Awesome Prompting on Vision Language Model
1.0.0
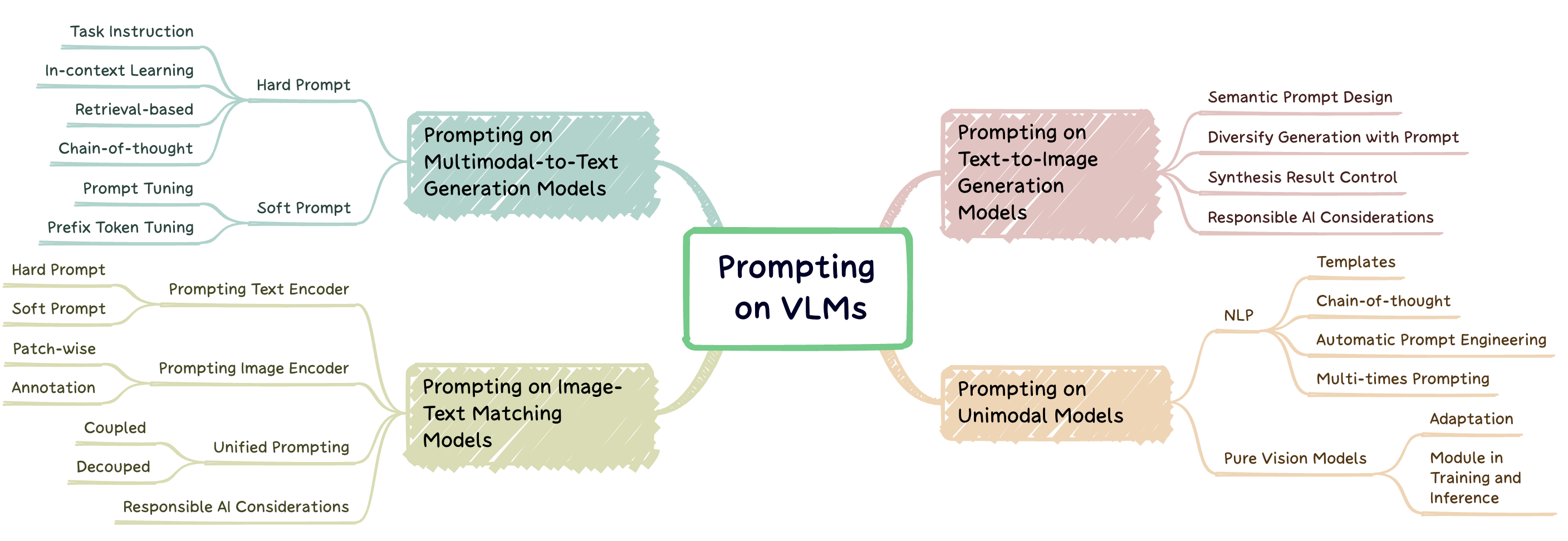
及時工程是一種技術,涉及通過使用特定於任務提示的大型預訓練模型(稱為提示)將模型調整為新任務。該倉庫旨在對三種類型的視覺模型(VLM)進行迅速工程的尖端研究進行全面調查:多模態到文本生成模型(例如,Flamingo),圖像文本匹配模型(例如,clip)和文本到圖像形象的模型(例如,穩定的擴散)(例如,穩定的擴散)(圖1)。
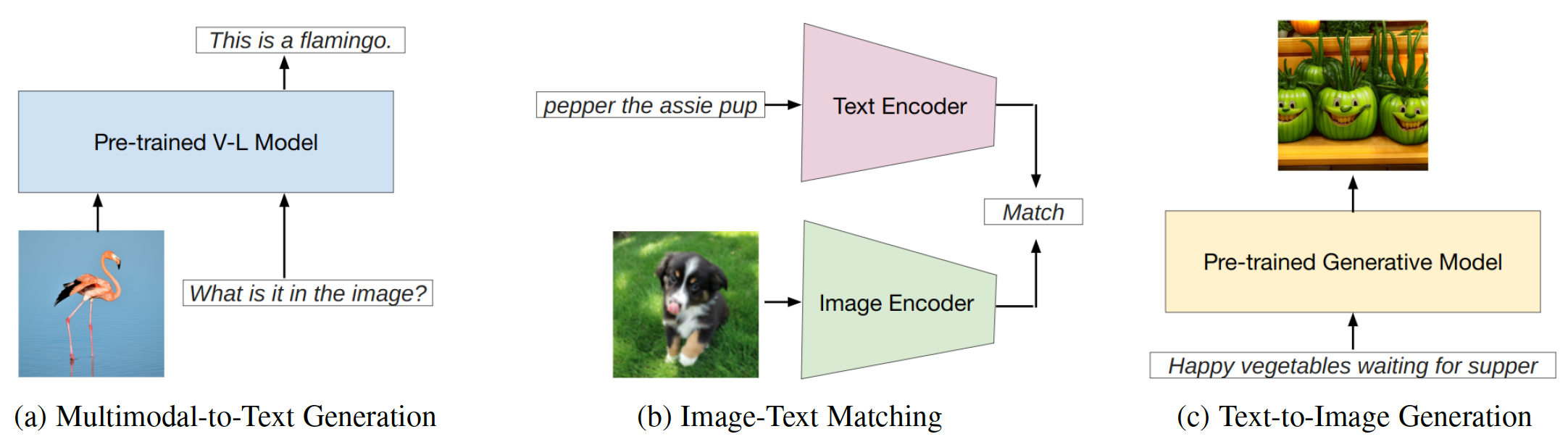
圖1:這項工作集中於三種主要視覺語言模型。
該回購列出了我們調查中總結的相關論文:
對視覺基礎模型的迅速工程的系統調查。 Jindong Gu,Zhen Han,Shuo Chen,Ahmad Beirami,Bailan HE,Gengyuan Zhang,Ruotong Liao,Yao Qin,Volker Tresp,Philip Torr 。預印度2023。 [PDF]
如果您發現我們的論文和回購對您的研究有幫助,請引用以下論文:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}在多模式到文本生成中提示模型
在圖像文本匹配中提示模型
在文本到圖像中提示模型
基於視覺和文本模式的集成,有兩種主要類型的融合模塊方法:編碼器解碼器作為多模式融合模塊,而僅作為多模式融合模塊將其作為多模式融合模塊。提示方法可以根據模板的可讀性分為兩個主要類別(圖2):硬提示和軟提示。硬提示包括四個子類別:任務指令,內在學習,基於檢索的提示和經過思考鏈的提示。軟提示分為兩種策略:提示調諧和前綴令牌調整,這是根據內部內部添加新令牌的新令牌,還是只將它們添加到輸入中。這項研究主要集中於避免改變基本模型的及時方法。
圖2:提示方法的分類。
| 標題 | 場地 | 年 | 代碼如果有的話 | 評論 |
|---|---|---|---|---|
| 通過文本生成統一視覺和語言任務 | ICML | 2021 | github | 編碼器融合;文字前綴作為提示 |
| SIMVLM:簡單的視覺語言模型,並通過弱監督進行預處理 | ICLR | 2022 | github | 編碼器融合;文字前綴作為提示 |
| OFA:通過一個簡單的順序學習框架統一體系結構,任務和方式 | ICML | 2022 | github | 編碼器融合;文字前綴作為提示 |
| 巴利人:一個共同刻度的多語言圖像模型 | ICLR | 2023 | --- | 編碼器融合;說明提示 |
| 多式聯運的幾次學習與冷凍語言模型 | 神經 | 2021 | 頁 | 僅解碼器融合;圖像條件前綴調整 |
| Flamingo:一種用於幾次學習的視覺語言模型 | 神經 | 2022 | github | 僅解碼器融合;文本提示; |
| 岩漿 - 通過基於適配器的填充的生成模型的多模式增強 | emnlp | 2022 | github | 僅解碼器融合;圖像條件前綴調整 |
