Awesome Prompting on Vision Language Model
1.0.0
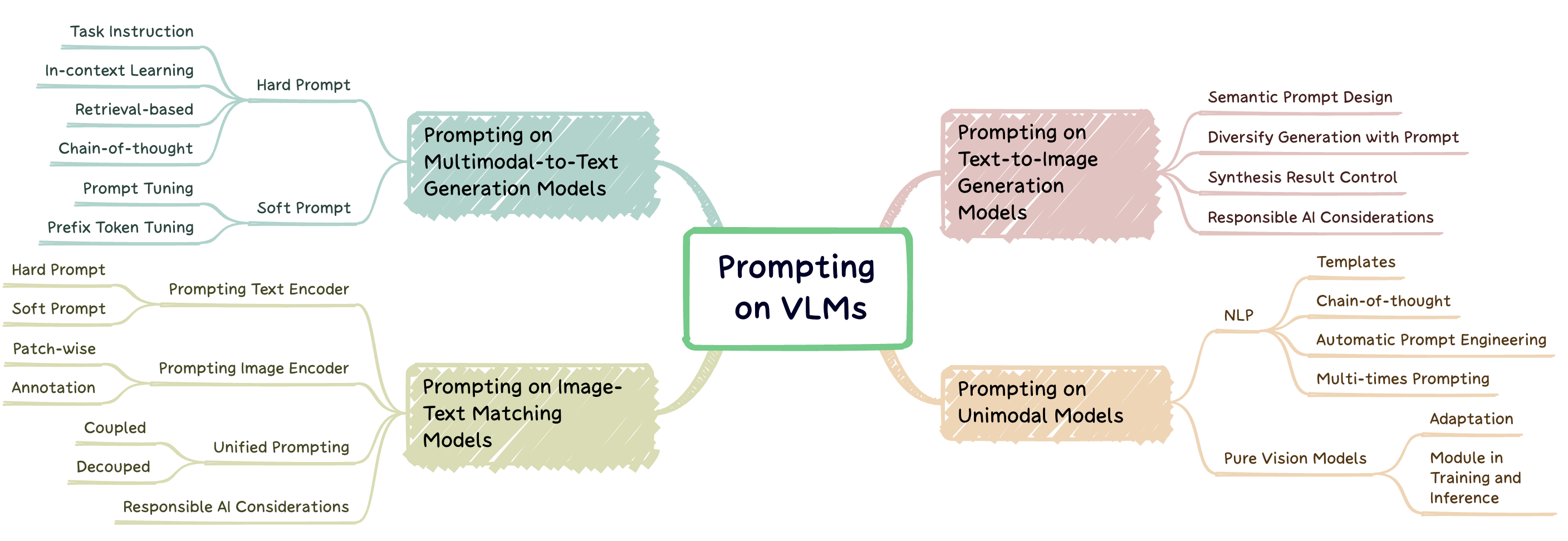
La ingeniería rápida es una técnica que implica aumentar un gran modelo previamente capacitado con sugerencias específicas de tareas, conocidas como indicaciones, para adaptar el modelo a nuevas tareas. Este repositorio tiene como objetivo proporcionar una encuesta integral de la investigación de vanguardia en ingeniería rápida en tres tipos de modelos en idioma de visión (VLMS): modelos de generación multimodal a texto ( p. Ej ., Flamingo), modelos de coincidencia de texto de imagen ( por ejemplo , clip) y modelos de generación de texto a imagen ( EG , difusión estable) (fig. 1).
