Awesome Prompting on Vision Language Model
1.0.0
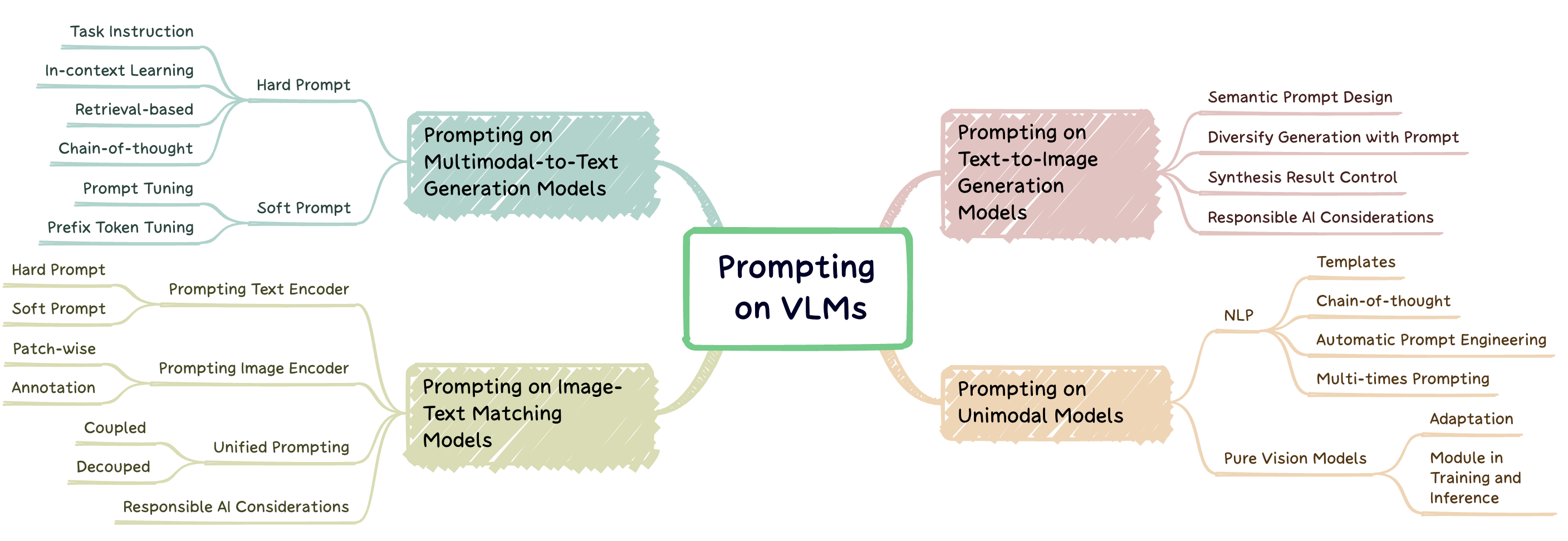
Обратная техника-это метод, который включает в себя расширение большой предварительно обученной модели с подсказками для конкретных задач, известных как подсказки, для адаптации модели к новым задачам. Это репошет, направленная на то, чтобы предоставить всесторонний обзор передовых исследований в области быстрого разработки на трех типах моделей на языке зрения (VLMS): модели с мультимодальным текстом ( например , Flamingo), модели сопоставления текста изображений ( например , CLIP) и модели генерации текста к изображению ( например , стабильная диффузия) (рис. 1).
