Awesome Prompting on Vision Language Model
1.0.0
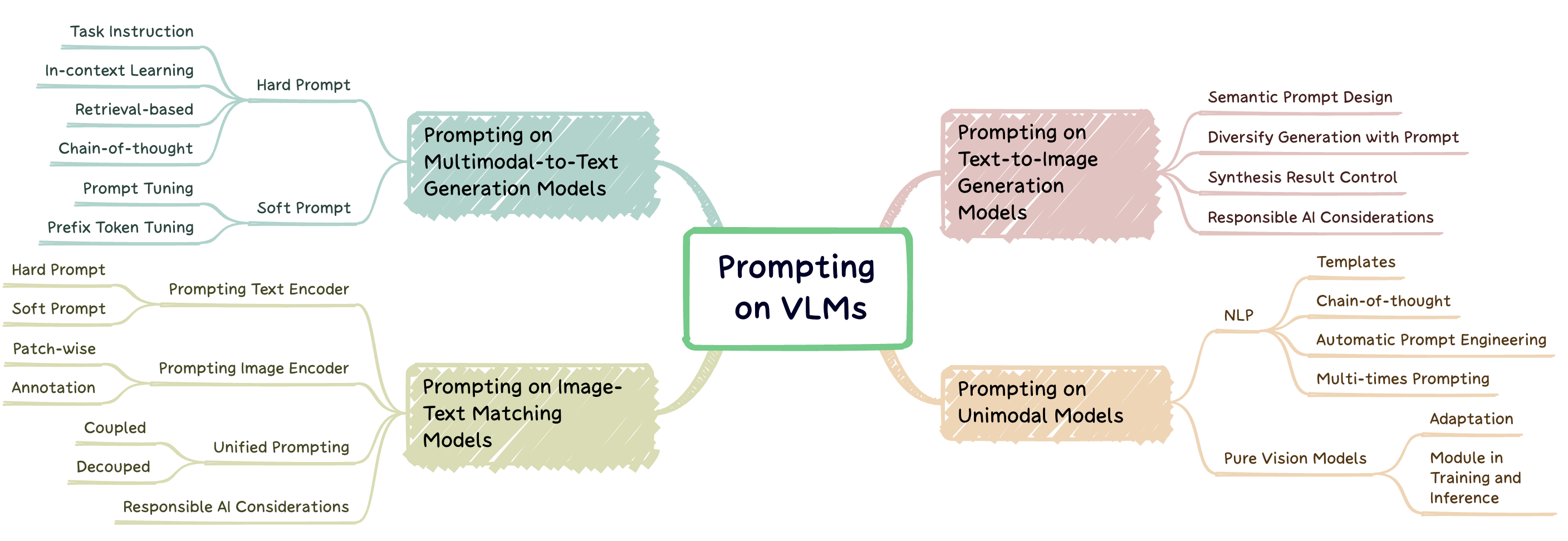
プロンプトエンジニアリングは、モデルを新しいタスクに適応させるために、プロンプトと呼ばれるタスク固有のヒントを使用して、大規模な事前訓練モデルを強化することを含む手法です。このレポは、 3つのタイプの視覚言語モデル(VLMS)の迅速なエンジニアリングにおける最先端の研究の包括的な調査を提供することを目的としています:マルチモーダルからテキストからテキストの生成モデル(フラミンゴなど)、画像テキストマッチングモデル(クリップなど)、およびテキストから画像の生成モデル(例、安定した拡散)(図1)。
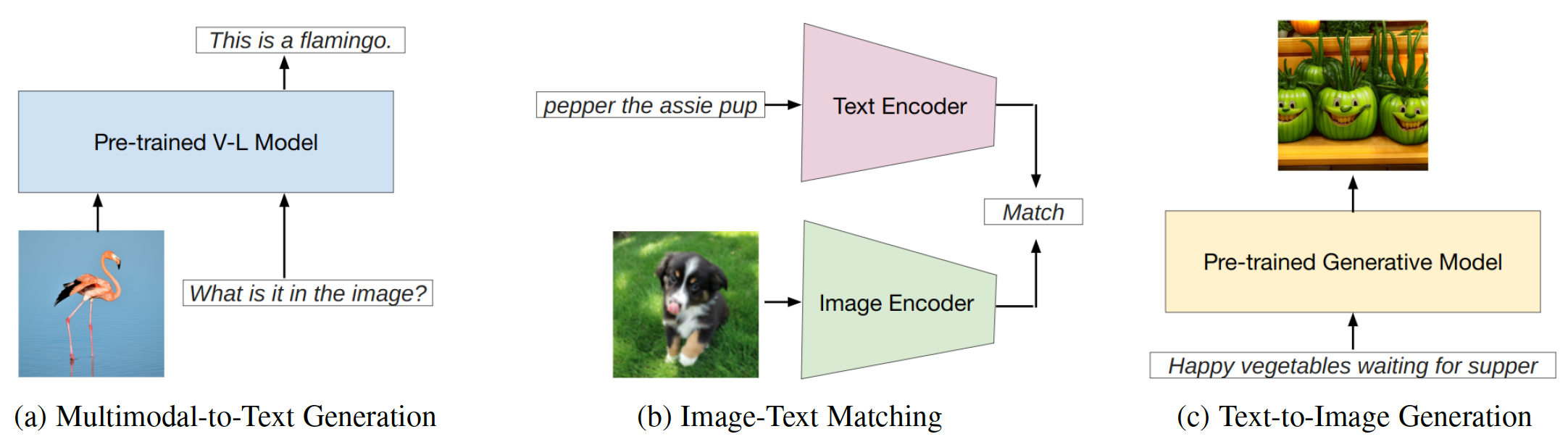
図1:この作業は、視覚言語モデルの3つの主要なタイプに焦点を当てています。
このレポは、調査に要約されている関連書類をリストします。
Vision-Language Foundationモデルに関する迅速なエンジニアリングの体系的な調査。 Jindong Gu、Zhen Han、Shuo Chen、Ahmad Beirami、Bailan He、Gengyuan Zhang、Ruotong Liao、Yao Qin、Volker Tresp、Philip Torr 。プリプリント2023。[PDF]
私たちの論文とレポがあなたの研究に役立つと見つけたら、次の論文を引用してください。
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}マルチモーダルからテキストの生成のモデルをプロンプトします
画像テキストマッチングでモデルをプロンプトします
テキストから画像の生成におけるモデルをプロンプトします
視覚モダリティとテキストモダリティの統合に基づいた融合モジュールアプローチには、マルチモーダル融合モジュールとしてのエンコーダーデコーダーと、マルチモーダル融合モジュールとしてのデコーダーのみの2つの主要なタイプがあります。プロンプトの方法は、テンプレートの読みやすさに基づいて、ハードプロンプトとソフトプロンプトの2つの主要なカテゴリ(図2)に分けることができます。ハードプロンプトには、タスク命令、コンテキスト内学習、検索ベースのプロンプト、およびチェーンオブ考えのプロンプトの4つのサブカテゴリが含まれます。ソフトプロンプトは、モデルのアーキテクチャに新しいトークンを内部的に追加するか、単に入力に追加するかどうかに基づいて、プロンプトチューニングとプレフィックストークンチューニングの2つの戦略に分類されます。この研究は、主にベースモデルの変更を避ける迅速な方法に集中しています。
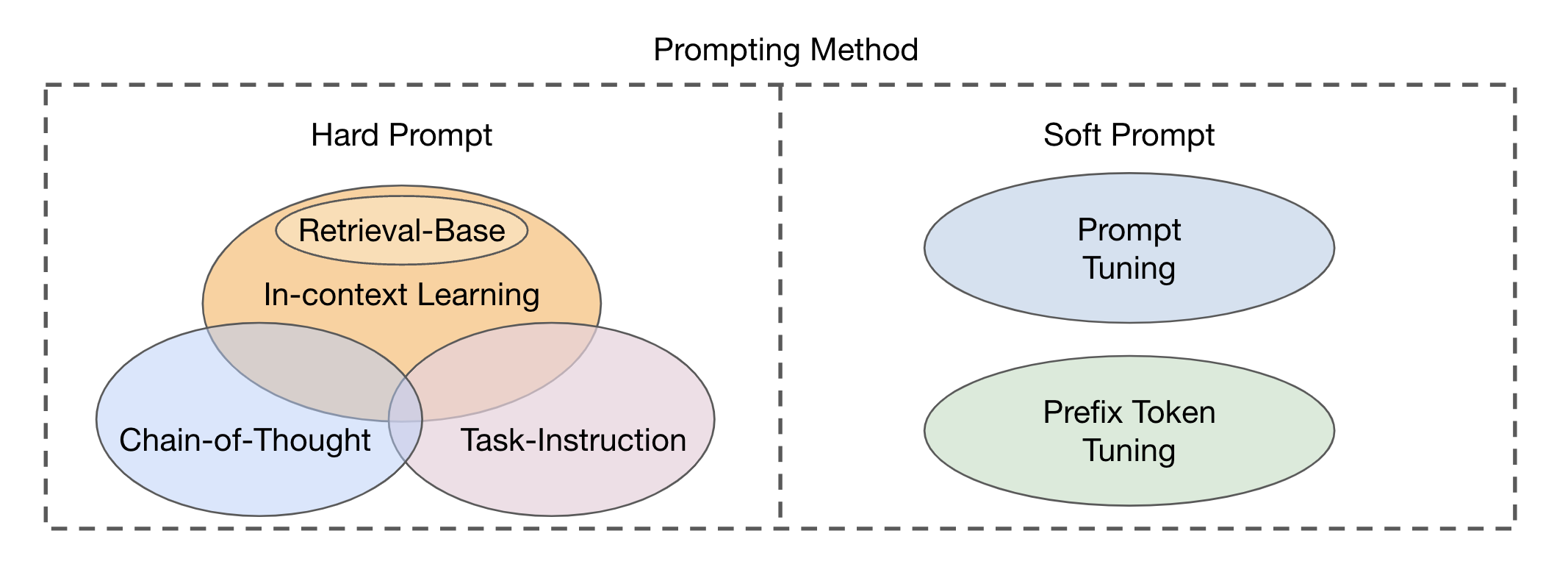
図2:プロンプトの方法の分類。
| タイトル | 会場 | 年 | 利用可能な場合はコード | コメント |
|---|---|---|---|---|
| テキスト生成によるビジョンと言語のタスクを統合します | ICML | 2021 | github | エンコーダデコーダーフュージョン。プロンプトとしてのテキストプレフィックス |