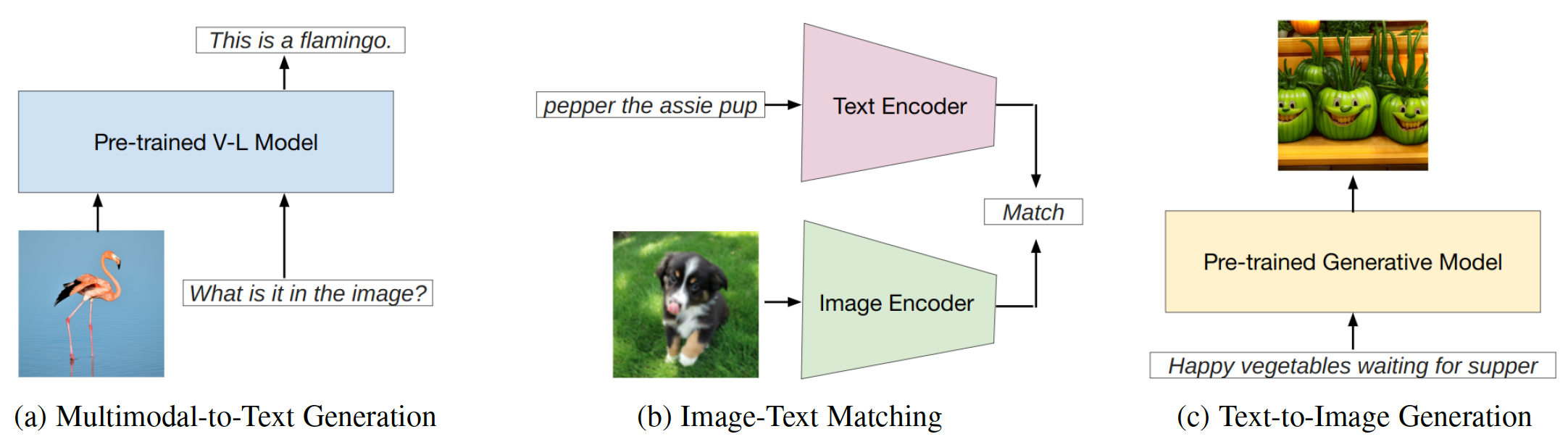
Fig. 1: Este trabajo se centra en tres tipos principales de modelos en idioma de visión.
Este repositorio enumera los documentos relevantes resumidos en nuestra encuesta:
Una encuesta sistemática de ingeniería rápida en modelos de base en el idioma de visión. Jindong GU, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, Philip Torr . Preimpresión 2023. [PDF]
Si encuentra útil nuestro documento y repose para su investigación, cite el siguiente documento:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}Modelo de solicitud en generación multimodal a texto
Modelo de solicitud en la coincidencia de texto de imagen
Involucrar el modelo en la generación de texto a imagen
Existen dos tipos principales de enfoques de módulos de fusión basados en la integración de las modalidades visuales y textuales: codificador del codificador como un módulo de fusión multimodal y solo un decodificador como un módulo de fusión multimodal . Los métodos de solicitación se pueden dividir en dos categorías principales (Fig. 2) en función de la legibilidad de las plantillas: aviso dura y suave . El aviso difícil abarca cuatro subcategorías: instrucción de tareas, aprendizaje en contexto, impulso basado en la recuperación y la impulso de cadena de pensamiento . Las indicaciones suaves se clasifican en dos estrategias: ajuste indicado y ajuste de token de prefijo , basado en si agregan internamente nuevos tokens a la arquitectura del modelo o simplemente las agregan a la entrada. Este estudio se concentra principalmente en métodos rápidos que evitan alterar el modelo base.