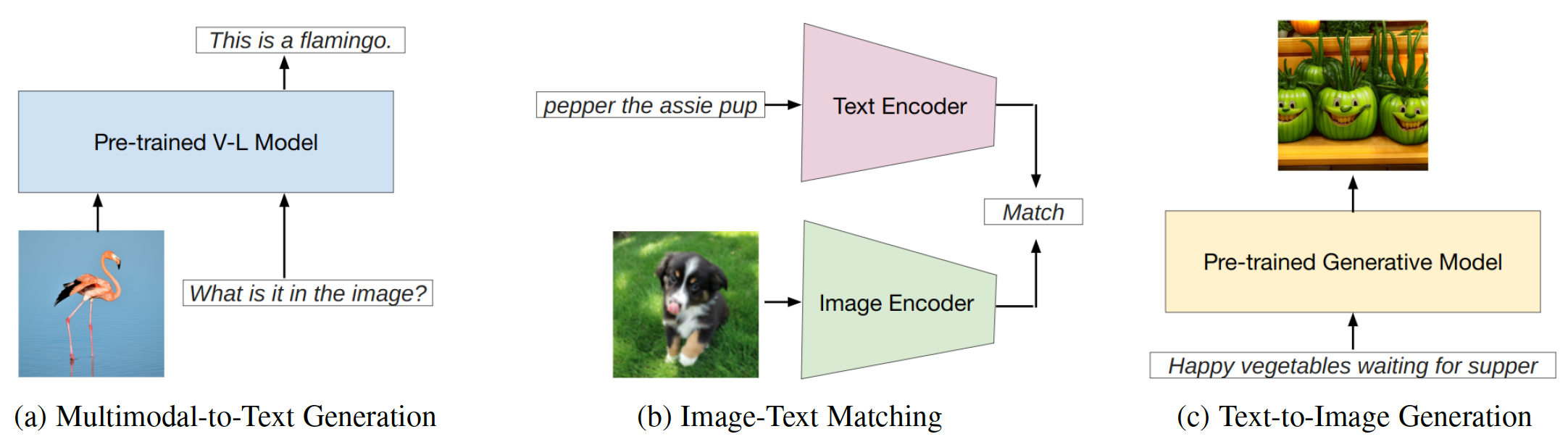
Рис. 1: Эта работа фокусируется на трех основных типах моделей на языке зрения.
В этом репо перечислены соответствующие документы, обобщенные в нашем опросе:
Систематический обзор быстрого разработки моделей фонда на языке зрения. Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, Philip Torr . Препринт 2023. [PDF]
Если вы найдете нашу газету и репо полезным для вашего исследования, пожалуйста, укажите следующую статью:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}Подсказка модели в мультимодальном генерации в тексте
Подсказка модели в сопоставлении текста изображения
Подсказка модели в генерации текста до изображения
Существует два основных типа подходов модуля слияния, основанные на интеграции визуальных и текстовых модальностей: Encoder-Decoder как мультимодальный модуль слияния и только для декодера как мультимодальный модуль слияния . Методы подсказки можно разделить на две основные категории (рис. 2) на основе читаемости шаблонов: жесткая подсказка и мягкая подсказка . Трудное быстрое приглашение охватывает четыре подкатегории: инструкция по заданиям, встроенное обучение, подсказка на основе поиска и подсказка для цепочки мыслей . Мягкие подсказки классифицируются на две стратегии: настройка быстрого настройки и настройки токенов префикса , основанные на том, добавляют ли они внутренне новые токены в архитектуру модели или просто добавляют их к входу. Это исследование в основном концентрируется на быстрых методах, которые избегают изменения базовой модели.
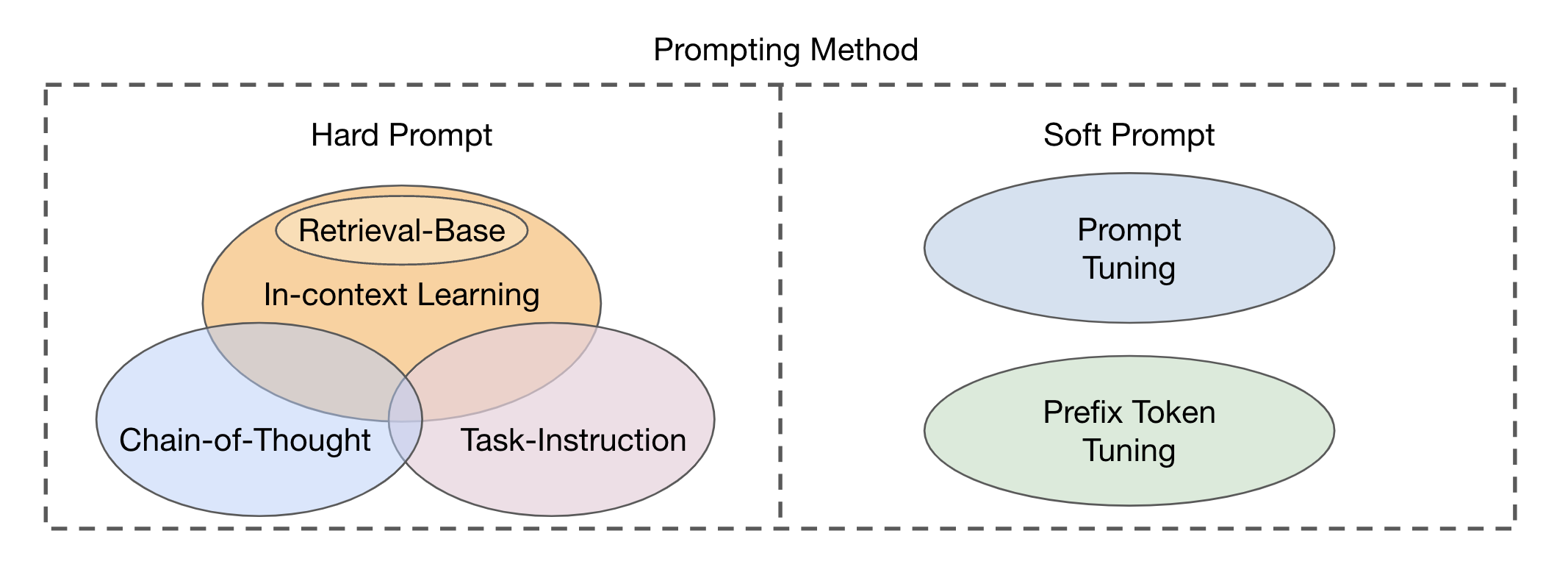
Рис. 2: Классификация методов подсказки.
| Заголовок | Место проведения | Год | Код, если доступен | Комментарий |
|---|---|---|---|---|
| Объединение задач зрения и языка с помощью генерации текста | ICML | 2021 | GitHub | Энкодер-декодер Fusion; Текстовые префиксы как приглашение |
| SIMVLM: Простая модель визуального языка предварительно подготовлена со слабым надзором | ICLR | 2022 | GitHub | Энкодер-декодер Fusion; Текстовые префиксы как приглашение |
| OFA: объединение архитектур, задач и модальностей через простую структуру обучения последовательности к последовательности | ICML | 2022 | GitHub | Энкодер-декодер Fusion; Текстовые префиксы как приглашение |
| Пали: совместно масштабированная многоязычная модель языкового изображения | ICLR | 2023 | --- | Энкодер-декодер Fusion; Инструкция |
| Мультимодальное обучение с несколькими выстрелами с моделями замороженного языка | Невра | 2021 | Страница | Fusion только для декодера; Условная настройка префикса изображения |
| Flamingo: модель визуального языка для нескольких выстрелов | Невра | 2022 | GitHub | Fusion только для декодера; Текстовые подсказки; |
| Магма-мультимодальное увеличение генеративных моделей с помощью адаптерных. | Emnlp | 2022 | GitHub | Fusion только для декодера; Условная настройка префикса изображения |
| BLIP-2: предварительное обучение на основе обработки языка с замороженными кодерами изображения и большими языковыми моделями | ICML | 2023 | GitHub | Fusion только для декодера; Условная настройка префикса изображения |
| Языковые модели - это неконтролируемые многозадачные ученики | Блог Openai | 2019 | GitHub | Задача инструкций |
| ТЕРТИКА: могут ли языковые модели понять инструкции? | arxiv | 2020 | --- | Задача инструкций |
| Языковые модели-несколько учеников | Невра | 2020 | --- | Внутреннее обучение |
