Awesome Prompting on Vision Language Model
1.0.0
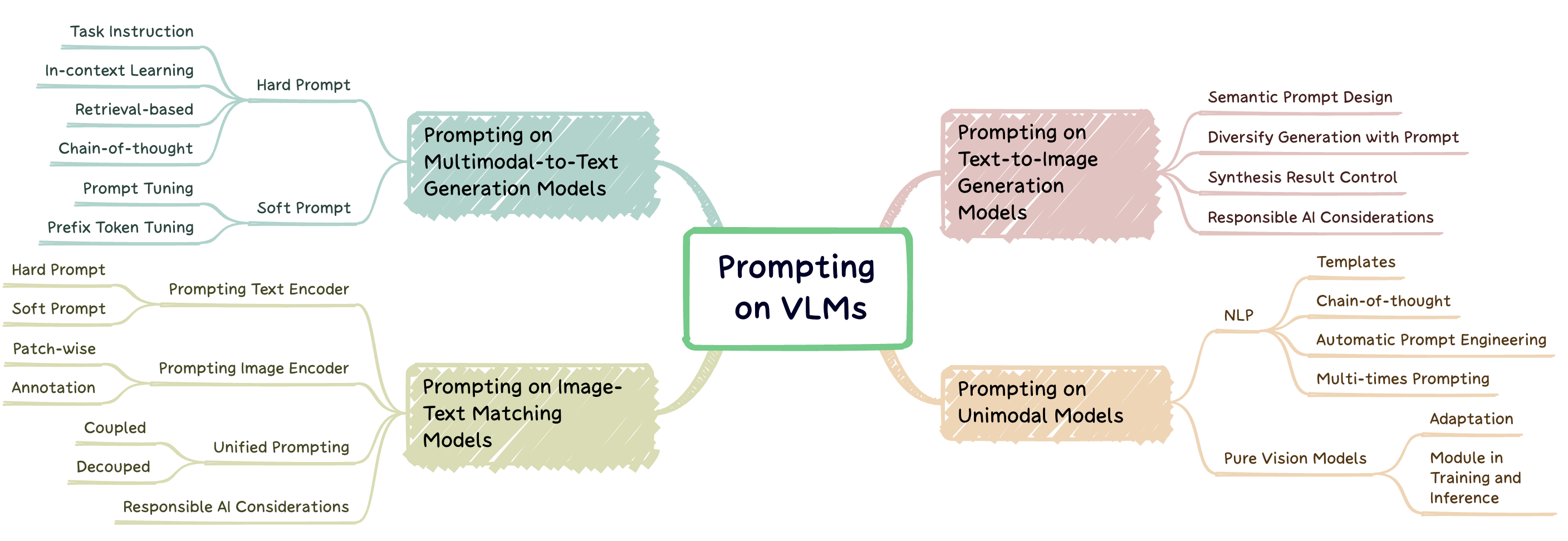
L'ingénierie rapide est une technique qui implique d'augmenter un grand modèle pré-formé avec des conseils spécifiques à la tâche, appelés invites, pour adapter le modèle à de nouvelles tâches. Ce repos vise à fournir une étude complète des recherches de pointe en ingénierie rapide sur trois types de modèles de vision en langue de vision (VLMS): modèles de génération multimodaux à texte ( par exemple , flamanto), modèles de correspondance de texte d'image ( par exemple) et des modèles de génération de texte à image ( par exemple , diffusion stable) (Fig. 1).