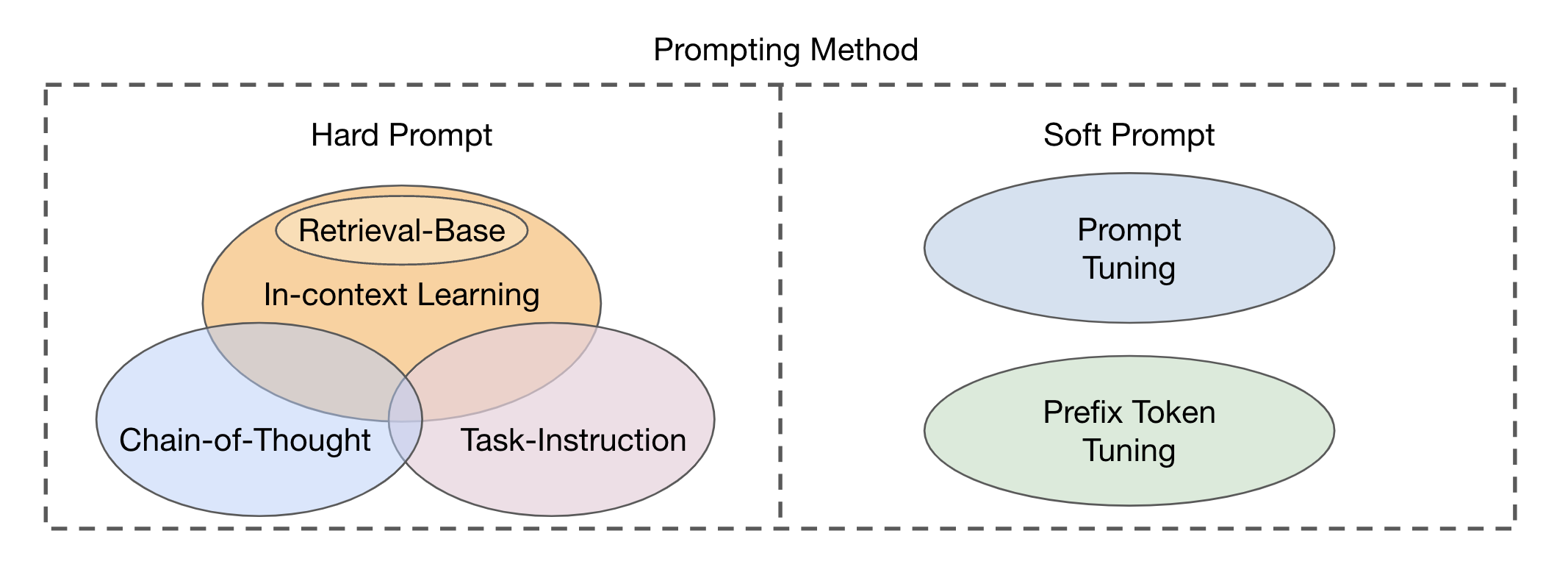
Fig. 2: Clasificación de métodos de solicitud.
| Título | Evento | Año | Código si está disponible | Comentario |
|---|---|---|---|---|
| Unificar tareas de visión y lenguaje a través de la generación de texto | ICML | 2021 | Github | Fusión de codificador codificador; Prefijos de texto como aviso |
| SIMVLM: modelo de lenguaje visual simple previamente con supervisión débil | ICLR | 2022 | Github | Fusión de codificador codificador; Prefijos de texto como aviso |
| OFA: Arquitecturas, tareas y modalidades unificadoras a través de un marco de aprendizaje de secuencia a secuencia simple | ICML | 2022 | Github | Fusión de codificador codificador; Prefijos de texto como aviso |
| Pali: un modelo de imagen de lenguaje multilingüe a escala conjunta | ICLR | 2023 | --- | Fusión de codificador codificador; Instrucción Instrucción |
| Aprendizaje multimodal de pocos disparos con modelos de idiomas congelados | Neuros | 2021 | Página | Fusión solo de decodificador; Ajuste de prefijo condicional de imagen |
| Flamingo: un modelo de lenguaje visual para el aprendizaje de pocos disparos | Neuros | 2022 | Github | Fusión solo de decodificador; Indica el texto; |
| Magma-Aumento multimodal de modelos generativos a través de Finetuning basado en adaptadores | EMNLP | 2022 | Github | Fusión solo de decodificador; Ajuste de prefijo condicional de imagen |
| BLIP-2: Bootstrapping Language-Image Pretringing con codificadores de imágenes congeladas y modelos de idiomas grandes | ICML | 2023 | Github | Fusión solo de decodificador; Ajuste de prefijo condicional de imagen |
| Los modelos de idiomas son alumnos multitarea no supervisados | Blog Operai | 2019 | Github | Instrucción de la tarea Instrucción |
| La prueba de Turking: ¿Pueden los modelos de idiomas comprender las instrucciones? | arxiv | 2020 | --- | Instrucción de la tarea Instrucción |
| Los modelos de idiomas son alumnos de pocos disparos | Neuros | 2020 | --- | Aprendizaje en contexto |
| Aprender a recuperar indicaciones para el aprendizaje en contexto | Naacl-hlt | 2022 | Github | Indicación basada en la recuperación |
| Retriever de demostración unificada para el aprendizaje en contexto | LCA | 2023 | Github | Indicación basada en la recuperación |
| Ejemplos compositivos para el aprendizaje en contexto | ICML | 2023 | Github | Indicación basada en la recuperación |