| Обучение получению подсказок для обучения в контексте | NAACL-HLT | 2022 | GitHub | Поиск подсказки |
| Объединенная демонстрация ретривера для обучения в контексте | Acl | 2023 | GitHub | Поиск подсказки |
| Композиционные примеры для обучения в контексте | ICML | 2023 | GitHub | Поиск подсказки |
| Повышение в цепочке мышления вызывает рассуждения в крупных языковых моделях | Невра | 2022 | --- | Побуждение к цепочке мыслей |
| Автоматическая цепочка мыслительной подсказки в моделях крупных языков | ICLR | 2023 | GitHub | Побуждение к цепочке мыслей |
| Мощность масштабирования для настройки с помощью параметров | Emnlp | 2021 | --- | Быстрое настройка |
| Изучение того, как спрашивать: запрос LMS со смесями мягких подсказок | NAACL-HLT | 2021 | GitHub | Быстрое настройка |
| Настройка префикса: оптимизация непрерывных подсказок для генерации | Acl | 2021 | GitHub | Префикс настройка |
| Быстрое настройка для генеративных мультимодальных моделей | Acl | 2023 | GitHub | Быстро настройка на OFA |
| Язык - это не все, что вам нужно: согласование восприятия с языковыми моделями | Невра | 2023 | GitHub | Подсказки текстовой инструкции |
| Прочностные методы адаптации на предварительно обученных моделях на языке зрения | Невра | 2024 | Страница | Надежность быстрой настройки на VLMS |
| К надежным подсказкам на моделях языка зрения | NextGenAisafety@ICLR | 2024 | --- | Надежность быстрой настройки на VLMS |
| Инструктира | Невра | 2023 | GitHub | Быстрое настройка |
| Настройка визуальной инструкции | Невра | 2023 | GitHub | |
| QWEN-VL: универсальная модель на языке зрения для понимания, локализации, чтения текста и за его пределами | arxiv | 2023 | GitHub | Быстрое настройка |
| Shikra: развязка Multimodal LLM -диалога магия | arxiv | 2023 | GitHub | |
| Minigpt-4: улучшение понимания зрения с помощью расширенных крупных языковых моделей | ICLR | 2023 | GitHub | Быстрое настройка |
В зависимости от цели подсказки, существующие методы могут быть классифицированы на три категории: побуждение к текстовому кодеру , побуждение визуального энкодера или совместно вызывая обе ветви, как показано на рис. 2. Эти подходы направлены на повышение гибкости и характеристик VLMS, конкретной для задач.
Рис. 2: Классификация методов подсказки на VLMS-совпадении изображений.
| Заголовок | Место проведения | Год | Код, если доступен | Комментарий |
|---|---|---|---|---|
| Передаваемые визуальные модели обучения от надзора естественного языка | ICML | 2021 | GitHub | Жесткие текстовые подсказки; Подсказка для классификации изображений |
| Углубляться в открытость клипа | Acl | 2023 | GitHub | Жесткий текст подсказки для понимания |
| Настройка быстрого настройки времени тестирования для обобщения с нулевым выстрелом в моделях языка зрения | Невра | 2022 | GitHub | Мягкий текст подсказки |
| Обучение моделям, обучающимся на языке зрения | IJCV | 2022 | GitHub | Мягкий текст подсказки |
| Побуждение моделей визуального языка для эффективного понимания видео | ECCV | 2022 | GitHub | Мягкий текст подсказки |
| Многозадачная настройка на настройку зрения | WACV | 2024 | GitHub | Мягкий текст подсказки |
| Условное быстрое обучение для моделей языка зрения | CVPR | 2022 | GitHub | Мягкий текст подсказки |
| Визуальная приглашенная настройка | ECCV | 2022 | GitHub | Визуальные патч-подсказки |
| Изучение визуальных подсказок для адаптации крупномасштабных моделей | arxiv | 2022 | GitHub | Визуальные патч-подсказки |