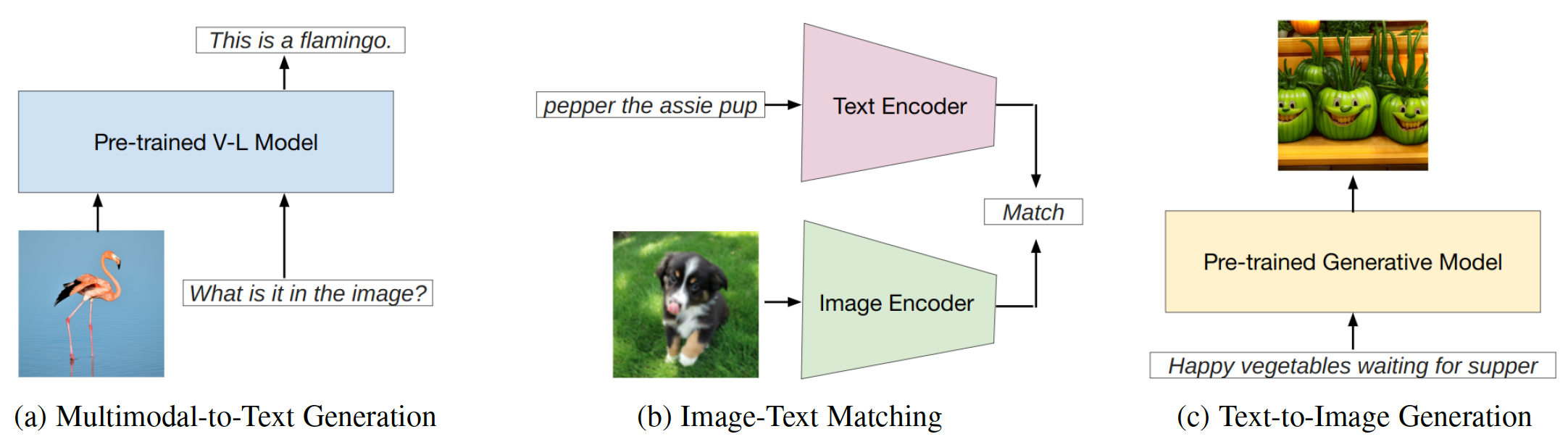
Fig. 1: Ce travail se concentre sur trois principaux types de modèles de vision.
Ce repo répertorie les documents pertinents résumés dans notre enquête:
Une étude systématique de l'ingénierie rapide sur les modèles de fondation en langue visuelle. Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tréss, Philip Torr . Preprint 2023. [PDF]
Si vous trouvez notre article et notre repo utile à vos recherches, veuillez citer l'article suivant:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}Modèle d'incitation dans la génération multimodale à texte
Modèle d'incitation dans la correspondance de texte d'image
Modèle d'incitation dans la génération de texte à l'image
Il existe deux principaux types d'approches de module de fusion basées sur l'intégration des modalités visuelles et textuelles: le coder-décodeur en tant que module de fusion multimodal et décodeur uniquement comme module de fusion multimodal . Les méthodes d'incitation peuvent être divisées en deux catégories principales (Fig. 2) en fonction de la lisibilité des modèles: invite dure et invite douce . L'invite dure comprend quatre sous-catégories: l'enseignement des tâches, l'apprentissage dans le contexte, l'invitation basée sur la récupération et l'incitation à la chaîne de réflexion . Les invites souples sont classées en deux stratégies: le réglage invite et le réglage des jetons de préfixe , selon qu'ils ajoutent en interne de nouveaux jetons à l'architecture du modèle ou les ajoutent simplement à l'entrée. Cette étude se concentre principalement sur les méthodes rapides qui évitent de modifier le modèle de base.