| SIMVLM:監督が弱いという単純な視覚言語モデルの事前販売 | ICLR | 2022 | github | エンコーダデコーダーフュージョン。プロンプトとしてのテキストプレフィックス |
| ofa:単純なシーケンスからシーケンス学習フレームワークを通じて、アーキテクチャ、タスク、およびモダリティを統一する | ICML | 2022 | github | エンコーダデコーダーフュージョン。プロンプトとしてのテキストプレフィックス |
| Pali:共同でスケーリングされた多言語言語イメージモデル | ICLR | 2023 | --- | エンコーダデコーダーフュージョン。命令プロンプト |
| 凍結言語モデルを使用したマルチモーダルの少数の学習 | ニューリップ | 2021 | ページ | デコーダーのみの融合;画像条件付きプレフィックスチューニング |
| フラミンゴ:少数のショット学習の視覚言語モデル | ニューリップ | 2022 | github | デコーダーのみの融合;テキストプロンプト; |
| マグマ - アダプターベースのFinetuningを介した生成モデルのマルチモーダル増強 | emnlp | 2022 | github | デコーダーのみの融合;画像条件付きプレフィックスチューニング |
| BLIP-2:フローズン画像エンコーダーと大規模な言語モデルを使用したブートストラップ言語イメージプリトレーニング | ICML | 2023 | github | デコーダーのみの融合;画像条件付きプレフィックスチューニング |
| 言語モデルは、教師のないマルチタスク学習者です | Openaiブログ | 2019年 | github | タスク命令プロンプト |
| ターキングテスト:言語モデルは指示を理解できますか? | arxiv | 2020 | --- | タスク命令プロンプト |
| 言語モデルは、少ないショット学習者です | ニューリップ | 2020 | --- | コンテキスト学習 |
| コンテキスト内学習のプロンプトを取得することを学ぶ | naacl-hlt | 2022 | github | 検索ベースのプロンプト |
| コンテキスト内学習のための統一デモンストレーションレトリバー | ACL | 2023 | github | 検索ベースのプロンプト |
| コンテキスト学習のための構成の模範 | ICML | 2023 | github | 検索ベースのプロンプト |
| チェーンオブサブは、大規模な言語モデルで推論を引き出します | ニューリップ | 2022 | --- | 考え方のプロンプト |
| 大規模な言語モデルでの自動チェーンのプロンプト | ICLR | 2023 | github | 考え方のプロンプト |
| パラメーター効率の高いプロンプトチューニングのスケールの力 | emnlp | 2021 | --- | 迅速なチューニング |
| 尋ねる方法を学ぶ:ソフトプロンプトの混合物でLMSをクエリする | naacl-hlt | 2021 | github | 迅速なチューニング |
| プレフィックス調整:生成の連続プロンプトの最適化 | ACL | 2021 | github | プレフィックスチューニング |
