vqazero
1.0.0
Rabiul Awal, Le Zhang และ Aishwarya Agrawal
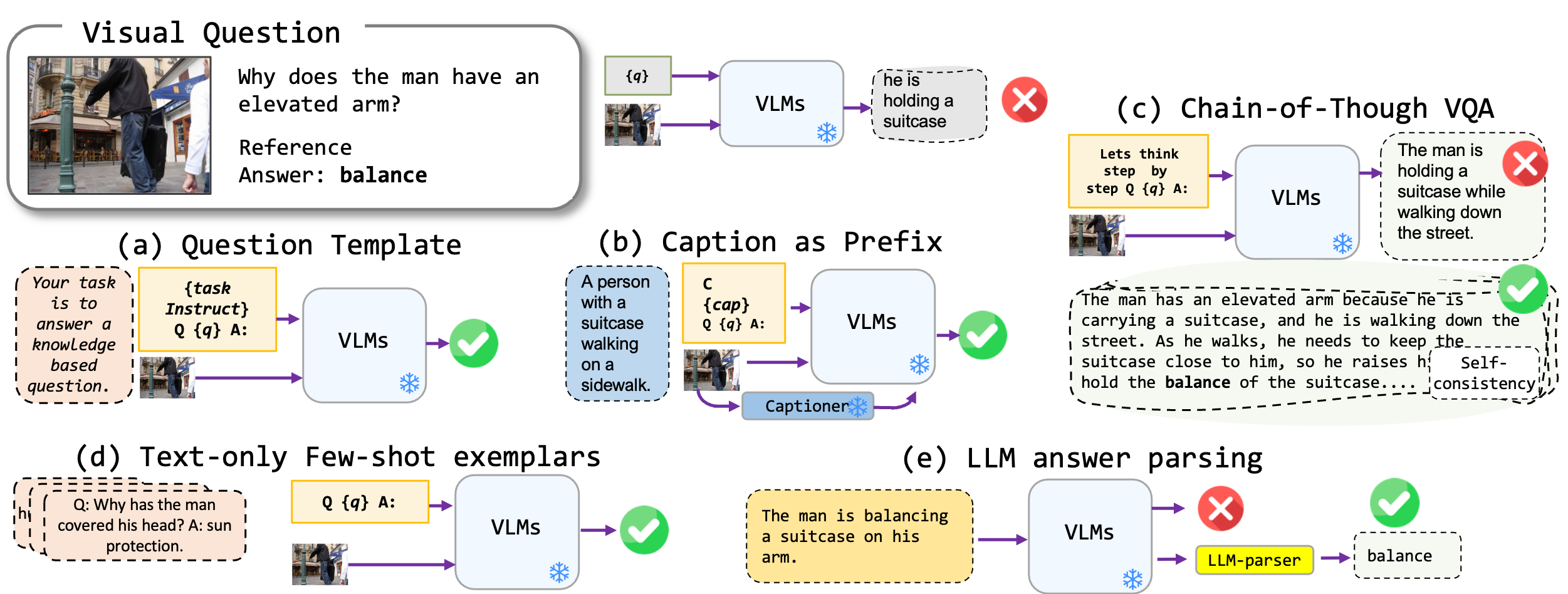
เราสำรวจเทคนิคการแจ้งเตือนที่ปราศจากการปรับแต่งอย่างละเอียดที่ใช้กับโมเดล Vision-Language โดยเฉพาะอย่างยิ่ง Blip2, Kosmos2, OpenFlamino และ LLAVA ที่ได้รับการปรับแต่งหลายรูปแบบ เรามุ่งเน้นไปที่วิธีการแจ้งเตือนต่อไปนี้:
รุ่น Vision-Language ที่มีอยู่ (VLMS) แสดงประสิทธิภาพ VQA ที่ดีเป็นศูนย์ เทคนิคการแจ้งเตือนของเรา (โดยเฉพาะคำบรรยายภาพใน VQA ไม่กี่ครั้ง) นำไปสู่ประสิทธิภาพที่เพิ่มขึ้นอย่างมากในการเปรียบเทียบ อย่างไรก็ตามแม้ว่าแบบจำลองที่ได้รับการปรับแต่งจะอ้างว่าแสดงความสามารถในการใช้เหตุผลที่แข็งแกร่ง แต่การทดสอบของเราพบความสามารถในการใช้เหตุผลเหล่านี้โดยเฉพาะอย่างยิ่งห่วงโซ่ของความคิดที่จะขาดการวัดประสิทธิภาพที่หลากหลาย เราหวังว่างานของเราจะเป็นแรงบันดาลใจให้การวิจัยในอนาคตในทิศทางนี้
เราสนับสนุนรูปแบบ VQA ต่อไปนี้:
| รูปแบบ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| VQA มาตรฐาน | รูปแบบงาน VQA มาตรฐาน | คำถาม : "กิจกรรมหลักของผู้คนในฉากคืออะไร" คำตอบ : "การเต้นรำ" |
| คำบรรยายภาพ VQA | เริ่มต้นด้วยคำบรรยายภาพที่สร้างจากแบบจำลองจากนั้นรูปแบบ VQA มาตรฐาน | บริบท : กลุ่มคนในชุดแบบดั้งเดิมกำลังเต้นรำกับกองไฟ คำถาม : "กิจกรรมหลักของผู้คนในฉากคืออะไร" คำตอบ : "การเต้นรำ" |
| VQA โซ่แห่งความคิด | ใช้รูปแบบห่วงโซ่ความคิด | คำถาม : "กิจกรรมหลักของผู้คนในฉากคืออะไรลองคิดทีละขั้นตอน" คำตอบ : "ก่อนอื่นเมื่อพิจารณาว่ามีกองไฟสิ่งนี้มักหมายถึงการชุมนุมหรืองานรื่นเริงต่อไปการเห็นผู้คนในชุดแบบดั้งเดิมหมายถึงเหตุการณ์ทางวัฒนธรรมการรวมการสังเกตเหล่านี้กิจกรรมหลักคือการเต้นรอบกองไฟ" |
เรามีรายการเทมเพลตพรอมต์ที่สามารถใช้กับรูปแบบ VQA ที่แตกต่างกัน โปรดตรวจสอบ prompts/templates/{dataset_name}

ดาวน์โหลดและคลายซิปไฟล์ลงใน dataset/ โฟลเดอร์สำหรับชุดข้อมูล VQA สำหรับ Winoground ให้ใช้ห้องสมุดชุด datasets Hugging Face
| OK-VQA | aok-vqa | GQA | Winoground | VQAV2 | |
|---|---|---|---|---|---|
| แหล่งที่มา | อัลลีนี | อัลลีนี | สแตนฟอร์ด | กอดใบหน้า | VQA |
ในการเรียกใช้ VQA มาตรฐานให้ใช้คำสั่งต่อไปนี้:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
ในการเรียกใช้คำบรรยายภาพ VQA ให้ใช้คำสั่งต่อไปนี้:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format caption_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer,prefix_promptcap
