vqazero
1.0.0
Rabiul Awal, Le Zhang e Aishwarya Agrawal
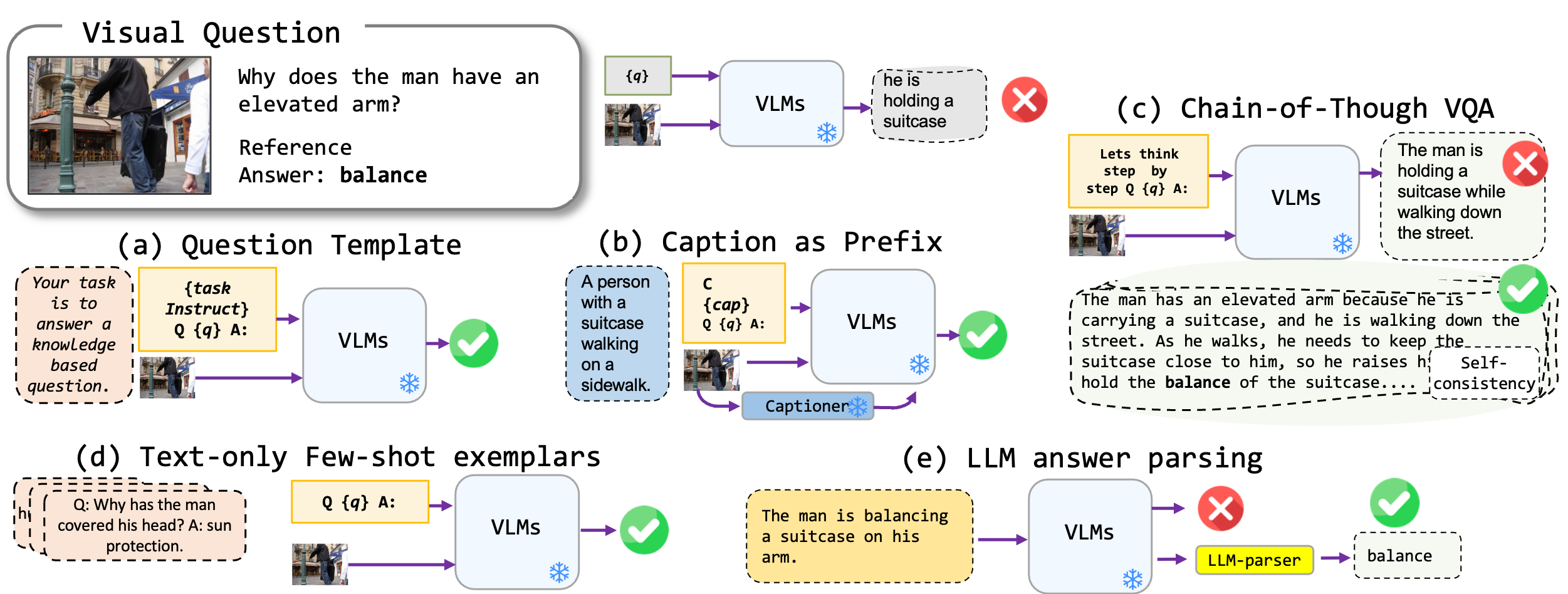
Exploramos as técnicas de prontificação sem ajuste fino aplicadas a modelos de linguagem de visão, especificamente BLIP2 de última geração, Kosmos2, OpenFlamino e Llava de instrução multimodal. Nós nos concentramos principalmente nas seguintes abordagens de promoção:
Os modelos existentes de linguagem de visão (VLMs) já mostram um bom desempenho VQA com tiro zero. Nossas técnicas de promoção (especialmente a legenda no VQA de poucos tiros) levam a um aumento substancial de desempenho nos benchmarks. No entanto, embora os modelos ajustados por instrução sejam reivindicados para mostrar fortes habilidades de raciocínio, nossos testes encontraram essas habilidades de raciocínio, particularmente a cadeia de pensamentos, deficientes em diversos benchmarks. Esperamos que nosso trabalho inspire pesquisas futuras nessa direção.
Apoiamos os seguintes formatos VQA:
| Formatar | Descrição | Exemplo |
|---|---|---|
| VQA padrão | Formato de tarefa VQA padrão. | Pergunta : "Qual é a atividade principal das pessoas na cena?" Resposta : "dançando" |
| Legenda VQA | Começa com uma legenda gerada pelo modelo e depois formato VQA padrão. | Contexto : Um grupo de pessoas em trajes tradicionais está dançando em torno de uma fogueira. Pergunta : "Qual é a atividade principal das pessoas na cena?" Resposta : "dançando" |
| VQA da cadeia de pensamento | Implementa o formato da cadeia de pensamento. | Pergunta : "Qual é a atividade principal das pessoas na cena? Vamos pensar passo a passo". Resposta : "Primeiro, considerando que há uma fogueira, isso geralmente significa uma reunião ou festa. Em seguida, ver pessoas em trajes tradicionais implica um evento cultural. Fusão dessas observações, a atividade primária está dançando ao redor da fogueira". |
Temos uma lista de modelos de prompt que podem ser usados com diferentes formatos VQA. Verifique os prompts/templates/{dataset_name} .

Faça o download e descompacte os arquivos no dataset/ pasta para os conjuntos de dados VQA. Para o WinogRound , use a biblioteca datasets de face Hugging.
| OK-VQA | AOK-VQA | GQA | WinogRound | VQAV2 | |
|---|---|---|---|---|---|
| Fonte | Allenai | Allenai | Stanford | Abraçando o rosto | VQA |
Para executar o VQA padrão, use o seguinte comando:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
Para executar a legenda VQA, use o seguinte comando:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
Para executar o VQA da cadeia de pensamento, use o seguinte comando:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
Prepare o DataSet DataSet Examplar dataset_zoo/nearest_neighbor.py e execute o seguinte comando:
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
Considerando as restrições das métricas de precisão do VQA no contexto da geração de respostas abertas, oferecemos scripts de serviços públicos em evals/vicuna_llm_evals.py . Usando a Vicuna LLM, esses scripts do processo geraram respostas para se alinhar com as respostas de referência e subsequentemente as avaliam com base na métrica VQA convencional.
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
Relatamos os resultados da linha de base e da melhor configuração. Verifique o papel para obter mais resultados.
| BLIP2 FLAN-T5 | BLIP2 OPT | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Linha de base | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| Melhor | 50.55 | 46.29 | 43.09 | 42.48 | 46.86 |
| BLIP2 FLAN-T5 | BLIP2 OPT | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Linha de base | 51.20 | 45.57 | 40,85 | 17.27 | 52.69 |
| Melhor | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| BLIP2 FLAN-T5 | BLIP2 OPT | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Linha de base | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| Melhor | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| BLIP2 FLAN-T5 | BLIP2 OPT | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Linha de base | 66.66 | 54.53 | 53.52 | 35.41 | 56.2 |
| Melhor | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
Envie um email para rabiul.awal [at] mila [dot] quebec para qualquer dúvida. Você também pode abrir uma solicitação de problema ou puxar para adicionar mais técnicas de promoção ou novos modelos multimodais de linguagem de visão.
Se você achar esse código útil, cite nosso artigo:
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
A base de código é construída sobre os repositórios de Transformers, Lavis, Llava e FastChat. Agradecemos aos autores por seu incrível trabalho.