| Многозадачная настройка на настройку зрения | WACV | 2024 | GitHub | Визуальные патч-подсказки |
| Раскрыть силу визуального подсказки на уровне пикселей | Tmlr | 2024 | GitHub | Визуальные патч-подсказки |
| Мета-визуальное представление о разнообразии | CVPR | 2023 | GitHub | Визуальные патч-подсказки |
| CPT: красочная оперативная настройка для предварительно обученных моделей на языке зрения | Ai open | 2024 | GitHub | Визуальные аннотационные подсказки |
| Что Клип знает о красном круге? Визуальная приглашенная инженерия для VLMS | ICCV | 2023 | --- | Визуальные аннотационные подсказки |
| Визуальное подсказка с помощью изображения внедорожник | Невра | 2022 | GitHub | Визуальные аннотационные подсказки |
| Объединенное видение и языковое быстрое обучение | arxiv | 2023 | GitHub | Связанные унифицированные подсказки |
| Многозадачная настройка на настройку зрения | WACV | 2024 | GitHub | Разрешенные единые подсказки |
| Клен: многомодальное быстрое обучение | CVPR | 2023 | GitHub | Разрешенные единые подсказки |
| Понимание нулевой состязательной надежности для крупномасштабных моделей | ICLR | 2023 | Код | Состязательная надежность быстрого |
| Визуальное подсказка для состязательной надежности | Icassp | 2023 | GitHub | Состязательная надежность быстрого |
| Выровнять перед предохранителем: видение и языковое представление обучение с дистилляцией импульса | Невра | 2021 | GitHub | Модель сопоставления текста изображений |
| Неконтролируемое быстрое обучение для моделей на языке зрения | arxiv | 2022 | GitHub | Непертешные обучаемые подсказки |
| Настройка быстрого настройки времени тестирования для обобщения с нулевым выстрелом в моделях языка зрения | Невра | 2022 | GitHub | Учебная подсказка |
| Быстрое предварительное обучение с более чем двадцатью тысяч классов для визуального распознавания открытого вокабуляции | Невра | 2023 | GitHub | Быстрое предварительное обучение |
| Обратное обучение под руководством последовательности для моделей языка зрений | ICLR | 2024 | --- | Разрешенные единые подсказки |
| Улучшение адаптивности и обобщения эффективного обучения переноса для моделей языка зрения | ACL обр | 2024 | --- | Учебная подсказка |
| Заголовок | Место проведения | Год | Код, если доступен | Комментарий |
|---|---|---|---|---|
| LMPT: оперативная настройка с потерей встраивания для встраиваемого класса для длиннохвостого многоустроенного визуального распознавания | Альвр | 2024 | GitHub | Подсказки для длиннохвостого многопользовательской классификации изображений |
| Настройка быстрого настройки времени тестирования для обобщения с нулевым выстрелом в моделях языка зрения | Невра | 2022 | GitHub | Учебная подсказка; Подсказки для классификации изображений |
| LPT: настройка с длинной хвостами для классификации изображений | ICLR | 2023 | GitHub | Подсказки для классификации изображений с длинной хвостами |
| Тексты как изображения в быстром настройке для распознавания изображений с несколькими маршрутами | CVPR | 2023 | GitHub | Подсказки для классификации и обнаружения изображений с несколькими маршрутами |
| DualCoop: быстрая адаптация к многопользуящему распознаванию с ограниченными аннотациями | Невра | 2022 | GitHub | Подсказки для классификации и распознавания с несколькими маркировками |