| 生成マルチモーダルの前提条件モデルの迅速な調整 | ACL | 2023 | github | OFAの迅速なチューニング |
| 言語はあなたが必要とするすべてではありません:知覚を言語モデルと調整する | ニューリップ | 2023 | github | テキスト命令プロンプト |
| 事前に訓練されたビジョン言語モデルの適応方法の堅牢性のベンチマーク | ニューリップ | 2024 | ページ | VLMSでのプロンプトチューニングの堅牢性 |
| ビジョン言語モデルの堅牢なプロンプトに向けて | NEXTGEANAISAFETY@ICLR | 2024 | --- | VLMSでのプロンプトチューニングの堅牢性 |
| InstructBlip:命令調整を伴う汎用ビジョン言語モデルに向けて | ニューリップ | 2023 | github | 迅速なチューニング |
| 視覚的な指示のチューニング | ニューリップ | 2023 | github | |
| QWEN-VL:理解、ローカリゼーション、テキストの読み取りなどのための多目的なビジョン言語モデル | arxiv | 2023 | github | 迅速なチューニング |
| シクラ:マルチモーダルLLMの参照対話マジックを解き放ちます | arxiv | 2023 | github | |
| MINIGPT-4:高度な大規模な言語モデルを使用した視覚言語の理解の向上 | ICLR | 2023 | github | 迅速なチューニング |
プロンプトのターゲットに応じて、既存のメソッドを3つのカテゴリに分類できます。テキストエンコーダのプロンプト、視覚エンコーダーのプロンプト、または図2に示すように両方のブランチを共同で促します。これらのアプローチは、VLMSの柔軟性とタスク固有のパフォーマンスを向上させることを目的としています。
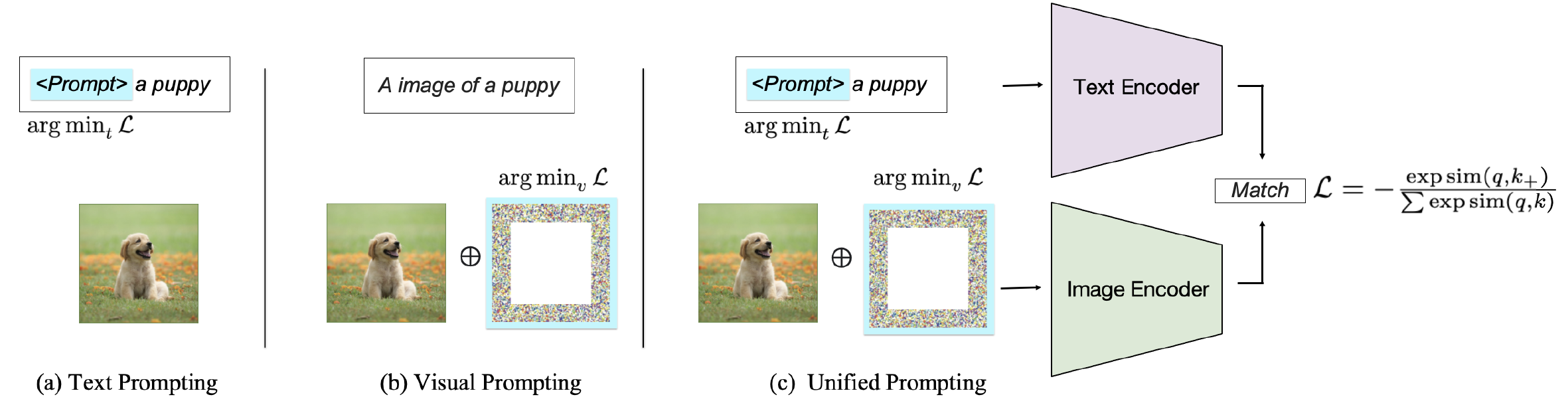
図2:画像テキストマッチングVLMでのプロンプトメソッドの分類。
| タイトル | 会場 | 年 | 利用可能な場合はコード | コメント |
|---|---|---|---|---|
| 自然言語監督からの移転可能な視覚モデルの学習 | ICML | 2021 | github | ハードテキストプロンプト。画像分類のプロンプト |
| クリップの開放性を掘り下げます | ACL | 2023 | github | ハードテキストは理解するためのプロンプトが表示されます |
| 視覚言語モデルのゼロショット一般化のテスト時間プロンプトチューニング | ニューリップ | 2022 | github | ソフトテキストプロンプト |
| ビジョン言語モデルを促すことを学ぶ | IJCV | 2022 | github | ソフトテキストプロンプト |
| 効率的なビデオ理解のために視覚言語モデルを促します | ECCV | 2022 | github | ソフトテキストプロンプト |
| マルチタスクビジョン言語プロンプトチューニング | WACV | 2024 | github | ソフトテキストプロンプト |
| ビジョン言語モデルの条件付きプロンプト学習 | CVPR | 2022 | github | ソフトテキストプロンプト |