| La provisión de la cadena de pensamiento provoca el razonamiento en modelos de idiomas grandes | Neuros | 2022 | --- | Indicador de la cadena de pensamiento |
| Cadena de pensamiento automático de la cadena de pensamiento en modelos de idiomas grandes | ICLR | 2023 | Github | Indicador de la cadena de pensamiento |
| El poder de la escala para el ajuste de inmediato de los parámetros eficientes | EMNLP | 2021 | --- | Ajuste rápido |
| Aprender a preguntar: consulta LMS con mezclas de indicaciones suaves | Naacl-hlt | 2021 | Github | Ajuste rápido |
| Ajuste de prefijo: optimización de indicaciones continuas para la generación | LCA | 2021 | Github | Ajuste de prefijo |
| Ajuste rápido para modelos generativos de petróleo multimodal | LCA | 2023 | Github | ANTINGUNO PROBLE en OFA |
| El lenguaje no es todo lo que necesita: alinear la percepción con los modelos de idiomas | Neuros | 2023 | Github | Indicaciones de instrucción textual |
| Benchmarking Robusticidad de los métodos de adaptación en modelos de lenguaje de visión previamente capacitado | Neuros | 2024 | Página | Robustez de la rápida sintonización en VLMS |
| Hacia las indicaciones robustas sobre los modelos en idioma de la visión | Nextgenaisafety@iclr | 2024 | --- | Robustez de la rápida sintonización en VLMS |
| InstructBlip: hacia los modelos en idioma de visión de uso general con ajuste de instrucciones | Neuros | 2023 | Github | Ajuste rápido |
| Ajuste de instrucciones visuales | Neuros | 2023 | Github | |
| Qwen-VL: un modelo versátil en idioma de visión para la comprensión, localización, lectura de texto y más allá | arxiv | 2023 | Github | Ajuste rápido |
| Shikra: desatar magia de diálogo referencial de LLM Multimodal LLM | arxiv | 2023 | Github | |
| Minigpt-4: Mejora de la comprensión del idioma de la visión con modelos avanzados de idiomas grandes | ICLR | 2023 | Github | Ajuste rápido |
Dependiendo del objetivo de la solicitud, los métodos existentes se pueden clasificar en tres categorías: provocar al codificador de texto , provocar al codificador visual o provocar conjuntamente ambas ramas como se muestra en la figura 2. Estos enfoques apuntan a mejorar la flexibilidad y el rendimiento de la tarea de VLM.
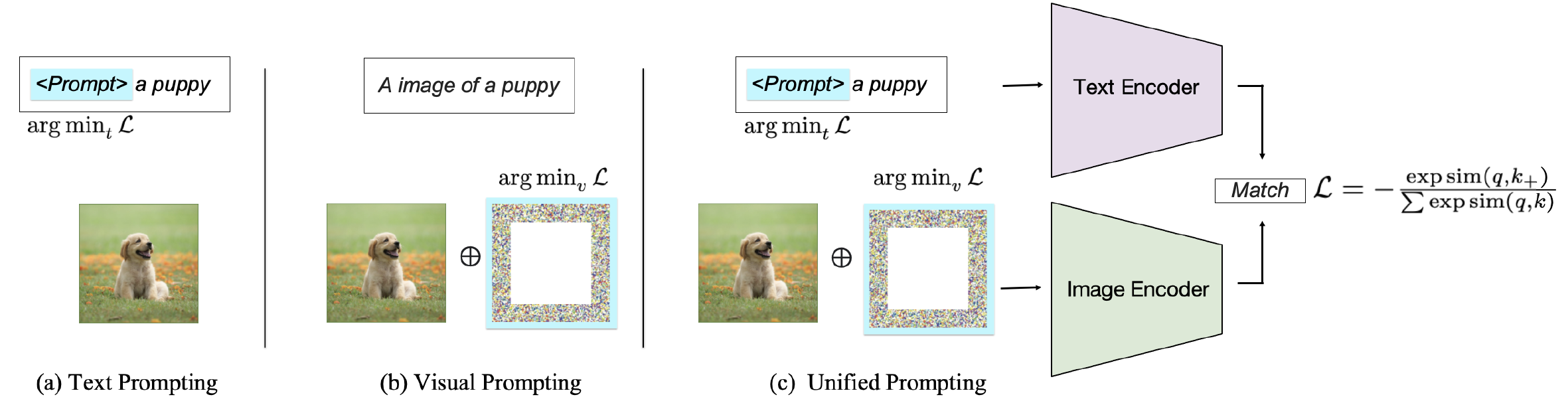
Fig. 2: Clasificación de métodos de solicitud en VLMS de coincidencia de texto de imagen.