| Настройка визуальной подсказки для нескольких выстрелов классификации текста | Iccl | 2022 | --- | Визуальные подсказки для классификации текста |
| Обнаружение объектов с открытыми вокабуляциями через видение и языковые знания дистилляция | ICLR | 2021 | GitHub | Подсказки для обнаружения объектов |
| Обучение подсказке для обнаружения объектов с открытыми вокабуляциями с моделью на языке зрения | CVPR | 2022 | GitHub | Подсказки для обнаружения объектов |
| Rampledet: к обнаружению открытого вокабулярия с использованием раскрытых изображений | ECCV | 2022 | GitHub | Подсказки для обнаружения объектов |
| Оптимизация непрерывных подсказок для обнаружения визуальных отношений путем настройки аффикса | IEEE Access | 2022 | --- | Мягкие подсказки для обнаружения визуальных отношений |
| На пути к генерации графов сцены с открытым вокабуляцией с быстрого на основе искаемого процесса. | ECCV | 2022 | --- | Мягкие подсказки для обнаружения визуальных отношений |
| Композиционная приглашение настройки с подсказками движения для обнаружения видеороликов с открытым вокабуляцией | ICLR | 2023 | GitHub | Подсказки о отношениях для обнаружения взаимосвязи с открытыми вокабуляциями |
| Денсисекция: языковой поддержание плотное прогнозирование с подсказкой для контекста | CVPR | 2022 | GitHub | Подготовленные в классе текстовые подсказки для семантической сегментации |
| Сегмент что угодно | ICCV | 2023 | GitHub | Оперативные запросы для семантической сегментации |
| Адаптация домена посредством быстрого обучения | IEEE | 2023 | GitHub | Специфичные для домена текстовые подсказки для адаптации домена |
| Настройка визуальной подсказки для адаптации домена времени тестирования | arxiv | 2022 | --- | Подсказки для адаптации доменов |
| Научиться приглашать для постоянного обучения | CVPR | 2022 | GitHub | Побуждения для постоянного обучения |
| DualPrompt: дополнительное подсказка для непрерывного непрерывного обучения без репетиций | ECCV | 2022 | GitHub | Побуждения для постоянного обучения |
| Быстрое видение трансформатора для обобщения доменов | arxiv | 2022 | GitHub | Подсказки для обобщения доменов |
| Понимание нулевой состязательной надежности для крупномасштабных моделей | Lclr | 2022 | GitHub | Настройка визуальной подсказки под состязательной атакой |
| Визуальное подсказка для состязательной надежности | Icassp | 2023 | GitHub | Визуальное побуждение для улучшения состязательной надежности |
| Изучение универсальной уязвимости парадигмы обучения на основе быстрого обучения | Наакл | 2022 | GitHub | Визуальное подсказка уязвимости |
| Отравление и контрастное обучение с бэкдором | ICLR | 2022 | --- | Бэкдор и отравление атаки на клип |
| Badencoder: Backdoor атакует предварительно обученные кодеры в самоотверженном обучении | IEEE | 2022 | GitHub | Бэкдор Атака на клип |
| CleanClip: смягчение атак отравления данных в мультимодальном контрастном обучении | ICLR Workshop | 2023 | --- | Защита Бэкдор Атаки на клип |
| Debiasing Vision Luganal Models с помощью предвзятых подсказок | arxiv | 2023 | GitHub | Побуждения для облегчения предвзятости |
| Заголовок | Место проведения | Год | Код, если доступен | Комментарий |
|---|---|---|---|---|
| Диффузионные модели бьют Gans по синтезу изображения | Невра | 2021 | GitHub | Диффузионные модели на генерации изображений |
| Диффузионные модели бьют Gans по синтезу изображения | Невра | 2021 | GitHub | Диффузионные модели на генерации изображений |