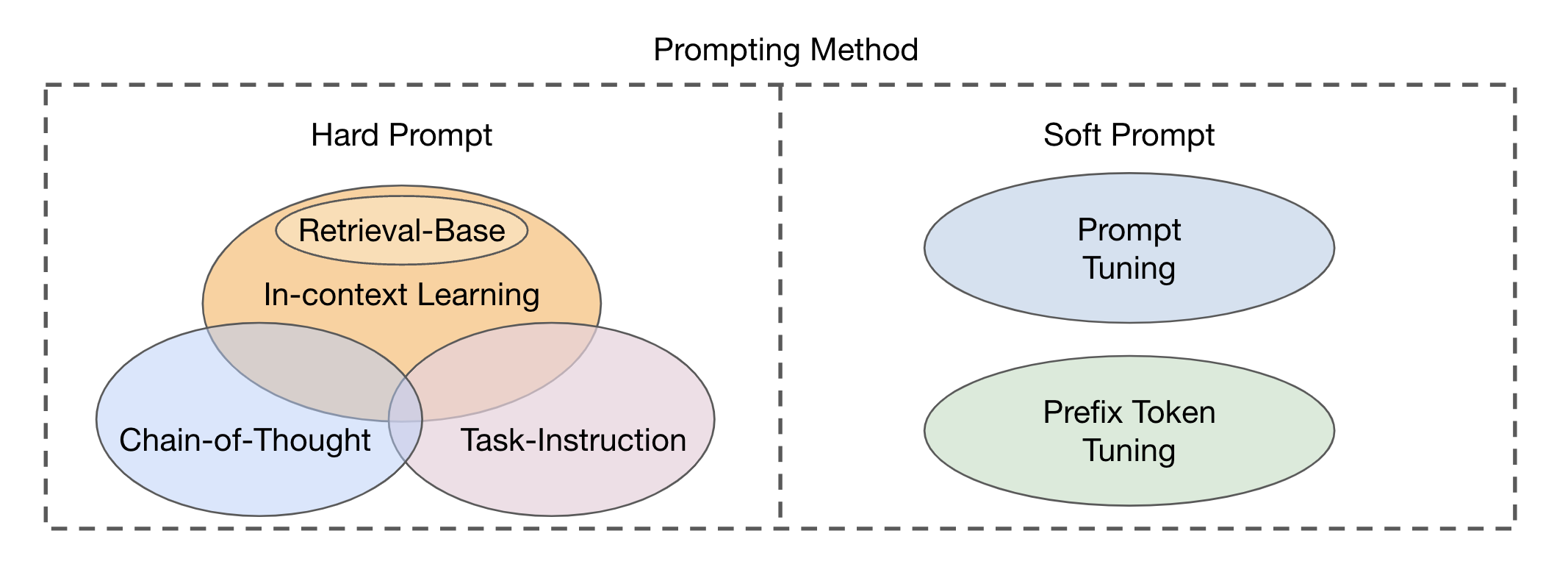
Fig. 2: Classification des méthodes d'incitation.
| Titre | Lieu | Année | Code si disponible | Commentaire |
|---|---|---|---|---|
| Unification des tâches de vision et de langue via la génération de texte | ICML | 2021 | Github | Fusion d'encodeur-décodeur; Préfixes de texte comme invite |
| Simvlm: modèle de langage visuel simple pré-formation avec une supervision faible | ICLR | 2022 | Github | Fusion d'encodeur-décodeur; Préfixes de texte comme invite |
| OFA: architectures unificatrices, tâches et modalités à travers un cadre d'apprentissage simple à séquence à la séquence | ICML | 2022 | Github | Fusion d'encodeur-décodeur; Préfixes de texte comme invite |
| Pali: un modèle d'image linguistique multilingue à l'échelle conjointe | ICLR | 2023 | --- | Fusion d'encodeur-décodeur; Invite d'instruction |
| Apprentissage multimodal à quelques coups avec des modèles de langue glacés | Nezier | 2021 | Page | Fusion de décodeur uniquement; Réglage du préfixe conditionnel de l'image |
| Flamingo: un modèle de langage visuel pour l'apprentissage à quelques coups | Nezier | 2022 | Github | Fusion de décodeur uniquement; Invites de texte; |
| MAGMA - Augmentation multimodale des modèles génératifs grâce à la finetun basée sur l'adaptateur | EMNLP | 2022 | Github | Fusion de décodeur uniquement; Réglage du préfixe conditionnel de l'image |
| Blip-2: Bootstrap-Image-Image pré-formation avec des encodeurs d'image surgelés et des modèles de gros langues | ICML | 2023 | Github | Fusion de décodeur uniquement; Réglage du préfixe conditionnel de l'image |
| Les modèles de langage sont des apprenants multitâches non sortis | Blog Openai | 2019 | Github | Invite d'instructions de la tâche |
| Le test de turking: les modèles de langue peuvent-ils comprendre les instructions? | arxiv | 2020 | --- | Invite d'instructions de la tâche |
| Les modèles de langue sont des apprenants à quelques tirs | Nezier | 2020 | --- | Apprentissage en contexte |
| Apprendre à récupérer des invites à l'apprentissage en contexte | Naacl-hlt | 2022 | Github | Invitation basée sur la récupération |
| Retriever de démonstration unifiée pour l'apprentissage dans le contexte | ACL | 2023 | Github | Invitation basée sur la récupération |
| Exemplaires de composition pour l'apprentissage en contexte | ICML | 2023 | Github | Invitation basée sur la récupération |