| Título | Evento | Año | Código si está disponible | Comentario |
|---|---|---|---|---|
| Aprender modelos visuales transferibles a partir de supervisión del lenguaje natural | ICML | 2021 | Github | Información de texto duro; Solicitud para la clasificación de imágenes |
| Profundizando en la apertura del clip | LCA | 2023 | Github | Indica de texto duro para la comprensión |
| Tiempo de prueba ANTINGUNO PARA GENERALIZACIÓN DE LA VISIÓN EN MODELOS DE VISIÓN | Neuros | 2022 | Github | Información de texto suave |
| Aprender a solicitar modelos en idioma de visión | Ijcv | 2022 | Github | Información de texto suave |
| Involucrar modelos de idioma visual para una comprensión eficiente de video | ECCV | 2022 | Github | Información de texto suave |
| Aunging de la visión de la visión múltiple | WACV | 2024 | Github | Información de texto suave |
| Aprendizaje rápido condicional para modelos en idioma de visión | CVPR | 2022 | Github | Información de texto suave |
| Ajuste de inmediato visual | ECCV | 2022 | Github | Indicaciones visuales en cuanto a parche |
| Explorando indicaciones visuales para adaptar modelos a gran escala | arxiv | 2022 | Github | Indicaciones visuales en cuanto a parche |
| Aunging de la visión de la visión múltiple | WACV | 2024 | Github | Indicaciones visuales en cuanto a parche |
| Latar el poder de la solicitud visual a nivel de píxeles | Tmlr | 2024 | Github | Indicaciones visuales en cuanto a parche |
| Meta visual consciente de la diversidad | CVPR | 2023 | Github | Indicaciones visuales en cuanto a parche |
| CPT: Colorido ANTINGUNO ANTERIOR para los modelos de visión previamente capacitados | Ai abierto | 2024 | Github | Indicaciones de anotación visual |
| ¿Qué sabe Clip sobre un círculo rojo? Ingeniería visual rápida para VLMS | ICCV | 2023 | --- | Indicaciones de anotación visual |
| Información visual a través de la entrada de imágenes | Neuros | 2022 | Github | Indicaciones de anotación visual |
| Visión unificada y aprendizaje rápido del lenguaje | arxiv | 2023 | Github | Indicación unificada acoplada |
| Aunging de la visión de la visión múltiple | WACV | 2024 | Github | Indemnización unificada desacoplada |
| Maple: aprendizaje rápido multimodal | CVPR | 2023 | Github | Indemnización unificada desacoplada |
| Comprensión de la robustez adversa a cero para modelos a gran escala | ICLR | 2023 | Código | Robustez adversa de la pronta |
| Solicitante visual para la robustez adversa | ICASSP | 2023 | Github | Robustez adversa de la pronta |
| Alinearse antes del fusible: aprendizaje de la visión y la representación del lenguaje con destilación de impulso | Neuros | 2021 | Github | Modelo de coincidencia de texto de imagen |
| Aprendizaje rápido no supervisado para modelos en idioma de visión | arxiv | 2022 | Github | Indicadores de aprendizaje no merecidos |
| Tiempo de prueba ANTINGUNO PARA GENERALIZACIÓN DE LA VISIÓN EN MODELOS DE VISIÓN | Neuros | 2022 | Github | Aviso de aprendizaje |
| Precurimiento previo con más de veinte mil clases para el reconocimiento visual de Vocabulario Abierto | Neuros | 2023 | Github | Precurimiento rápido |
| Aprendizaje rápido guiado por consistencia para modelos en idioma de visión | ICLR | 2024 | --- | Indemnización unificada desacoplada |
| Mejora de la adaptabilidad y la generalización del aprendizaje de transferencia eficiente para los modelos en idioma de visión | ACL ARR | 2024 | --- | Aviso de aprendizaje |
| Título | Evento | Año | Código si está disponible | Comentario |
|---|---|---|---|---|
| LMPT: Ajuste rápido con pérdida de incrustación específica para la clase para el reconocimiento visual multiclabel de cola larga | ALVR | 2024 | Github | Indicaciones para la clasificación de imágenes de múltiples etiquetas de cola larga |
