Awesome Prompting on Vision Language Model
1.0.0
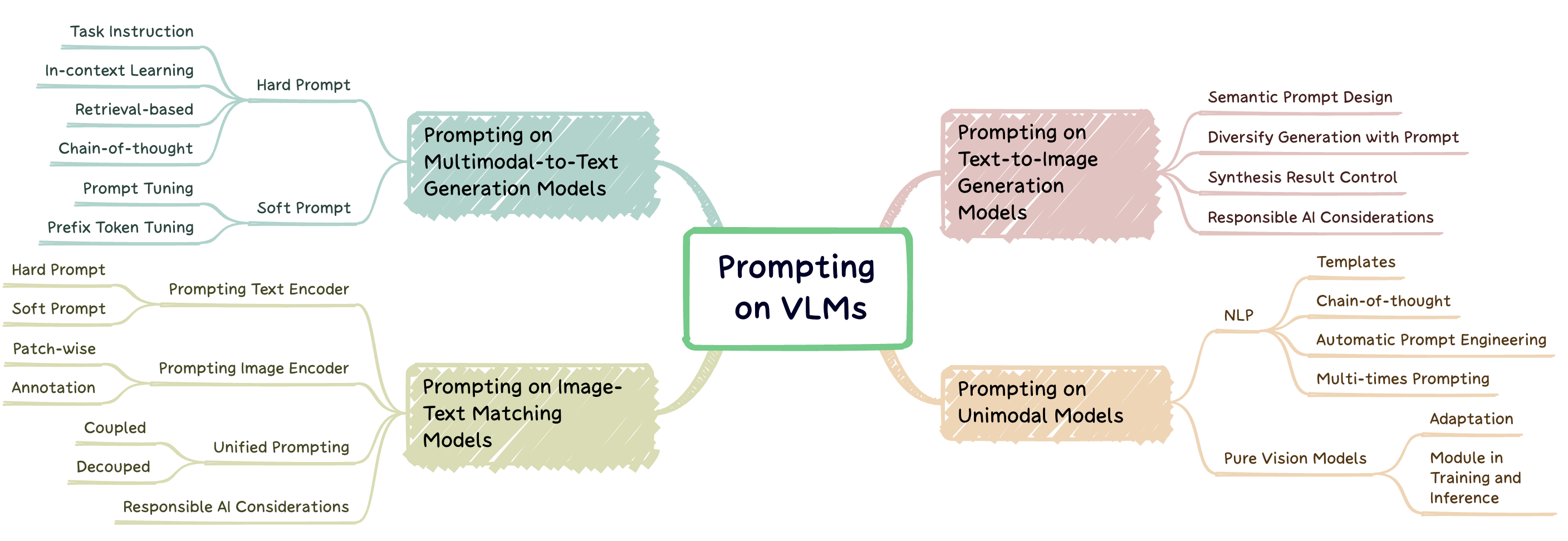
Prompt Engineering adalah teknik yang melibatkan menambah model pra-terlatih besar dengan petunjuk khusus tugas, yang dikenal sebagai prompt, untuk mengadaptasi model dengan tugas-tugas baru. Repo ini bertujuan untuk memberikan survei komprehensif tentang penelitian mutakhir dalam rekayasa cepat pada tiga jenis model penglihatan-bahasa (VLM): model generasi multimodal-ke-teks ( misalnya , flamingo), model pencocokan teks-teks ( misalnya , klip), dan model pembuatan teks-ke-gambar ( misalnya , difusi stabil) (Gambar. 1).