| 視覚的なプロンプトチューニング | ECCV | 2022 | github | 視覚的なパッチごとのプロンプト |
| 大規模なモデルを適応させるための視覚的なプロンプトの調査 | arxiv | 2022 | github | 視覚的なパッチごとのプロンプト |
| マルチタスクビジョン言語プロンプトチューニング | WACV | 2024 | github | 視覚的なパッチごとのプロンプト |
| ピクセルレベルでの視覚プロンプトの力を解き放つ | TMLR | 2024 | github | 視覚的なパッチごとのプロンプト |
| 多様性を認識しているメタビジュアルプロンプト | CVPR | 2023 | github | 視覚的なパッチごとのプロンプト |
| CPT:事前に訓練されたビジョン言語モデルのカラフルな迅速な調整 | AIオープン | 2024 | github | 視覚的な注釈プロンプト |
| クリップは赤い円について何を知っていますか? VLMSの視覚的なプロンプトエンジニアリング | ICCV | 2023 | --- | 視覚的な注釈プロンプト |
| 画像の開始を介した視覚的なプロンプト | ニューリップ | 2022 | github | 視覚的な注釈プロンプト |
| 統一されたビジョンと言語迅速な学習 | arxiv | 2023 | github | 結合統合プロンプト |
| マルチタスクビジョン言語プロンプトチューニング | WACV | 2024 | github | 分離された統一プロンプト |
| メープル:マルチモーダルプロンプト学習 | CVPR | 2023 | github | 分離された統一プロンプト |
| 大規模モデルのゼロショット敵対的堅牢性を理解する | ICLR | 2023 | コード | プロンプトの敵対的な堅牢性 |
| 敵対的な堅牢性の視覚的なプロンプト | ICASSP | 2023 | github | プロンプトの敵対的な堅牢性 |
| ヒューズの前に並べる:勢いの蒸留でビジョンと言語表現の学習 | ニューリップ | 2021 | github | 画像テキストマッチングモデル |
| ビジョン言語モデルの監視されていない迅速な学習 | arxiv | 2022 | github | 熟成されていない学習可能なプロンプト |
| 視覚言語モデルのゼロショット一般化のテスト時間プロンプトチューニング | ニューリップ | 2022 | github | 学習可能なプロンプト |
| オープンボキャブラリーの視覚認識のための2万を超えるクラスを備えた迅速なトレーニングを促す | ニューリップ | 2023 | github | トレーニング前のプロンプト |
| ビジョン言語モデルの一貫性ガイド付きプロンプト学習 | ICLR | 2024 | --- | 分離された統一プロンプト |
| 視覚言語モデルの効率的な転送学習の適応性と一般化の改善 | ACL arr | 2024 | --- | 学習可能なプロンプト |
| タイトル | 会場 | 年 | 利用可能な場合はコード | コメント |
|---|---|---|---|---|