| Tiempo de prueba ANTINGUNO PARA GENERALIZACIÓN DE LA VISIÓN EN MODELOS DE VISIÓN | Neuros | 2022 | Github | Aviso de aprendizaje; Indicaciones para la clasificación de imágenes |
| LPT: ajuste de inmediato de cola larga para la clasificación de imágenes | ICLR | 2023 | Github | Indicaciones para la clasificación de imágenes de cola larga |
| Textos como imágenes en el ajuste indicador para el reconocimiento de imágenes de múltiples etiquetas | CVPR | 2023 | Github | Indicaciones para la clasificación y detección de imágenes de múltiples etiquetas |
| DualCoop: adaptación rápida al reconocimiento de múltiples etiquetas con anotaciones limitadas | Neuros | 2022 | Github | Indicaciones para la clasificación y reconocimiento de imágenes de múltiples etiquetas |
| Ajuste visual de inmediato para la clasificación de texto de pocos disparos | ICCL | 2022 | --- | Indicaciones visuales para la clasificación de texto |
| Detección de objetos abiertos a través de la visión y la destilación del conocimiento del lenguaje | ICLR | 2021 | Github | Indicaciones para la detección de objetos |
| Aprender a solicitar la detección de objetos abiertos con el modelo con modelo de lenguaje de visión | CVPR | 2022 | Github | Indicaciones para la detección de objetos |
| Indicador: hacia la detección de vocabulario abierto utilizando imágenes no curadas | ECCV | 2022 | Github | Indicaciones para la detección de objetos |
| Optimización de indicaciones continuas para la detección de relaciones visuales mediante un ajuste de afijo | Acceso IEEE | 2022 | --- | Indicaciones suaves para la detección de relaciones visuales |
| Hacia la generación de gráficos de escena de vocabulario abierto con Finetuning basado en aviso | ECCV | 2022 | --- | Indicaciones suaves para la detección de relaciones visuales |
| Ajuste de indicación compositiva con señales de movimiento para la detección de relaciones de video de vocabulario abierto | ICLR | 2023 | Github | Información de relación para la detección de relaciones de vocabulario de video |
| Denseclip: predicción densa guiada por el lenguaje con la solicitud de contexto | CVPR | 2022 | Github | Indicaciones de texto acondicionadas en clase para la segmentación semántica |
| Segmento cualquier cosa | ICCV | 2023 | Github | Consultas rápidas para la segmentación semántica |
| Adaptación del dominio a través del aprendizaje rápido | Ieee | 2023 | Github | Indicaciones textuales específicas del dominio para la adaptación del dominio |
| Ajuste visual de inmediato para la adaptación del dominio del tiempo de prueba | arxiv | 2022 | --- | Indicaciones para la adaptación del dominio |
| Aprender a solicitar el aprendizaje continuo | CVPR | 2022 | Github | Indicaciones para el aprendizaje continuo |
| DualPrompt: indicación complementaria para el aprendizaje continuo sin ensayo | ECCV | 2022 | Github | Indicaciones para el aprendizaje continuo |
| Transformador de visión de inmediato para la generalización del dominio | arxiv | 2022 | Github | Indicaciones para la generalización del dominio |
| Comprensión de la robustez adversa a cero para modelos a gran escala | LCLR | 2022 | Github | ANIMINACIÓN VISUNAL ANTINGURA EN ATACHO ANDSARIO |
| Solicitante visual para la robustez adversa | ICASSP | 2023 | Github | Investigación visual para mejorar la robustez adversa |
| Explorando la vulnerabilidad universal del paradigma de aprendizaje rápido basado en | Naacl | 2022 | Github | Vulnerabilidad visual |
| Envenenamiento y trasero Aprendizaje contrastante | ICLR | 2022 | --- | Ataques de puerta trasera y envenenamiento en el clip |
| BadEncoder: ataques de puerta trasera a codificadores previamente capacitados en el aprendizaje auto-supervisado | Ieee | 2022 | Github | Ataque de puerta trasera en el clip |
| CleanClip: mitigando los ataques de envenenamiento de datos en el aprendizaje de contraste multimodal | Taller ICLR | 2023 | --- | Ataques de puerta trasera de defensa en el clip |