| L'incitation de la chaîne de pensées suscite du raisonnement dans des modèles de grande langue | Nezier | 2022 | --- | Invitation à la chaîne de pensées |
| Chaîne de pensée automatique Invitant dans les modèles de grande langue | ICLR | 2023 | Github | Invitation à la chaîne de pensées |
| La puissance de l'échelle pour un réglage rapide économe en paramètres | EMNLP | 2021 | --- | Réglage rapide |
| Apprendre à demander: interroger LMS avec des mélanges d'invites souples | Naacl-hlt | 2021 | Github | Réglage rapide |
| Préfixe-réglage: optimisation des invites continues pour la génération | ACL | 2021 | Github | Réglage du préfixe |
| Réglage rapide pour les modèles génératifs de pré-entraînement multimodal | ACL | 2023 | Github | Réglage rapide sur OFA |
| La langue n'est pas tout ce dont vous avez besoin: aligner la perception avec les modèles de langue | Nezier | 2023 | Github | Invites d'instruction textuelle |
| Benchmarking Robustness des méthodes d'adaptation sur les modèles pré-formés en langue de vision | Nezier | 2024 | Page | Robustesse du réglage rapide sur les VLM |
| Vers des invites robustes sur les modèles de langue visuelle | NextGenaaisafety @ iclr | 2024 | --- | Robustesse du réglage rapide sur les VLM |
| InstructBlip: vers des modèles de langue de vision à usage général avec réglage des instructions | Nezier | 2023 | Github | Réglage rapide |
| Réglage de l'instruction visuelle | Nezier | 2023 | Github | |
| Qwen-vl: un modèle polyvalent de langue visuelle pour la compréhension, la localisation, la lecture de texte et au-delà | arxiv | 2023 | Github | Réglage rapide |
| Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic | arxiv | 2023 | Github | |
| MINIGPT-4: Amélioration de la compréhension de la vision avec des modèles avancés de grande langue | ICLR | 2023 | Github | Réglage rapide |
Selon la cible d'incitation, les méthodes existantes peuvent être classées en trois catégories: inviter le codeur de texte , invitant le codeur visuel ou invitant conjointement les deux branches comme indiqué sur la figure 2. Ces approches visent à améliorer la flexibilité et les performances spécifiques aux tâches des VLM.
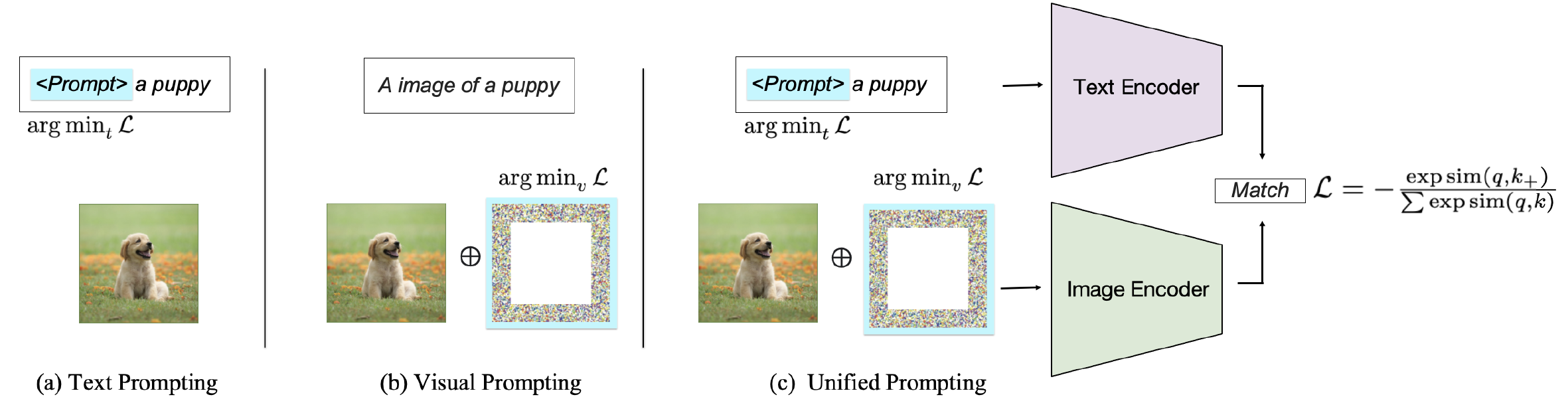
Fig. 2: Classification des méthodes d'incitation sur les VLM correspondant au texte d'image.