| Обезвреживание диффузионных вероятностных моделей | Невра | 2020 | GitHub | Диффузионные модели на генерации изображений |
| SUS-X: Без обучения передачи моделей на языке зрений только для | ICCV | 2023 | GitHub | Диффузионные модели на генерации изображений |
| Исследование оперативной техники в моделях диффузии | Neurips Workshop | 2022 | --- | Семантический быстрый дизайн |
| Diffumask: синтезирование изображений с аннотациями на уровне пикселей для семантической сегментации с использованием диффузионных моделей | IEEE/CVF | 2023 | GitHub | Диверсифицировать поколение с помощью быстрого; Подсказки для генерации синтетических данных |
| Готовы ли синтетические данные из генеративных моделей для распознавания изображений? | ICLR | 2023 | GitHub | Диверсифицировать поколение с помощью |
| Изображение стоит одного слова: персонализация генерации текста до изображения с использованием текстовой инверсии | ICLR | 2023 | GitHub | Сложный контроль результатов синтеза с помощью подсказок |
| Dreambooth: тонкая настройка модели диффузии текста до изображения для генерации, управляемой субъектом | CVPR | 2023 | GitHub | Сложный контроль результатов синтеза с помощью подсказок |
| Настройка мульти-концепции диффузии текста до изображения | CVPR | 2023 | GitHub | Сложный контроль результатов синтеза с помощью подсказок |
| Редактирование изображений с приглашенным на предложение с помощью управления вниманием к кросс-обращению | ICLR | 2023 | --- | Сложный контроль результатов синтеза с помощью подсказок |
| Структурированное диффузионное руководство без обучения для композиционного синтеза текста до изображения | ICLR | 2023 | GitHub | Контролируемое генерацию текста к изображению |
| Диффузионное самоуверенность для управляемого генерации изображений | Невра | 2023 | Страница | Контролируемое генерацию текста к изображению |
| Imagic: текстовое редактирование реальных изображений с помощью диффузионных моделей | CVPR | 2023 | GitHub | Контролируемое генерацию текста к изображению |
| Добавление условного управления в диффузионные модели текста до изображения | IEEE/CVF | 2023 | GitHub | Контролируемое генерацию текста к изображению |
| Редактирование изображений с приглашенным на предложение с помощью управления вниманием к кросс-обращению | ICLR | 2023 | GitHub | Сложный контроль результатов синтеза с помощью подсказок |
| IngineNetet: детекторы объектов обучения без реальных изображений и аннотаций | ICLR | 2023 | GitHub | Подсказки для генерации синтетических данных |
| Готовы ли синтетические данные из генеративных моделей для распознавания изображений? | ICLR | 2023 | GitHub | Подсказки для генерации синтетических данных |
| Make-a-video: генерация текста в Video без текстовых данных | ICLR | 2023 | Страница | Подсказки для генерации текста в Video |
| Imagen Video: генерация видео с высокой четкой с диффузионными моделями | arxiv | 2022 | Страница | Подсказки для генерации текста в Video |
| Fatezero: слияние внимания для редактирования видео на основе с нулевым выстрелом | ICCV | 2023 | GitHub | Подсказки для генерации текста в Video |
| Tune-a-Video: одноразовый настройка диффузионных моделей изображения для генерации текста-Video | ICCV | 2023 | GitHub | Подсказки для генерации текста в Video |
| DIFFRF: Диффузия поля с линией Rendering, управляемая | CVPR | 2023 | Страница | Подсказки для поколения текста в 3D |