| Modelos de lenguaje de visión de debiaes a través de indicaciones sesgadas | arxiv | 2023 | Github | Indica que aliviar el sesgo |
| Título | Evento | Año | Código si está disponible | Comentario |
|---|---|---|---|---|
| Los modelos de difusión superan a Gans en la síntesis de imágenes | Neuros | 2021 | Github | Modelos de difusión en la generación de imágenes |
| Los modelos de difusión superan a Gans en la síntesis de imágenes | Neuros | 2021 | Github | Modelos de difusión en la generación de imágenes |
| Modelos probabilísticos de difusión de renovación | Neuros | 2020 | Github | Modelos de difusión en la generación de imágenes |
| SUS-X: Transferencia de solo nombre sin nombre de modelos en idioma de visión | ICCV | 2023 | Github | Modelos de difusión en la generación de imágenes |
| Investigar la ingeniería rápida en modelos de difusión | Taller Neurips | 2022 | --- | Diseño de inmediato semántico |
| Diffumask: sintetizando imágenes con anotaciones a nivel de píxel para la segmentación semántica utilizando modelos de difusión | IEEE/CVF | 2023 | Github | Diversificar la generación con indicador; Indicaciones para la generación de datos sintéticos |
| ¿Están los datos sintéticos de modelos generativos listos para el reconocimiento de imágenes? | ICLR | 2023 | Github | Diversificar la generación con el aviso |
| Una imagen vale una palabra: personalizar la generación de texto a imagen usando inversión textual | ICLR | 2023 | Github | Control complejo de los resultados de síntesis a través de indicaciones |
| DreamBooth: modelos de difusión de texto a imagen de ajuste fino para la generación impulsada por el sujeto | CVPR | 2023 | Github | Control complejo de los resultados de síntesis a través de indicaciones |
| Personalización de múltiples concepto de difusión de texto a imagen | CVPR | 2023 | Github | Control complejo de los resultados de síntesis a través de indicaciones |
| Edición de imagen de inmediato a pronunciar con control de atención cruzada | ICLR | 2023 | --- | Control complejo de los resultados de síntesis a través de indicaciones |
| Guía de difusión estructurada sin entrenamiento para la síntesis de texto a imagen compositiva | ICLR | 2023 | Github | Generación de texto a imagen controlable |
| Autoguinación de difusión para la generación de imágenes controlables | Neuros | 2023 | Página | Generación de texto a imagen controlable |
| Imagic: edición de imágenes reales basadas en texto con modelos de difusión | CVPR | 2023 | Github | Generación de texto a imagen controlable |
| Agregar control condicional a modelos de difusión de texto a imagen | IEEE/CVF | 2023 | Github | Generación de texto a imagen controlable |
| Edición de imagen de inmediato a pronunciar con control de atención cruzada | ICLR | 2023 | Github | Control complejo de los resultados de síntesis a través de indicaciones |
| Imaginarynet: aprendizaje de detectores de objetos sin imágenes y anotaciones reales | ICLR | 2023 | Github | Indicaciones para la generación de datos sintéticos |
| ¿Están los datos sintéticos de modelos generativos listos para el reconocimiento de imágenes? | ICLR | 2023 | Github | Indicaciones para la generación de datos sintéticos |
| Make-A-Video: Generación de texto a video sin datos de videos de texto | ICLR | 2023 | Página | Solicitudes para la generación de texto a video |
| Video de Imagen: generación de videos de alta definición con modelos de difusión | arxiv | 2022 | Página | Solicitudes para la generación de texto a video |
| Fatezero: Fusioning atenciones para edición de video basada en texto de disparo cero | ICCV | 2023 | Github | Solicitudes para la generación de texto a video |