| Titre | Lieu | Année | Code si disponible | Commentaire |
|---|---|---|---|---|
| Apprentissage des modèles visuels transférables à partir de la supervision du langage naturel | ICML | 2021 | Github | Invites de texte dur; Invite pour la classification d'images |
| Plonger dans l'ouverture du clip | ACL | 2023 | Github | Invite du texte dur à comprendre |
| Réglage rapide du temps de test pour la généralisation des coups zéro dans les modèles de vision en langue | Nezier | 2022 | Github | Invites de texte doux |
| Apprendre à provoquer des modèles de vision de la vision | Ijcv | 2022 | Github | Invites de texte doux |
| Invoquer des modèles de langue visuelle pour une compréhension vidéo efficace | ECCV | 2022 | Github | Invites de texte doux |
| Réglage rapide de la vision de la vision à main | Wacv | 2024 | Github | Invites de texte doux |
| Apprentissage invite conditionnel pour les modèles de langue de vision | CVPR | 2022 | Github | Invites de texte doux |
| Réglage de l'invite visuelle | ECCV | 2022 | Github | Invites visuelles sur les patchs |
| Exploration des invites visuelles pour adapter des modèles à grande échelle | arxiv | 2022 | Github | Invites visuelles sur les patchs |
| Réglage rapide de la vision de la vision à main | Wacv | 2024 | Github | Invites visuelles sur les patchs |
| Libérer la puissance de l'incitation visuelle au niveau des pixels | Tmlr | 2024 | Github | Invites visuelles sur les patchs |
| Méta-visuelle de la diversité | CVPR | 2023 | Github | Invites visuelles sur les patchs |
| CPT: réglage rapide coloré pour les modèles pré-formés en langue de vision | AI ouvert | 2024 | Github | Invites d'annotation visuelle |
| Que sait Clip sur un cercle rouge? Ingénierie rapide visuelle pour les VLM | ICCV | 2023 | --- | Invites d'annotation visuelle |
| Invitation visuelle via l'image entre l'image | Nezier | 2022 | Github | Invites d'annotation visuelle |
| Vision unifiée et apprentissage invite de langue | arxiv | 2023 | Github | Incitation unifiée couplée |
| Réglage rapide de la vision de la vision à main | Wacv | 2024 | Github | Invitation unifiée découplée |
| Érable: apprentissage rapide multimodal | CVPR | 2023 | Github | Invitation unifiée découplée |
| Comprendre la robustesse adversaire zéro-shot pour les modèles à grande échelle | ICLR | 2023 | Code | Robustesse adversaire de l'invite |
| Invitation visuelle pour la robustesse contradictoire | ICASSP | 2023 | Github | Robustesse adversaire de l'invite |
| Aligner avant le fusible: Vision et représentation de la langue Apprentissage avec distillation de momentum | Nezier | 2021 | Github | Modèle de correspondance de texte d'image |
| Apprentissage rapide non supervisé pour les modèles de langue de vision | arxiv | 2022 | Github | Invites d'apprentissage non perspicables |
| Réglage rapide du temps de test pour la généralisation des coups zéro dans les modèles de vision en langue | Nezier | 2022 | Github | Invite apprenable |
| Pré-formation rapide avec plus de vingt mille classes pour la reconnaissance visuelle de vocabulaire ouverte | Nezier | 2023 | Github | Pré-formation rapide |
| Apprentissage rapide guidé par la cohérence pour les modèles de langue de vision | ICLR | 2024 | --- | Invitation unifiée découplée |
| Amélioration de l'adaptabilité et de la généralisation de l'apprentissage efficace du transfert pour les modèles de vision en langue | ACL Arr | 2024 | --- | Invite apprenable |
| Titre | Lieu | Année | Code si disponible | Commentaire |
|---|---|---|---|---|
| LMPT: réglage rapide avec une perte d'incorporation spécifique à la classe pour la reconnaissance visuelle multi-étiquettes à longueur à longue queue | Alvr | 2024 | Github | Invite à la classification d'images multi-échangers à longueur longue |