| BLIP-2:引導語言圖像預訓練,並用冷凍圖像編碼器和大型語言模型 | ICML | 2023 | github | 僅解碼器融合;圖像條件前綴調整 |
| 語言模型是無監督的多任務學習者 | Openai博客 | 2019 | github | 任務說明提示 |
| 土耳其測試:語言模型可以理解說明嗎? | arxiv | 2020 | --- | 任務說明提示 |
| 語言模型是很少的學習者 | 神經 | 2020 | --- | 在文化學習中 |
| 學會檢索提示中的內在學習 | naacl-hlt | 2022 | github | 基於檢索的提示 |
| 統一的演示檢索器用於內在學習 | ACL | 2023 | github | 基於檢索的提示 |
| 秘密學習的組成示例 | ICML | 2023 | github | 基於檢索的提示 |
| 經過思考的鏈條提示在大語言模型中引起推理 | 神經 | 2022 | --- | 經過思考鏈的提示 |
| 自動思想鏈在大型語言模型中提示 | ICLR | 2023 | github | 經過思考鏈的提示 |
| 參數有效提示調整的比例功能 | emnlp | 2021 | --- | 及時調整 |
| 學習如何提出:用軟提示的混合物查詢LMS | naacl-hlt | 2021 | github | 及時調整 |
| 前綴調整:優化發電的連續提示 | ACL | 2021 | github | 前綴調整 |
| 及時調整生成多模式預審預週座模型 | ACL | 2023 | github | 及時調整OFA |
| 語言不是您所需要的:將感知與語言模型保持一致 | 神經 | 2023 | github | 文本說明提示 |
| 在預訓練的視力語言模型上對適應方法的魯棒性進行基準測試 | 神經 | 2024 | 頁 | 迅速調整VLM的魯棒性 |
| 朝著視覺模型的強大提示 | NextGenaisafety@iclr | 2024 | --- | 迅速調整VLM的魯棒性 |
| 指示燈:使用指令調整的通用視覺語言模型 | 神經 | 2023 | github | 及時調整 |
| 視覺說明調整 | 神經 | 2023 | github | |
| QWEN-VL:用於理解,本地化,文本閱讀以及以下的多功能視覺語言模型 | arxiv | 2023 | github | 及時調整 |
| Shikra:釋放多模式LLM的參考對話魔術 | arxiv | 2023 | github | |
| Minigpt-4:通過高級大語言模型增強視力語言理解 | ICLR | 2023 | github | 及時調整 |
根據提示的目標,可以將現有方法分為三類:提示文本編碼,提示視覺編碼器或共同提示兩個分支,如圖2所示。這些方法旨在增強VLM的靈活性和特定於任務的性能。
圖2:圖像文本匹配VLMS上提示方法的分類。
| 標題 | 場地 | 年 | 代碼如果有的話 | 評論 |
|---|---|---|---|---|
| 從自然語言監督中學習可轉移的視覺模型 | ICML | 2021 | github | 硬文字提示;提示圖像分類 |
| 深入研究剪輯的開放性 | ACL | 2023 | github | 硬文字提示理解 |
