vqazero
1.0.0
Rabiul Awal、Le Zhang、Aishwarya Agrawal
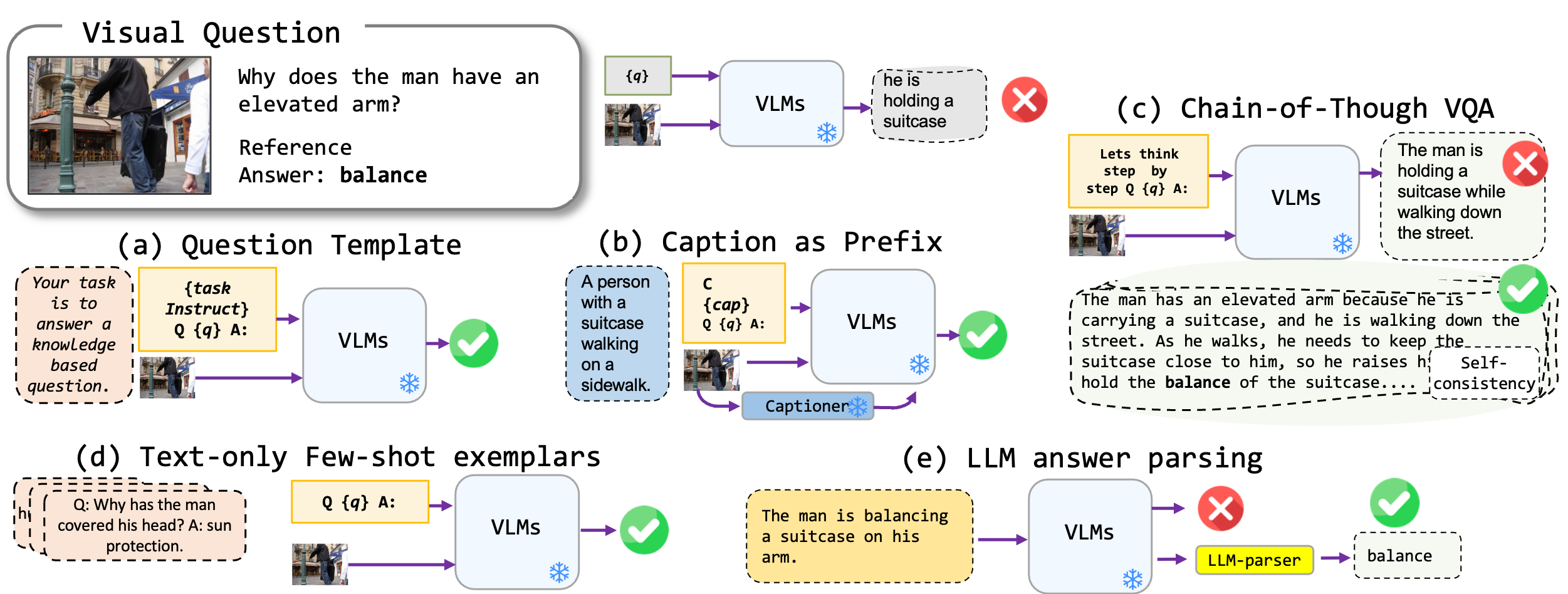
ビジョン言語モデル、特に最先端のBLIP2、KOSMOS2、Openflamino、Multimodal命令チューニングLLAVAに適用される微調整のないプロンプト技術を探索します。主に、次のプロンプトアプローチに焦点を当てています。
既存のビジョン言語モデル(VLM)は、すでに優れたゼロショットVQAパフォーマンスを示しています。私たちのプロンプトテクニック(特に少数のショットVQAでのキャプション)は、ベンチマーク全体で大幅なパフォーマンスの向上をもたらします。ただし、命令チューニングされたモデルは強力な推論能力を示すと主張されていますが、私たちのテストでは、これらの推論能力、特に思考の連鎖が多様なベンチマークに不足していることがわかりました。私たちの仕事がこの方向における将来の研究を刺激することを願っています。
次のVQA形式をサポートしています。
| 形式 | 説明 | 例 |
|---|---|---|
| 標準VQA | 標準VQAタスク形式。 | 質問:「現場の人々の主な活動は何ですか?」 回答:「ダンス」 |
| キャプションVQA | モデル生成キャプションから始まり、次に標準のVQA形式です。 | コンテキスト:伝統的な服装の人々のグループは、bonき火の周りで踊っています。 質問:「現場の人々の主な活動は何ですか?」 回答:「ダンス」 |
| チェーンオブサブVQA | 考え方の形式を実装します。 | 質問:「現場の人々の主な活動は何ですか?段階的に考えてみましょう。」 回答:「まず、bonき火があることを考えると、これはしばしば集まりや祝祭を意味します。次に、伝統的な服装を着る人々を見ることは文化的な出来事を意味します。これらの観察を融合して、主要な活動はbonき火の周りで踊っています。」 |
さまざまなVQA形式で使用できるプロンプトテンプレートのリストがあります。 prompts/templates/{dataset_name}を確認してください。

VQAデータセットのファイルをdataset/フォルダーにダウンロードして解凍します。 Winogroundには、ハグするFace datasetsライブラリを使用してください。
| OK-VQA | aok-vqa | GQA | ウィングラウンド | VQAV2 | |
|---|---|---|---|---|---|
| ソース | アレナイ | アレナイ | スタンフォード | 顔を抱き締める | VQA |
標準VQAを実行するには、次のコマンドを使用します。
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
キャプションVQAを実行するには、次のコマンドを使用します。
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
思考のチェーンVQAを実行するには、次のコマンドを使用します。
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
Examplar Dataset dataset_zoo/nearest_neighbor.pyを準備して、次のコマンドを実行してください。
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
自由回答形式の回答生成のコンテキストでのVQA精度メトリックの制約を考慮すると、 evals/vicuna_llm_evals.pyのユーティリティスクリプトを提供します。 Vicuna LLMを使用して、これらのスクリプトは、生成された回答をプロセスして、参照応答と整合し、その後、従来のVQAメトリックに基づいてそれらを評価しました。
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
ベースラインと最良の設定の結果を報告します。その他の結果については、論文を確認してください。
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| ベースライン | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| 最高 | 50.55 | 46.29 | 43.09 | 42.48 | 46.86 |
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| ベースライン | 51.20 | 45.57 | 40.85 | 17.27 | 52.69 |
| 最高 | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| ベースライン | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| 最高 | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | llava | |
|---|---|---|---|---|---|
| ベースライン | 66.66 | 54.53 | 53.52 | 35.41 | 56.2 |
| 最高 | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
質問についてはrabiul.awal [at] mila [dot] quebecメールしてください。また、問題を開いたり、リクエストをプルして、さらにプロンプトテクニックまたは新しいマルチモーダルビジョン言語モデルを追加することもできます。
このコードが便利だと思う場合は、私たちの論文を引用してください。
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
コードベースは、トランス、LAVIS、LLAVA、FastChatリポジトリの上に構築されています。著者の素晴らしい仕事に感謝します。