| Réglage rapide du temps de test pour la généralisation des coups zéro dans les modèles de vision en langue | Nezier | 2022 | Github | Invite apprenable; Invite la classification d'images |
| LPT: réglage rapide à longue queue pour la classification d'images | ICLR | 2023 | Github | Invite à la classification des images à longue queue |
| Textes comme images dans un réglage rapide pour la reconnaissance d'images multi-étiquettes | CVPR | 2023 | Github | Invite à la classification et à la détection d'images multiples |
| Dualcoop: Adaptation rapide à la reconnaissance multi-étiquettes avec des annotations limitées | Nezier | 2022 | Github | Invite à la classification et à la reconnaissance des images multiples |
| Réglage de l'invite visuelle pour la classification du texte à quelques coups | ICCL | 2022 | --- | Invites visuelles pour la classification du texte |
| Détection d'objets à vocabulaire ouvert via la distillation des connaissances de la vision et du langage | ICLR | 2021 | Github | Invite la détection d'objets |
| Apprendre à provoquer une détection d'objets à vocabulaire ouvert avec un modèle de vision en langue | CVPR | 2022 | Github | Invite la détection d'objets |
| Promptdet: vers la détection de vocabulaire ouverte à l'aide d'images non assurées | ECCV | 2022 | Github | Invite la détection d'objets |
| Optimisation des invites continues à la détection des relations visuelles en appuyant | Accès IEEE | 2022 | --- | Invites douces pour la détection de relations visuelles |
| Vers la génération de graphiques de scène open-vocabulaire avec des finetun basés sur une base | ECCV | 2022 | --- | Invites douces pour la détection de relations visuelles |
| Réglage invite de composition avec des indices de mouvement pour la détection de relation vidéo à vocabulaire ouvert | ICLR | 2023 | Github | RELATION Invite la détection de relations vidéo-vocabulaires ouvertes |
| Denseclip: prédiction dense guidée par le langage avec un contexte de contexte | CVPR | 2022 | Github | Invites de texte conditionné en classe pour la segmentation sémantique |
| Segmenter quoi que ce soit | ICCV | 2023 | Github | Requêtes promptes pour la segmentation sémantique |
| Adaptation du domaine via l'apprentissage rapide | IEEE | 2023 | Github | Invites textuelles spécifiques au domaine pour l'adaptation du domaine |
| Réglage de l'invite visuelle pour l'adaptation du domaine de test | arxiv | 2022 | --- | Invite l'adaptation du domaine |
| Apprendre à provoquer un apprentissage continu | CVPR | 2022 | Github | Invite l'apprentissage continu |
| DualPrompt: Invitation complémentaire pour l'apprentissage continu sans répétition | ECCV | 2022 | Github | Invite l'apprentissage continu |
| Transformateur de vision rapide pour la généralisation du domaine | arxiv | 2022 | Github | Invite la généralisation du domaine |
| Comprendre la robustesse adversaire zéro-shot pour les modèles à grande échelle | LCLR | 2022 | Github | Réglage rapide visuel sous attaque contradictoire |
| Invitation visuelle pour la robustesse contradictoire | ICASSP | 2023 | Github | Incitation visuelle à améliorer la robustesse contradictoire |
| Exploration de la vulnérabilité universelle du paradigme d'apprentissage basé sur une base | Naacl | 2022 | Github | Vulnérabilité d'incitation visuelle |
| Empoisonnement et arrière apprentissage contrastif | ICLR | 2022 | --- | Attaques de porte dérobée et d'empoisonnement sur clip |
| BADENCODER: Attaques de porte dérobée aux encodeurs pré-formés dans l'apprentissage auto-supervisé | IEEE | 2022 | Github | Attaque de porte dérobée sur clip |
| CleanClip: atténuation des attaques d'intoxication des données dans l'apprentissage contrastif multimodal | Atelier ICLR | 2023 | --- | Attaques de porte dérobée de défense sur clip |