| 測試時間及時調整視覺模型中的零彈性概括 | 神經 | 2022 | github | 軟文本提示 |
| 學會提示視覺模型 | IJCV | 2022 | github | 軟文本提示 |
| 促使視覺語言模型以有效的視頻理解 | ECCV | 2022 | github | 軟文本提示 |
| 多任務視覺語言提示調諧 | WACV | 2024 | github | 軟文本提示 |
| 有條件地學習視覺模型 | CVPR | 2022 | github | 軟文本提示 |
| 視覺提示調整 | ECCV | 2022 | github | 視覺貼片提示 |
| 探索視覺提示以適應大型模型 | arxiv | 2022 | github | 視覺貼片提示 |
| 多任務視覺語言提示調諧 | WACV | 2024 | github | 視覺貼片提示 |
| 釋放在像素級別的視覺提示的力量 | TMLR | 2024 | github | 視覺貼片提示 |
| 多樣性感知的元視覺提示 | CVPR | 2023 | github | 視覺貼片提示 |
| CPT:為預訓練的視力語言模型進行色彩及時調整 | AI開放 | 2024 | github | 視覺註釋提示 |
| 剪輯對紅色圓圈有什麼了解? VLM的視覺及時工程 | ICCV | 2023 | --- | 視覺註釋提示 |
| 視覺提示通過圖像介入 | 神經 | 2022 | github | 視覺註釋提示 |
| 統一的視覺和語言及時學習 | arxiv | 2023 | github | 耦合統一提示 |
| 多任務視覺語言提示調諧 | WACV | 2024 | github | 解耦統一提示 |
| 楓樹:多模式提示學習 | CVPR | 2023 | github | 解耦統一提示 |
| 了解大型型號的零拍對對抗性魯棒性 | ICLR | 2023 | 代碼 | 迅速的對抗性魯棒性 |
| 視覺提示對抗性魯棒性 | ICASSP | 2023 | github | 迅速的對抗性魯棒性 |
| 保險絲前對齊:視覺和語言表示學習動量蒸餾 | 神經 | 2021 | github | 圖像文本匹配模型 |
| 無監督的及時學習視覺模型 | arxiv | 2022 | github | 無治的可學習提示 |
| 測試時間及時調整視覺模型中的零彈性概括 | 神經 | 2022 | github | 可學習的提示 |
| 及時進行預訓練,以超過2萬個班級進行開放式視覺識別 | 神經 | 2023 | github | 提示預訓練 |
| 一致性引導的及時學習視覺模型 | ICLR | 2024 | --- | 解耦統一提示 |
| 改善視覺模型的有效傳輸學習的適應性和概括性 | ACL arr | 2024 | --- | 可學習的提示 |
| 標題 | 場地 | 年 | 代碼如果有的話 | 評論 |
|---|---|---|---|---|
| LMPT:及時調整長尾部多標籤視覺識別的特定班級嵌入損失 | Alvr | 2024 | github | 提示長尾多標籤圖像分類 |
| 測試時間及時調整視覺模型中的零彈性概括 | 神經 | 2022 | github | 可學習的提示;圖像分類提示 |