| LMPT:ロングテールされたマルチラベル視覚認識のためのクラス固有の埋め込み損失による迅速な調整 | ALVR | 2024 | github | ロングテールのマルチラベル画像分類のプロンプト |
| 視覚言語モデルのゼロショット一般化のテスト時間プロンプトチューニング | ニューリップ | 2022 | github | 学習可能なプロンプト。画像分類のプロンプト |
| LPT:画像分類のためのロングテールプロンプトチューニング | ICLR | 2023 | github | ロングテール画像分類のプロンプト |
| マルチラベル画像認識のための迅速な調整の画像としてのテキスト | CVPR | 2023 | github | マルチラベル画像の分類と検出のプロンプト |
| デュアルクープ:限られた注釈付きのマルチラベル認識への迅速な適応 | ニューリップ | 2022 | github | マルチラベル画像の分類と認識のプロンプト |
| 少数のショットテキスト分類の視覚的なプロンプトチューニング | ICCL | 2022 | --- | テキスト分類の視覚的なプロンプト |
| ビジョンと言語の知識の蒸留によるオープンボキャブラリーオブジェクトの検出 | ICLR | 2021 | github | オブジェクト検出のプロンプト |
| ビジョン言語モデルを使用したオープンボキャブラリーオブジェクトの検出を促すことを学ぶ | CVPR | 2022 | github | オブジェクト検出のプロンプト |
| PROMPTDET:未承認の画像を使用したオープンボキャブラリー検出に向けて | ECCV | 2022 | github | オブジェクト検出のプロンプト |
| 接続調整による視覚関係検出の連続プロンプトを最適化します | IEEEアクセス | 2022 | --- | 視覚関係検出のソフトプロンプト |
| プロンプトベースのFinetuningを備えたオープンボキャブラリーシーングラフ生成に向けて | ECCV | 2022 | --- | 視覚関係検出のソフトプロンプト |
| オープンボキャブラリービデオ関係の検出のためのモーションキューによる構成プロンプトチューニング | ICLR | 2023 | github | 関係は、ビデオのオープンボキャブラリー関係の検出のプロンプトがあります |
| デンズクラップ:コンテキストを意識したプロンプトを使用した言語誘導密度の高い予測 | CVPR | 2022 | github | セマンティックセグメンテーションのクラス条件付きテキストプロンプト |
| 何でもセグメント | ICCV | 2023 | github | セマンティックセグメンテーションのためのプロンプトクエリ |
| 迅速な学習によるドメイン適応 | IEEE | 2023 | github | ドメイン適応のためのドメイン固有のテキストプロンプト |
| テスト時間ドメイン適応の視覚的なプロンプトチューニング | arxiv | 2022 | --- | ドメイン適応のプロンプト |
| 継続的な学習を促すことを学ぶ | CVPR | 2022 | github | 継続的な学習のプロンプト |
| DualPrompt:リハーサルのない継続的な学習のための補完的なプロンプト | ECCV | 2022 | github | 継続的な学習のプロンプト |