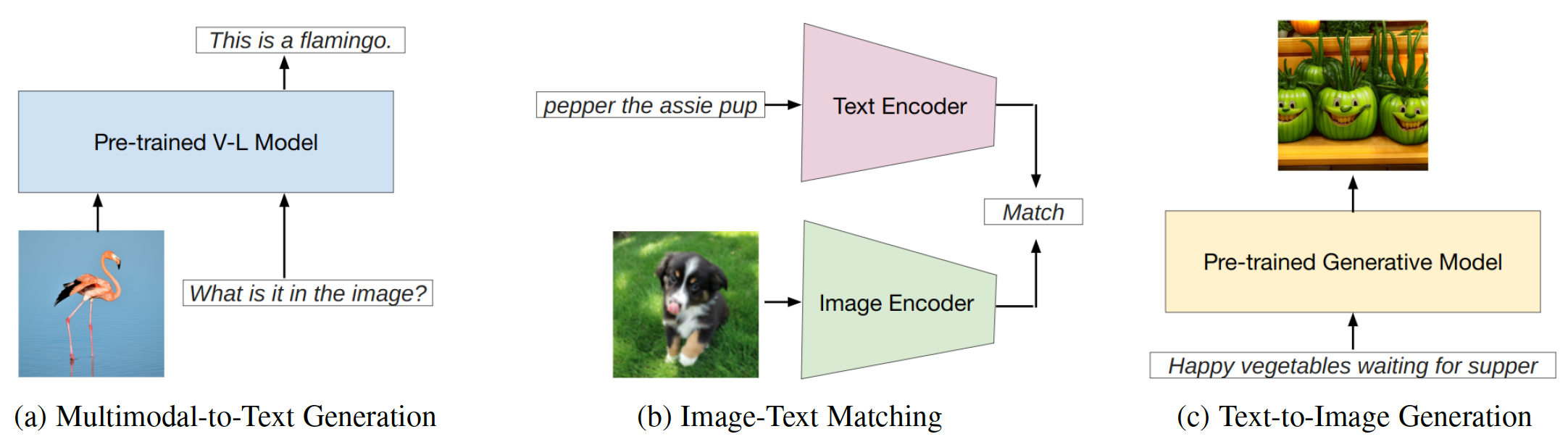
Gbr. 1: Pekerjaan ini berfokus pada tiga jenis utama model bahasa penglihatan.
Repo ini mencantumkan makalah yang relevan yang dirangkum dalam survei kami:
Survei sistematis tentang rekayasa cepat pada model yayasan penglihatan-bahasa. Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Genggyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, Philip Torr . Pracetak 2023. [PDF]
Jika Anda menemukan makalah dan repo kami bermanfaat untuk penelitian Anda, silakan kutip makalah berikut:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}Model yang mendorong dalam generasi multimodal-ke-teks
Model yang mendorong dalam pencocokan teks-teks
Model yang mendorong dalam pembuatan teks-ke-gambar
Ada dua jenis utama pendekatan modul fusi berdasarkan integrasi modalitas visual dan tekstual: Encoder-Decoder sebagai modul fusi multi-modal dan hanya decoder sebagai modul fusi multi-modal . Metode yang diminta dapat dibagi menjadi dua kategori utama (Gbr. 2) berdasarkan keterbacaan templat: Permintaan keras dan prompt lunak . Hard Prompt mencakup empat subkategori: instruksi tugas, pembelajaran dalam konteks, dorongan berbasis pengambilan, dan dorongan rantai-dipikirkan . Prompt lunak diklasifikasikan ke dalam dua strategi: penyetelan tuning dan tuning token awalan , berdasarkan apakah mereka secara internal menambahkan token baru ke arsitektur model atau hanya menambahkannya ke input. Studi ini terutama berkonsentrasi pada metode cepat yang menghindari mengubah model dasar.