| LPT:長尾及時調整圖像分類 | ICLR | 2023 | github | 提示長尾圖像分類 |
| 文本作為圖像,以迅速調整多標籤圖像識別 | CVPR | 2023 | github | 提示多標籤圖像分類和檢測 |
| DualCoop:快速適應多標籤識別,註釋有限 | 神經 | 2022 | github | 多標籤圖像分類和識別提示 |
| 視覺提示調整幾次播種文本分類 | ICCL | 2022 | --- | 視覺提示文本分類 |
| 通過視覺和語言知識蒸餾的開放式攝製對象檢測 | ICLR | 2021 | github | 提示對象檢測 |
| 學會通過視覺語言模型提示開放式視頻對象檢測 | CVPR | 2022 | github | 提示對象檢測 |
| 提示:使用未經切割的圖像朝開放式攝取檢測 | ECCV | 2022 | github | 提示對象檢測 |
| 通過調節來優化連續的提示以進行視覺關係檢測 | IEEE訪問 | 2022 | --- | 軟提示以進行視覺關係檢測 |
| 朝著開放式視頻範圍場景圖生成及時基於基於迅速的登錄 | ECCV | 2022 | --- | 軟提示以進行視覺關係檢測 |
| 用運動提示進行構圖提示調整開放式視頻關係檢測 | ICLR | 2023 | github | 關係提示進行視頻開放式攝影關係檢測 |
| DENSECLIP:語言引導密集的預測,並引起上下文感知 | CVPR | 2022 | github | 班級條件的文本提示,用於語義細分 |
| 細分任何東西 | ICCV | 2023 | github | 迅速的語義細分查詢 |
| 通過及時學習適應域 | IEEE | 2023 | github | 特定領域的文本提示域適應 |
| 視覺提示調整測試時間域的適應 | arxiv | 2022 | --- | 提示域適應 |
| 學習提示持續學習 | CVPR | 2022 | github | 提示持續學習 |
| 雙提示:互補提示無彩排的持續學習 | ECCV | 2022 | github | 提示持續學習 |
| 迅速的視力變壓器用於域概括 | arxiv | 2022 | github | 提示域概括 |
| 了解大型型號的零拍對對抗性魯棒性 | lclr | 2022 | github | 在對抗攻擊下進行視覺及時調節 |
| 視覺提示對抗性魯棒性 | ICASSP | 2023 | github | 視覺提示提高對抗性魯棒性 |
| 探索基於迅速的學習範式的普遍脆弱性 | Naacl | 2022 | github | 視覺提示漏洞 |
| 中毒和後門對比度學習 | ICLR | 2022 | --- | 剪輯上的後門和中毒攻擊 |
| BadEncoder:在自學學習中對預訓練的編碼者進行的後門攻擊 | IEEE | 2022 | github | 剪輯的後門攻擊 |
| CleanClip:減輕多模式對比學習中的數據中毒攻擊 | ICLR研討會 | 2023 | --- | 防禦後門攻擊剪輯 |
| 通過有偏見的提示來使視覺語言模型 | arxiv | 2023 | github | 提示減輕偏見 |