| ドメイン一般化のための迅速な視覚変圧器 | arxiv | 2022 | github | ドメイン一般化のプロンプト |
| 大規模モデルのゼロショット敵対的堅牢性を理解する | LCLR | 2022 | github | 敵対的な攻撃の下での視覚的な迅速な調整 |
| 敵対的な堅牢性の視覚的なプロンプト | ICASSP | 2023 | github | 敵対的な堅牢性を改善するための視覚的なプロンプト |
| 迅速な学習パラダイムの普遍的な脆弱性の調査 | Naacl | 2022 | github | 視覚的な促進脆弱性 |
| 中毒とバックドアコントラスト学習 | ICLR | 2022 | --- | クリップに対するバックドアおよび中毒攻撃 |
| BADENCODER:自己教師の学習における事前に訓練されたエンコーダーに対するバックドア攻撃 | IEEE | 2022 | github | クリップに対するバックドア攻撃 |
| CleanClip:マルチモーダル対照学習におけるデータ中毒攻撃を緩和します | ICLRワークショップ | 2023 | --- | クリップに対する防衛バックドア攻撃 |
| バイアスプロンプトを介したビジョン言語モデルの削除 | arxiv | 2023 | github | バイアスを軽減するプロンプト |
| タイトル | 会場 | 年 | 利用可能な場合はコード | コメント |
|---|---|---|---|---|
| 拡散モデルは、画像合成でGANを打ち負かします | ニューリップ | 2021 | github | 画像生成の拡散モデル |
| 拡散モデルは、画像合成でGANを打ち負かします | ニューリップ | 2021 | github | 画像生成の拡散モデル |
| 拡散確率モデルを除去します | ニューリップ | 2020 | github | 画像生成の拡散モデル |
| SUS-X:ビジョン言語モデルのトレーニングなしの名前のみの転送 | ICCV | 2023 | github | 画像生成の拡散モデル |
| 拡散モデルの迅速なエンジニアリングの調査 | ニューリップスワークショップ | 2022 | --- | セマンティックプロンプトデザイン |
| diffumask:拡散モデルを使用したセマンティックセグメンテーションのためのピクセルレベルの注釈で画像を合成する | IEEE/CVF | 2023 | github | プロンプトで生成を多様化します。合成データ生成のプロンプト |
| 生成モデルの合成データは画像認識の準備ができていますか? | ICLR | 2023 | github | プロンプトで生成を多様化します |
| 画像は一言で言えば:テキストの反転を使用したテキストからイメージの生成をパーソナライズする | ICLR | 2023 | github | プロンプトを介した合成結果の複雑な制御 |
| DreamBooth:対象主導の生成のためのテキストから画像への拡散モデルを微調整します | CVPR | 2023 | github | プロンプトを介した合成結果の複雑な制御 |
| テキスト間拡散のマルチコンセプトカスタマイズ | CVPR | 2023 | github | プロンプトを介した合成結果の複雑な制御 |