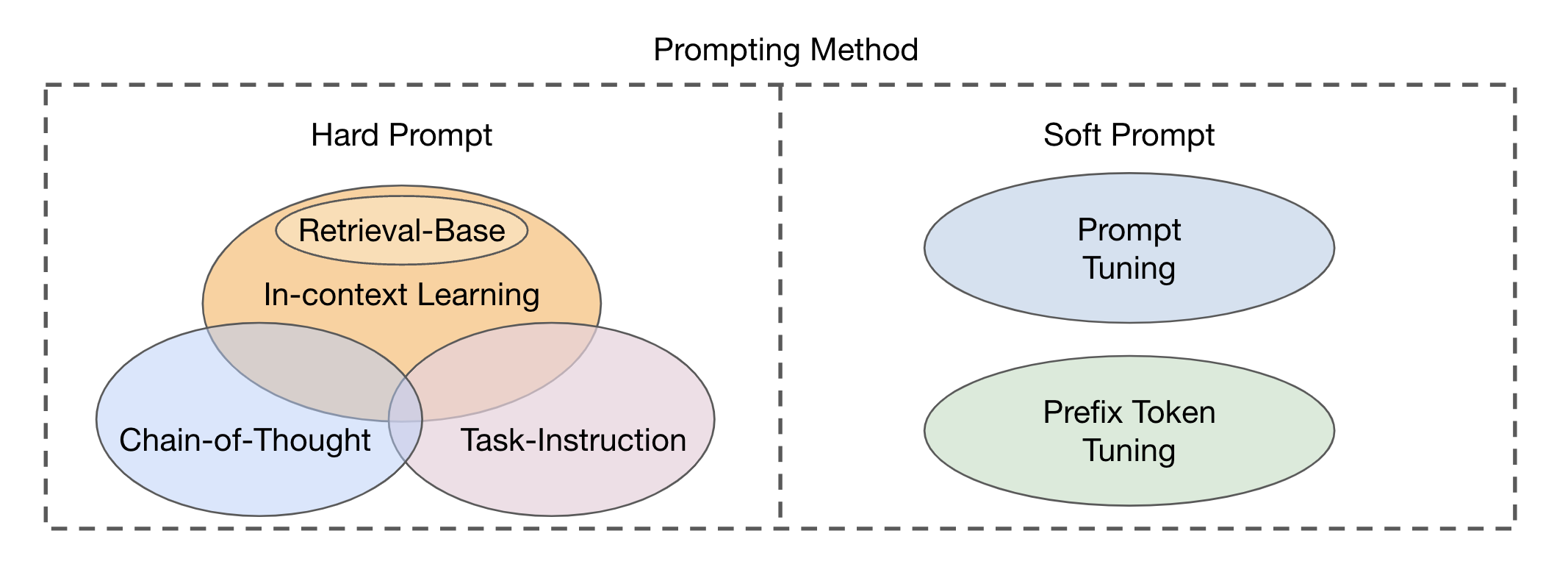
Gbr. 2: Klasifikasi metode yang diminta.
| Judul | Lokasi | Tahun | Kode jika tersedia | Komentar |
|---|---|---|---|---|
| Menyatukan tugas penglihatan dan bahasa melalui pembuatan teks | ICML | 2021 | GitHub | Fusi encoder-decoder; Awalan teks sebagai prompt |
| SIMVLM: Model bahasa visual sederhana pretraining dengan pengawasan yang lemah | Iclr | 2022 | GitHub | Fusi encoder-decoder; Awalan teks sebagai prompt |
| OFA: Mempersatahkan Arsitektur, Tugas, dan Modalitas melalui Kerangka Pembelajaran Urutan-ke-Urutan Sederhana | ICML | 2022 | GitHub | Fusi encoder-decoder; Awalan teks sebagai prompt |
| Pali: Model Multilingual-Bahasa-Bahasa yang Dipersatukan Bersama | Iclr | 2023 | --- | Fusi encoder-decoder; Instruksi Prompt |
| Pembelajaran beberapa-shot multimodal dengan model bahasa beku | Neurips | 2021 | Halaman | Fusion khusus decoder; Tuning awalan bersyarat gambar |
| Flamingo: Model Bahasa Visual untuk Pembelajaran Beberapa-Shot | Neurips | 2022 | GitHub | Fusion khusus decoder; Permintaan teks; |
| MAGMA-Augmentasi multimodal model generatif melalui finetuning berbasis adaptor | EMNLP | 2022 | GitHub | Fusion khusus decoder; Tuning awalan bersyarat gambar |
| Blip-2: Bootstrapping Pre-Training Bahasa-Image dengan Encoder Gambar Beku dan Model Bahasa Besar | ICML | 2023 | GitHub | Fusion khusus decoder; Tuning awalan bersyarat gambar |
| Model bahasa adalah pelajar multitask tanpa pengawasan | Blog Openai | 2019 | GitHub | Prompt Instruksi Tugas |
| Tes Turking: Dapatkah model bahasa memahami instruksi? | arxiv | 2020 | --- | Prompt Instruksi Tugas |
| Model bahasa adalah beberapa pelajar shot | Neurips | 2020 | --- | Pembelajaran dalam konteks |
| Belajar mengambil permintaan untuk pembelajaran dalam konteks | NAACL-HLT | 2022 | GitHub | Dorongan berbasis pengambilan |
| Retriever Demonstrasi Terpadu untuk Pembelajaran Dalam-Konteks | ACL | 2023 | GitHub | Dorongan berbasis pengambilan |
| Contoh komposisi untuk pembelajaran dalam konteks | ICML | 2023 | GitHub | Dorongan berbasis pengambilan |