| 標題 | 場地 | 年 | 代碼如果有的話 | 評論 |
|---|---|---|---|---|
| 擴散模型擊敗圖像合成上的gan | 神經 | 2021 | github | 圖像生成的擴散模型 |
| 擴散模型擊敗圖像合成上的gan | 神經 | 2021 | github | 圖像生成的擴散模型 |
| 剝離擴散概率模型 | 神經 | 2020 | github | 圖像生成的擴散模型 |
| SUS-X:視覺模型的僅訓練的僅訓練名稱轉移 | ICCV | 2023 | github | 圖像生成的擴散模型 |
| 在擴散模型中調查及時工程 | 神經研討會 | 2022 | --- | 語義提示設計 |
| Diffumask:使用像素級註釋合成圖像,使用擴散模型進行語義分割 | IEEE/CVF | 2023 | github | 迅速多樣化;提示合成數據生成 |
| 來自生成模型的合成數據是否準備好用於圖像識別? | ICLR | 2023 | github | 迅速多樣化 |
| 圖像值得一個詞:使用文本反演個性化文本到圖像生成 | ICLR | 2023 | github | 通過提示對合成結果的複雜控制 |
| Dreambooth:主題驅動一代的微調文本到圖像擴散模型 | CVPR | 2023 | github | 通過提示對合成結果的複雜控制 |
| 文本對圖像擴散的多概念自定義 | CVPR | 2023 | github | 通過提示對合成結果的複雜控制 |
| 迅速使用交叉注意控制的圖像編輯 | ICLR | 2023 | --- | 通過提示對合成結果的複雜控制 |
| 構成文本對圖像合成的無訓練結構擴散指南 | ICLR | 2023 | github | 可控制的文本對圖像生成 |
| 可控圖像生成的擴散自我構想 | 神經 | 2023 | 頁 | 可控制的文本對圖像生成 |
| 圖像:基於文本的真實圖像編輯,具有擴散模型 | CVPR | 2023 | github | 可控制的文本對圖像生成 |
| 將條件控制添加到文本到圖像擴散模型 | IEEE/CVF | 2023 | github | 可控制的文本對圖像生成 |
| 迅速使用交叉注意控制的圖像編輯 | ICLR | 2023 | github | 通過提示對合成結果的複雜控制 |
| 假想網絡:學習對象探測器沒有真實圖像和註釋 | ICLR | 2023 | github | 提示合成數據生成 |
| 來自生成模型的合成數據是否準備好用於圖像識別? | ICLR | 2023 | github | 提示合成數據生成 |
| Make-A-Video:沒有文本視頻數據的文本到視頻生成 | ICLR | 2023 | 頁 | 提示文本到視頻生成 |
| 影像視頻:帶擴散模型的高清視頻生成 | arxiv | 2022 | 頁 | 提示文本到視頻生成 |
| FATEZERO:基於文本的視頻編輯的零拍攝的關注 | ICCV | 2023 | github | 提示文本到視頻生成 |
| Tune-a-video:文本到視頻生成的圖像擴散模型的一聲調整 | ICCV | 2023 | github | 提示文本到視頻生成 |
