 유용하다고 생각되면 논문을 인용하십시오.
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
코드베이스는 Transformers, Lavis, Llava 및 Fastchat 리포지토리 위에 있습니다. 우리는 그들의 놀라운 작품에 대해 저자들에게 감사합니다.