| クロス注意コントロールを備えたプロンプトからプロンプトの画像編集 | ICLR | 2023 | --- | プロンプトを介した合成結果の複雑な制御 |
| 組成のテキストから画像合成のためのトレーニングフリー構造拡散ガイダンス | ICLR | 2023 | github | 制御可能なテキストから画像への生成 |
| 制御可能な画像生成のための拡散自己調節 | ニューリップ | 2023 | ページ | 制御可能なテキストから画像への生成 |
| Imagic:拡散モデルを使用したテキストベースの実際の画像編集 | CVPR | 2023 | github | 制御可能なテキストから画像への生成 |
| テキスト間拡散モデルに条件付きコントロールを追加します | IEEE/CVF | 2023 | github | 制御可能なテキストから画像への生成 |
| クロス注意コントロールを備えたプロンプトからプロンプトの画像編集 | ICLR | 2023 | github | プロンプトを介した合成結果の複雑な制御 |
| ImaginaryNet:実際の画像や注釈なしの学習オブジェクト検出器 | ICLR | 2023 | github | 合成データ生成のプロンプト |
| 生成モデルの合成データは画像認識の準備ができていますか? | ICLR | 2023 | github | 合成データ生成のプロンプト |
| Make-A-Video:テキスト対ビデオのないテキストからビデオへの生成 | ICLR | 2023 | ページ | テキストからビデオへの生成のプロンプト |
| Imagenビデオ:拡散モデルを備えた高解像度のビデオ生成 | arxiv | 2022 | ページ | テキストからビデオへの生成のプロンプト |
| Fatezero:ゼロショットテキストベースのビデオ編集に対する融合の注意 | ICCV | 2023 | github | テキストからビデオへの生成のプロンプト |
| Tune-A-Video:テキストからビデオへの生成のための画像拡散モデルのワンショットチューニング | ICCV | 2023 | github | テキストからビデオへの生成のプロンプト |
| DIFFRF:レンダリングガイド付き3D放射輝度フィールド拡散 | CVPR | 2023 | ページ | テキストから3Dの世代のプロンプト |
| DreamFusion:2D拡散を使用したテキストから3D | ICLR注目すべきトップ5% | 2023 | ページ | テキストから3Dの世代のプロンプト |
| dream3d:3D形状以前およびテキストから画像への拡散モデルを使用したゼロショットテキストから3D合成 | CVPR | 2023 | ページ | テキストから3Dの世代のプロンプト |
| MotionDiffuse:拡散モデルを備えたテキスト駆動型の人間の動き生成 | IEEE | 2024 | ページ | テキストからモーションの生成のプロンプト |
| 炎:フリーフォーム言語ベースのモーション合成と編集 | aaai | 2023 | github | テキストからモーションの生成のプロンプト |