| Tune-a-Video: ajuste de una sola vez de modelos de difusión de imágenes para generación de texto a video | ICCV | 2023 | Github | Solicitudes para la generación de texto a video |
| DIFRF: difusión de campo de radiancia 3D guiada por representación | CVPR | 2023 | Página | Signos para la generación de texto a 3D |
| Dreamfusion: texto a 3D usando difusión 2D | ICLR notable 5% superior | 2023 | Página | Signos para la generación de texto a 3D |
| Dream3D: Síntesis de texto a 3D de disparo cero con modelos de difusión de forma 3D anterior y texto a imagen | CVPR | 2023 | Página | Signos para la generación de texto a 3D |
| MotionDiffuse: generación de movimiento humano impulsado por texto con modelo de difusión | Ieee | 2024 | Página | Solicitudes para la generación de texto a movimiento |
| Flame: síntesis y edición de movimiento basada en el lenguaje de forma libre | AAAI | 2023 | Github | Solicitudes para la generación de texto a movimiento |
| MDM: modelo de difusión de movimiento humano | ICLR | 2023 | Github | Solicitudes para la generación de texto a movimiento |
| Generación de disparo cero de libros de cuentos coherentes de la historia de texto plano utilizando modelos de difusión | arxiv | 2023 | --- | Indicaciones para tareas complejas |
| Planificación de procedimiento multimodal a través de la solicitud de imagen de texto dual | ICLR | 2024 | Github | Indicaciones para tareas complejas |
| Attacos de robo rápido contra modelos de generación de texto a imagen | Simposio de seguridad de USENIX | 2023 | --- | Indicaciones para la IA responsable |
| Ataques de inferencia de membresía contra modelos de generación de texto a imagen | ICLR | 2023 | --- | Ataques de membresía contra modelos de texto a imagen |
| ¿Son los modelos de difusión vulnerables a los ataques de inferencia de membresía? | ICML | 2023 | Github | Ataques de membresía contra modelos de texto a imagen |
| Una extracción reproducible de imágenes de entrenamiento de modelos de difusión | arxiv | 2023 | Github | Ataques de membresía contra modelos de texto a imagen |
| Difusión justa: instruir modelos de generación de texto a imagen sobre justicia | arxiv | 2023 | Github | Informe sobre modelos de texto a imagen que consideran la justicia |
| Sesgos sociales a través de la lente de generación de texto a imagen | AAAI/ACM | 2023 | --- | Involucra sobre modelos de texto a imagen que consideran prejuicios |
| T2iat: valencia de medición y sesgos estereotipados en la generación de texto a imagen | LCA | 2023 | --- | Involucra sobre modelos de texto a imagen que consideran prejuicios |
| Sesgo estable: análisis de representaciones sociales en modelos de difusión | Neuros | 2023 | --- | Involucra sobre modelos de texto a imagen que consideran prejuicios |
| Un estudio piloto del ataque adversario sin consultas contra la difusión estable | CVPR | 2023 | --- | Robustez adversa de los modelos de texto a imagen |
| Modelos de difusión para un ataque adversario imperceptible y transferible | ICLR | 2024 | Github | Robustez adversa de los modelos de texto a imagen |
| Modelos de difusión para la purificación adversa | ICML | 2022 | Github | Robustez adversa de los modelos de texto a imagen |
| Rickrolling the Artist: inyectando las puertas traseras en codificadores de texto para la síntesis de texto a imagen | ICCV | 2023 | --- | Ataque de puerta trasera en modelos de texto a imagen |
| Los modelos de difusión de texto a imagen pueden ser fácilmente traseros mediante envenenamiento de datos multimodales | ACM MM | 2023 | --- | Ataque de puerta trasera en modelos de texto a imagen |
| Personalización como un atajo para un ataque de puerta trasera de pocos disparos contra modelos de difusión de texto a imagen | AAAI | 2024 | --- | Ataque de puerta trasera en modelos de texto a imagen |
Póngase en contacto con nosotros ([email protected], [email protected]) si