| 差異:渲染引導的3D輻射場擴散 | CVPR | 2023 | 頁 | 提示文本到3D代 |
| DreamFusion:使用2D擴散的文本到3D | ICLR值得注意的前5% | 2023 | 頁 | 提示文本到3D代 |
| dream3d:零擊文本到3D合成3D形狀的先驗和文本形象擴散模型 | CVPR | 2023 | 頁 | 提示文本到3D代 |
| MotionDiffuse:通過擴散模型的文本驅動人類運動產生 | IEEE | 2024 | 頁 | 提示文本到動作生成 |
| 火焰:基於語言的自由形式的運動綜合和編輯 | AAAI | 2023 | github | 提示文本到動作生成 |
| MDM:人類運動擴散模型 | ICLR | 2023 | github | 提示文本到動作生成 |
| 使用擴散模型從純文本故事出發的零發鏡頭 | arxiv | 2023 | --- | 提示複雜的任務 |
| 通過雙文本圖像提示,多模式的程序計劃 | ICLR | 2024 | github | 提示複雜的任務 |
| 及時竊取針對文本到圖像生成模型的攻擊 | USENIX安全研討會 | 2023 | --- | 提示負責人AI |
| 對文本到圖像生成模型的會員推斷攻擊 | ICLR | 2023 | --- | 對文本圖模型的會員攻擊 |
| 擴散模型是否容易受到會員推理攻擊? | ICML | 2023 | github | 對文本圖模型的會員攻擊 |
| 從擴散模型中可再現的訓練圖像 | arxiv | 2023 | github | 對文本圖模型的會員攻擊 |
| 公平擴散:指導公平的文本到圖像生成模型 | arxiv | 2023 | github | 考慮公平的文本到圖像模型的提示 |
| 通過文本到圖像一代鏡頭的社會偏見 | AAAI/ACM | 2023 | --- | 考慮偏見的文本到圖像模型的提示 |
| T2IAT:在文本到圖像生成中測量價和刻板印象的偏見 | ACL | 2023 | --- | 考慮偏見的文本到圖像模型的提示 |
| 穩定偏見:分析擴散模型中的社會表示 | 神經 | 2023 | --- | 考慮偏見的文本到圖像模型的提示 |
| 一項針對穩定擴散的無查詢對抗攻擊的試點研究 | CVPR | 2023 | --- | 文本對圖像模型的對抗性魯棒性 |
| 無法察覺和可轉移的對抗性攻擊的擴散模型 | ICLR | 2024 | github | 文本對圖像模型的對抗性魯棒性 |
| 對抗純化的擴散模型 | ICML | 2022 | github | 文本對圖像模型的對抗性魯棒性 |
| 將藝術家搖滾:將後門注入文本編碼器中的文本對圖像綜合 | ICCV | 2023 | --- | 對文本對圖像模型的後門攻擊 |
| 文本到圖像擴散模型可以通過多模式數據中毒很容易地歸還 | ACM mm | 2023 | --- | 對文本對圖像模型的後門攻擊 |
| 個性化作為對文本對圖像擴散模型的幾次後門攻擊的快捷方式 | AAAI | 2024 | --- | 對文本對圖像模型的後門攻擊 |
請聯繫我們([email protected],[email protected])