| MDM:人間の運動拡散モデル | ICLR | 2023 | github | テキストからモーションの生成のプロンプト |
| 拡散モデルを使用したプレーンテキストストーリーからの一貫したストーリーブックのゼロショット生成 | arxiv | 2023 | --- | 複雑なタスクのプロンプト |
| デュアルテキストイメージプロンプトによるマルチモーダル手続き計画 | ICLR | 2024 | github | 複雑なタスクのプロンプト |
| テキストからイメージの生成モデルに対する攻撃を迅速に盗む | USENIXセキュリティシンポジウム | 2023 | --- | 責任あるAIのプロンプト |
| テキストからイメージの生成モデルに対するメンバーシップ推論攻撃 | ICLR | 2023 | --- | テキストから画像へのモデルに対するメンバーシップ攻撃 |
| 拡散モデルはメンバーシップ推論攻撃に対して脆弱ですか? | ICML | 2023 | github | テキストから画像へのモデルに対するメンバーシップ攻撃 |
| 拡散モデルからのトレーニング画像の再現性のある抽出 | arxiv | 2023 | github | テキストから画像へのモデルに対するメンバーシップ攻撃 |
| 公正拡散:公平性に関するテキストから画像への生成モデルの指示 | arxiv | 2023 | github | 公平性を考慮したテキスト間モデルのプロンプト |
| テキストからイメージの生成レンズによる社会的偏見 | aaai/acm | 2023 | --- | バイアスを考慮したテキスト間モデルのプロンプト |
| T2IAT:テキストから画像の生成における価数とステレオタイプのバイアスの測定 | ACL | 2023 | --- | バイアスを考慮したテキスト間モデルのプロンプト |
| 安定したバイアス:拡散モデルの社会的表現の分析 | ニューリップ | 2023 | --- | バイアスを考慮したテキスト間モデルのプロンプト |
| 安定した拡散に対するクエリフリーの敵対的攻撃のパイロット研究 | CVPR | 2023 | --- | テキストからイメージモデルの敵対的な堅牢性 |
| 知覚不能で譲渡可能な敵対攻撃の拡散モデル | ICLR | 2024 | github | テキストからイメージモデルの敵対的な堅牢性 |
| 敵対的浄化のための拡散モデル | ICML | 2022 | github | テキストからイメージモデルの敵対的な堅牢性 |
| アーティストのリックロール:テキスト間合成のためにバックドアをテキストエンコーダーに注入する | ICCV | 2023 | --- | テキストからイメージのモデルに対するバックドア攻撃 |
| マルチモーダルデータ中毒を通じて、テキスト間拡散モデルを簡単に裏付けることができます | ACM MM | 2023 | --- | テキストからイメージのモデルに対するバックドア攻撃 |
| テキスト間拡散モデルに対する少数のショットバックドア攻撃のショートカットとしてのパーソナライズ | aaai | 2024 | --- | テキストからイメージのモデルに対するバックドア攻撃 |
([email protected]、[email protected])ifにお問い合わせください