| Débiasing Modèles de langue de vision via des invites biaisées | arxiv | 2023 | Github | Invite à soulager les préjugés |
| Titre | Lieu | Année | Code si disponible | Commentaire |
|---|---|---|---|---|
| Les modèles de diffusion battent des gans sur la synthèse d'image | Nezier | 2021 | Github | Modèles de diffusion sur la génération d'images |
| Les modèles de diffusion battent des gans sur la synthèse d'image | Nezier | 2021 | Github | Modèles de diffusion sur la génération d'images |
| Modèles probabilistes de diffusion de débrassement | Nezier | 2020 | Github | Modèles de diffusion sur la génération d'images |
| SUS-X: transfert de nom sans formation sans formation de modèles de vision en matière de vision | ICCV | 2023 | Github | Modèles de diffusion sur la génération d'images |
| Étudier l'ingénierie rapide dans les modèles de diffusion | Atelier de Neirips | 2022 | --- | Design rapide sémantique |
| Diffumask: synthétiser des images avec des annotations au niveau des pixels pour la segmentation sémantique à l'aide de modèles de diffusion | IEEE / CVF | 2023 | Github | Diversifier la génération avec une invite; Invite la génération de données synthétiques |
| Les données synthétiques des modèles génératives sont-elles prêtes à la reconnaissance d'image? | ICLR | 2023 | Github | Diversifier la génération avec une invite |
| Une image vaut un mot: personnaliser la génération de texte à l'image en utilisant une inversion textuelle | ICLR | 2023 | Github | Contrôle complexe des résultats de la synthèse via des invites |
| Dreambooth: Modèles de diffusion de texte à l'image à réglage fin pour la génération axée sur le sujet | CVPR | 2023 | Github | Contrôle complexe des résultats de la synthèse via des invites |
| Personnalisation multi-concept de la diffusion du texte à l'image | CVPR | 2023 | Github | Contrôle complexe des résultats de la synthèse via des invites |
| Édition d'image rapide avec un contrôle de l'attention | ICLR | 2023 | --- | Contrôle complexe des résultats de la synthèse via des invites |
| Guide de diffusion structurée sans formation pour la synthèse de texte à l'image compositionnelle | ICLR | 2023 | Github | Génération de texte à image contrôlable |
| Auto-service de diffusion pour la génération d'images contrôlables | Nezier | 2023 | Page | Génération de texte à image contrôlable |
| Imagine: modification d'image réelle basée sur le texte avec des modèles de diffusion | CVPR | 2023 | Github | Génération de texte à image contrôlable |
| Ajout d'un contrôle conditionnel aux modèles de diffusion de texte à l'image | IEEE / CVF | 2023 | Github | Génération de texte à image contrôlable |
| Édition d'image rapide avec un contrôle de l'attention | ICLR | 2023 | Github | Contrôle complexe des résultats de la synthèse via des invites |
| ImaginaryNet: Apprendre des détecteurs d'objets sans vraies images et annotations | ICLR | 2023 | Github | Invite la génération de données synthétiques |
| Les données synthétiques des modèles génératives sont-elles prêtes à la reconnaissance d'image? | ICLR | 2023 | Github | Invite la génération de données synthétiques |
| Make-a-video: génération de texte à vidéo sans données de texte | ICLR | 2023 | Page | Invite la génération de texte à vidéo |
| Vidéo d'imagen: génération de vidéos haute définition avec des modèles de diffusion | arxiv | 2022 | Page | Invite la génération de texte à vidéo |
| Fatezero: fusion des attentions pour l'édition vidéo basée sur un texte | ICCV | 2023 | Github | Invite la génération de texte à vidéo |
| Tune-a-video: réglage à un coup des modèles de diffusion d'image pour la génération de texte à vidéo | ICCV | 2023 | Github | Invite la génération de texte à vidéo |