| Rantai-dipikirkan mendorong memunculkan penalaran dalam model bahasa besar | Neurips | 2022 | --- | Dorongan rantai-dipikirkan |
| Rantai pemikiran otomatis yang diminta dalam model bahasa besar | Iclr | 2023 | GitHub | Dorongan rantai-dipikirkan |
| Kekuatan skala untuk penyetelan cepat parameter-efisien | EMNLP | 2021 | --- | Tuning cepat |
| Mempelajari cara bertanya: meminta LMS dengan campuran permintaan lunak | NAACL-HLT | 2021 | GitHub | Tuning cepat |
| Tuning awalan: Mengoptimalkan permintaan kontinu untuk generasi | ACL | 2021 | GitHub | Tuning awalan |
| Penyetelan cepat untuk model pretrain multimodal generatif | ACL | 2023 | GitHub | Tuning cepat pada OFA |
| Bahasa tidak semua yang Anda butuhkan: Menyelaraskan persepsi dengan model bahasa | Neurips | 2023 | GitHub | Instruksi tekstual meminta |
| Benchmarking Ketahanan metode adaptasi pada model bahasa penglihatan pra-terlatih | Neurips | 2024 | Halaman | Ketahanan penyetelan cepat pada VLMS |
| Menuju permintaan yang kuat pada model bahasa penglihatan | NextgenaSafety@iclr | 2024 | --- | Ketahanan penyetelan cepat pada VLMS |
| Instruktur Instruktur: Menuju model bahasa penglihatan serba guna dengan penyetelan instruksi | Neurips | 2023 | GitHub | Tuning cepat |
| Penyetelan instruksi visual | Neurips | 2023 | GitHub | |
| Qwen-VL: Model bahasa penglihatan yang serba guna untuk pemahaman, lokalisasi, pembacaan teks, dan seterusnya | arxiv | 2023 | GitHub | Tuning cepat |
| Shikra: Melepaskan Sihir Dialog Referensi Multimodal LLM | arxiv | 2023 | GitHub | |
| Minigpt-4: Meningkatkan pemahaman bahasa penglihatan dengan model bahasa besar canggih | Iclr | 2023 | GitHub | Tuning cepat |
Bergantung pada target dorongan, metode yang ada dapat diklasifikasikan ke dalam tiga kategori: mendorong encoder teks , mendorong encoder visual , atau bersama -sama mendorong kedua cabang seperti yang ditunjukkan pada Gambar. 2. Pendekatan-pendekatan ini bertujuan untuk meningkatkan fleksibilitas dan kinerja VLMS khusus tugas.
