vqazero
1.0.0
Rabiul Awal, Le Zhang dan Aishwarya Agrawal
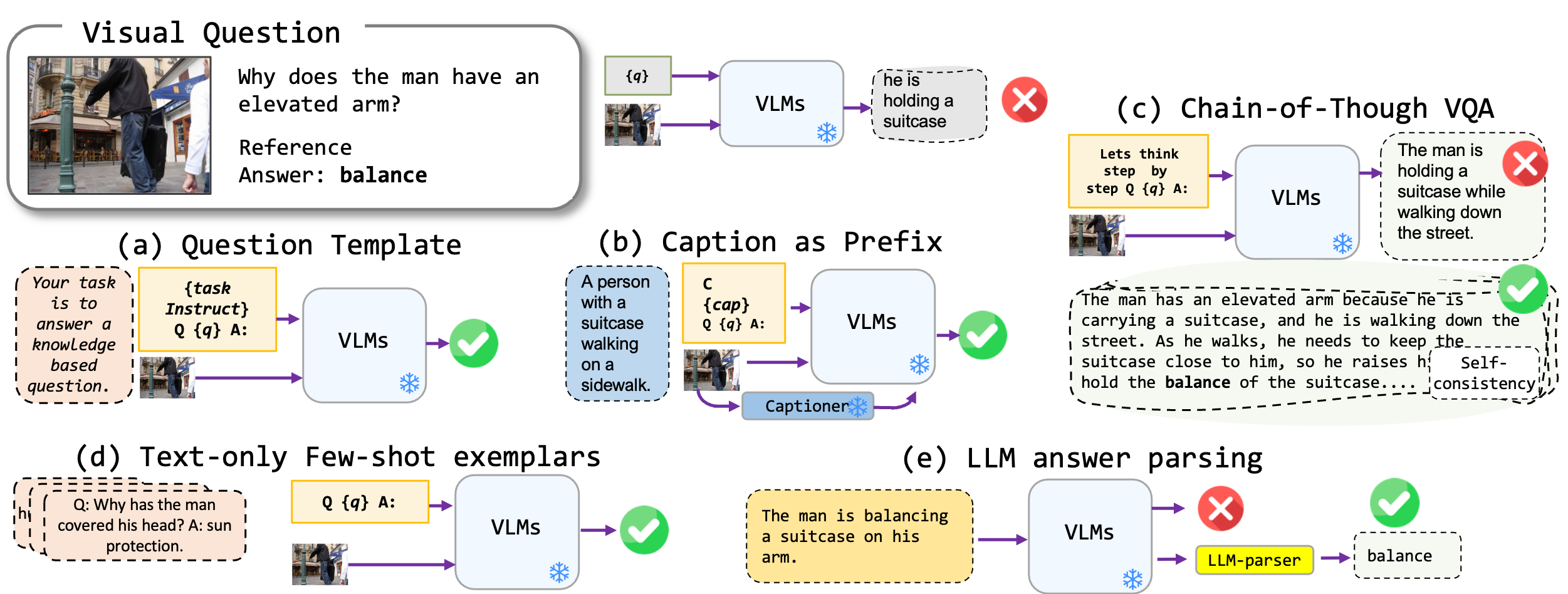
Kami mengeksplorasi teknik-teknik pendakian bebas-fine-tuning yang diterapkan pada model penglihatan-bahasa, khususnya Blip2, Kosmos2, OpenFlamino, dan LLAVA yang disesuaikan dengan instruksi multimodal. Kami terutama fokus pada pendekatan yang diminta berikut:
Model Visi-Bahasa yang Ada (VLM) sudah menunjukkan kinerja VQA nol-shot yang baik. Teknik-teknik pendorong kami (terutama teks dalam beberapa-shot VQA) menyebabkan peningkatan kinerja yang substansial di seluruh tolok ukur. Namun, meskipun model yang disesuaikan dengan instruksi diklaim menunjukkan kemampuan penalaran yang kuat, tes kami menemukan kemampuan penalaran ini, terutama rantai yang dipikirkan, lebih kekurangan dalam berbagai tolok ukur. Kami berharap pekerjaan kami akan menginspirasi penelitian di masa depan ke arah ini.
Kami mendukung format VQA berikut:
| Format | Keterangan | Contoh |
|---|---|---|
| VQA standar | Format tugas VQA standar. | Pertanyaan : "Apa aktivitas utama orang -orang di tempat kejadian?" Jawaban : "Menari" |
| Keterangan VQA | Dimulai dengan keterangan model yang dihasilkan, lalu format VQA standar. | Konteks : Sekelompok orang dalam pakaian tradisional menari di sekitar api unggun. Pertanyaan : "Apa aktivitas utama orang -orang di tempat kejadian?" Jawaban : "Menari" |
| VQA rantai-dipikirkan | Mengimplementasikan format rantai-dipikirkan. | Pertanyaan : "Apa aktivitas utama orang-orang dalam adegan itu? Mari kita pikirkan langkah demi langkah." Jawaban : "Pertama, mengingat ada api unggun, ini sering menandakan pertemuan atau perayaan. Selanjutnya, melihat orang -orang dalam pakaian tradisional menyiratkan peristiwa budaya. Menggabungkan pengamatan ini, aktivitas utama menari di sekitar api unggun." |
Kami memiliki daftar templat cepat yang dapat digunakan dengan format VQA yang berbeda. Silakan periksa prompts/templates/{dataset_name} .

Unduh dan unzip file ke dalam dataset/ folder untuk set data VQA. Untuk Winoground , gunakan perpustakaan datasets Wajah Memeluk.
| OK-VQA | AOK-VQA | GQA | Winoground | VQAV2 | |
|---|---|---|---|---|---|
| Sumber | Allenai | Allenai | Stanford | Wajah memeluk | VQA |
Untuk menjalankan VQA standar, gunakan perintah berikut:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
Untuk menjalankan keterangan VQA, gunakan perintah berikut:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
Untuk menjalankan VQA rantai-dipikirkan, gunakan perintah berikut:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
Harap persiapkan examplar dataset dataset_zoo/nearest_neighbor.py dan jalankan perintah berikut:
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
Mempertimbangkan kendala metrik akurasi VQA dalam konteks pembuatan jawaban terbuka, kami menawarkan skrip utilitas di evals/vicuna_llm_evals.py . Menggunakan Vicuna LLM, proses skrip ini menghasilkan jawaban untuk menyelaraskan dengan respons referensi dan kemudian mengevaluasinya berdasarkan metrik VQA konvensional.
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
Kami melaporkan hasil dasar dan pengaturan terbaik. Silakan periksa kertas untuk hasil lebih lanjut.
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Baseline | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| Terbaik | 50.55 | 46.29 | 43.09 | 42.48 | 46.86 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Baseline | 51.20 | 45.57 | 40.85 | 17.27 | 52.69 |
| Terbaik | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Baseline | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| Terbaik | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| Blip2 Flan-T5 | Blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| Baseline | 66.66 | 54.53 | 53.52 | 35.41 | 56.2 |
| Terbaik | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
Silakan kirim email ke rabiul.awal [at] mila [dot] quebec untuk pertanyaan apa pun. Anda juga dapat membuka masalah atau menarik permintaan untuk menambahkan lebih banyak teknik yang diminta atau model bahasa multi-modal baru.
Jika Anda menemukan kode ini bermanfaat, silakan kutip kertas kami:
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
Basis kode ini dibangun di atas transformator, lavis, llava dan repositori fastchat. Kami berterima kasih kepada penulis atas pekerjaan mereka yang luar biasa.