| DIFFRF: Diffusion de champ de rayonnement 3D guidé par le rendu | CVPR | 2023 | Page | Invite la génération de texte à 3D |
| DreamFusion: texte à 3D en utilisant la diffusion 2D | ICLR Notable Top 5% | 2023 | Page | Invite la génération de texte à 3D |
| Dream3d: synthèse de texte à 3D à tir zéro utilisant des modèles de diffusion de forme 3D de forme 3D et de texte à l'image | CVPR | 2023 | Page | Invite la génération de texte à 3D |
| MotionDiffuse: génération de mouvement humain axé sur le texte avec modèle de diffusion | IEEE | 2024 | Page | Invite la génération de texte à mouvement |
| Flame: synthèse de mouvement basée sur le langage en forme libre et montage | Aaai | 2023 | Github | Invite la génération de texte à mouvement |
| MDM: modèle de diffusion de mouvement humain | ICLR | 2023 | Github | Invite la génération de texte à mouvement |
| Génération zéro-shot de livre de contes cohérent à partir d'une histoire de texte brut à l'aide de modèles de diffusion | arxiv | 2023 | --- | Invite des tâches complexes |
| Planification de procédure multimodale via une double image de texte | ICLR | 2024 | Github | Invite des tâches complexes |
| Des attaques de vol invite contre les modèles de génération de texte à l'image | Symposium de sécurité Usenix | 2023 | --- | Invite une IA responsable |
| Attaques d'inférence de l'adhésion contre les modèles de génération de texte à l'image | ICLR | 2023 | --- | Attaques d'adhésion contre les modèles de texte à l'image |
| Les modèles de diffusion sont-ils vulnérables aux attaques d'inférence des membres? | ICML | 2023 | Github | Attaques d'adhésion contre les modèles de texte à l'image |
| Une extraction reproductible d'images d'entraînement à partir de modèles de diffusion | arxiv | 2023 | Github | Attaques d'adhésion contre les modèles de texte à l'image |
| Diffusion équitable: instruction de modèles de génération de texte à l'image en équité | arxiv | 2023 | Github | Invite sur les modèles de texte à l'image en considérant l'équité |
| Les préjugés sociaux à travers l'objectif de génération de texte à l'image | AAAI / ACM | 2023 | --- | Invite sur les modèles de texte à l'image en considérant les biais |
| T2IAT: Mesurer la valence et les biais stéréotypés dans la génération de texte à l'image | ACL | 2023 | --- | Invite sur les modèles de texte à l'image en considérant les biais |
| Biais stable: analyser les représentations sociétales dans les modèles de diffusion | Nezier | 2023 | --- | Invite sur les modèles de texte à l'image en considérant les biais |
| Une étude pilote de l'attaque contradictoire sans requête contre la diffusion stable | CVPR | 2023 | --- | Robustesse adversaire des modèles de texte à l'image |
| Modèles de diffusion pour une attaque contradictoire imperceptible et transférable | ICLR | 2024 | Github | Robustesse adversaire des modèles de texte à l'image |
| Modèles de diffusion pour la purification contradictoire | ICML | 2022 | Github | Robustesse adversaire des modèles de texte à l'image |
| Rickrolling l'artiste: Injection des délais dans les encodeurs de texte pour la synthèse du texte à l'image | ICCV | 2023 | --- | Attaque de la porte dérobée sur les modèles de texte à l'image |
| Les modèles de diffusion de texte à l'image peuvent être facilement déambulés par intoxication multimodale | ACM MM | 2023 | --- | Attaque de la porte dérobée sur les modèles de texte à l'image |
| Personnalisation en tant que raccourci pour l'attaque de porte dérobée à quelques coups contre les modèles de diffusion de texte à l'image | Aaai | 2024 | --- | Attaque de la porte dérobée sur les modèles de texte à l'image |
Veuillez nous contacter ([email protected], [email protected]) si