ในการเรียกใช้ VQA ที่ใช้ความคิดใช้ให้ใช้คำสั่งต่อไปนี้:
python3 main.py --dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format cot_vqa
--prompt_name prefix_think_step_by_step_rationale
โปรดเตรียมชุดข้อมูลชุดข้อมูล Examplar dataset_zoo/nearest_neighbor.py และเรียกใช้คำสั่งต่อไปนี้:
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser --few_shot
เมื่อพิจารณาถึงข้อ จำกัด ของตัวชี้วัดความแม่นยำ VQA ในบริบทของการสร้างคำตอบปลายเปิดเรานำเสนอสคริปต์ยูทิลิตี้ใน evals/vicuna_llm_evals.py การใช้ Vicuna LLM กระบวนการสคริปต์เหล่านี้สร้างคำตอบให้สอดคล้องกับการตอบสนองอ้างอิงและประเมินพวกเขาตามตัวชี้วัด VQA ทั่วไป
python3 main.py
--dataset_name okvqa
--model_name blip2_t5_flant5xxl
--vqa_format standard_vqa
--prompt_name prefix_your_task_knowledge_qa_short_answer
--vicuna_ans_parser
เรารายงานพื้นฐานและการตั้งค่าที่ดีที่สุด โปรดตรวจสอบกระดาษเพื่อดูผลลัพธ์เพิ่มเติม
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| พื้นฐาน | 50.13 | 42.7 | 40.33 | 18.29 | 44.84 |
| ดีที่สุด | 50.55 | 46.29 | 43.09 | 42.48 | 46.86 |
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| พื้นฐาน | 51.20 | 45.57 | 40.85 | 17.27 | 52.69 |
| ดีที่สุด | 54.98 | 49.39 | 43.60 | 44.13 | 52.32 |
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| พื้นฐาน | 44.46 | 38.46 | 37.33 | 26.37 | 38.40 |
| ดีที่สุด | 47.01 | 41.99 | 40.13 | 41.00 | 42.65 |
| blip2 flan-t5 | blip2 opt | Kosmos2 | OpenFlamingo | Llava | |
|---|---|---|---|---|---|
| พื้นฐาน | 66.66 | 54.53 | 53.52 | 35.41 | 56.2 |
| ดีที่สุด | 71.37 | 62.81 | 57.33 | 58.0 | 65.32 |
โปรดส่งอีเมล rabiul.awal [at] mila [dot] quebec สำหรับคำถามใด ๆ นอกจากนี้คุณยังสามารถเปิดปัญหาหรือดึงคำขอเพื่อเพิ่มเทคนิคการแจ้งเตือนเพิ่มเติมหรือโมเดลภาษาวิสัยทัศน์แบบหลายโหมดใหม่
หากคุณพบว่ารหัสนี้มีประโยชน์โปรดอ้างอิงกระดาษของเรา:
@article{awal2023investigating,
title={Investigating Prompting Techniques for Zero-and Few-Shot Visual Question Answering},
author={Awal, Rabiul and Zhang, Le and Agrawal, Aishwarya},
journal={arXiv preprint arXiv:2306.09996},
year={2023}
}
Codebase สร้างขึ้นที่ด้านบนของ Transformers, Lavis, Llava และที่เก็บ Fastchat เราขอขอบคุณผู้เขียนสำหรับงานที่น่าทึ่งของพวกเขา