| DreamFusion: текст к 3D с использованием 2D диффузии | ICLR Примечательные лучшие 5% | 2023 | Страница | Подсказки для поколения текста в 3D |
| Dream3d: Синтез с нулевым выстрелом в 3D с использованием трехмерной формы предыдущей и диффузионной диффузии текста до текста. | CVPR | 2023 | Страница | Подсказки для поколения текста в 3D |
| MotionDiffuse: Текстовая генерация движения человека с диффузионной моделью | IEEE | 2024 | Страница | Подсказки для генерации текста в направление |
| Пламя: свободная формирование языкового синтеза движения и редактирования | Ааай | 2023 | GitHub | Подсказки для генерации текста в направление |
| MDM: модель диффузии движения человека | ICLR | 2023 | GitHub | Подсказки для генерации текста в направление |
| Образование последовательных рассказов с нулевым выстрелом из простых текстовых историй с использованием диффузионных моделей | arxiv | 2023 | --- | Подсказки для сложных задач |
| Мультимодальное процедурное планирование с помощью двойного текстового изображения | ICLR | 2024 | GitHub | Подсказки для сложных задач |
| Оперативная кража атак против моделей генерации текста до изображения | Симпозиум безопасности USENIX | 2023 | --- | Подсказки для ответственного ИИ |
| Атаки по выводу членства против моделей генерации текста до изображения | ICLR | 2023 | --- | Членские атаки против моделей текста до изображения |
| Являются ли диффузионные модели уязвимы для атак на вывод членства? | ICML | 2023 | GitHub | Членские атаки против моделей текста до изображения |
| Воспроизводимая извлечение обучающих изображений из диффузионных моделей | arxiv | 2023 | GitHub | Членские атаки против моделей текста до изображения |
| Справедливая диффузия: инструктирование моделей генерации текста к изображению на справедливость | arxiv | 2023 | GitHub | Подсказки на модели текста до изображения, учитывая справедливость |
| Социальные предубеждения через объектив генерации текста до изображения | AAAI/ACM | 2023 | --- | Подсказки на модели текста до изображения с учетом предвзятости |
| T2iat: измерение валентности и стереотипных смещений в генерации текста до изображения | Acl | 2023 | --- | Подсказки на модели текста до изображения с учетом предвзятости |
| Стабильное предвзятость: анализ общественных представлений в диффузионных моделях | Невра | 2023 | --- | Подсказки на модели текста до изображения с учетом предвзятости |
| Пилотное исследование беспрепятственной атаки без запросов против стабильной диффузии | CVPR | 2023 | --- | Совместная надежность моделей текста до изображения |
| Диффузионные модели для незаметной и переносимой состязательной атаки | ICLR | 2024 | GitHub | Совместная надежность моделей текста до изображения |
| Диффузионные модели для очистки состязания | ICML | 2022 | GitHub | Совместная надежность моделей текста до изображения |
| Rickrolling The Artist: инъекция Backdoors в текстовые кодеры для синтеза текста к изображению | ICCV | 2023 | --- | Бэкдор атака на модели текста до изображения |
| Модели диффузии текста до изображения могут быть легко перегружены с помощью мультимодального отравления данных | ACM MM | 2023 | --- | Бэкдор атака на модели текста до изображения |
| Персонализация как ярлыка для нескольких выстрелов атаки с диффузией текста до изображения | Ааай | 2024 | --- | Бэкдор атака на модели текста до изображения |
Пожалуйста, свяжитесь с нами ([email protected], [email protected]), если