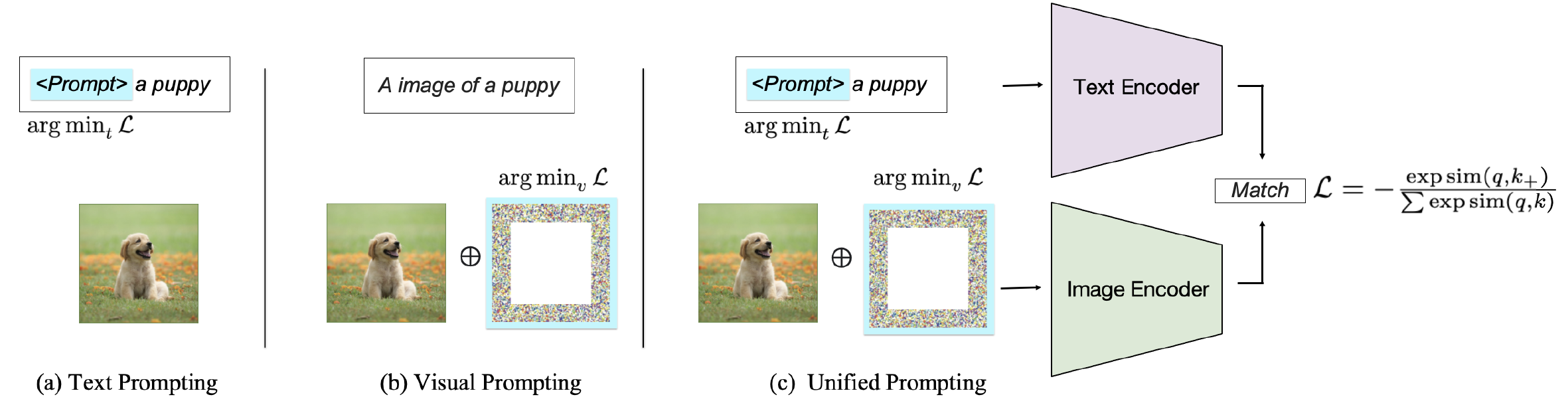
Gbr. 2: Klasifikasi Metode Meminta pada VLM yang cocok dengan gambar-teks.
| Judul | Lokasi | Tahun | Kode jika tersedia | Komentar |
|---|---|---|---|---|
| Belajar model visual yang dapat ditransfer dari pengawasan bahasa alami | ICML | 2021 | GitHub | Permintaan teks keras; Meminta klasifikasi gambar |
| Menggali keterbukaan klip | ACL | 2023 | GitHub | Teks keras meminta untuk memahami |
| Test-time prompt tuning untuk generalisasi nol-shot dalam model penglihatan-bahasa | Neurips | 2022 | GitHub | Permintaan teks lunak |
| Belajar Minta Model Bahasa Visi | Ijcv | 2022 | GitHub | Permintaan teks lunak |
| Minta model bahasa visual untuk pemahaman video yang efisien | ECCV | 2022 | GitHub | Permintaan teks lunak |
| Tuning Prompt Bahasa Visi Multitask | WACV | 2024 | GitHub | Permintaan teks lunak |
| Pembelajaran cepat bersyarat untuk model penglihatan-bahasa | CVPR | 2022 | GitHub | Permintaan teks lunak |
| Tuning prompt visual | ECCV | 2022 | GitHub | Permintaan visual-bijaksana |
| Menjelajahi permintaan visual untuk mengadaptasi model skala besar | arxiv | 2022 | GitHub | Permintaan visual-bijaksana |
| Tuning Prompt Bahasa Visi Multitask | WACV | 2024 | GitHub | Permintaan visual-bijaksana |
| Melepaskan Kekuatan Perkumpulan Visual di Level Pixel | Tmlr | 2024 | GitHub | Permintaan visual-bijaksana |
| Keanekaragaman Meta Visual yang Sehat | CVPR | 2023 | GitHub | Permintaan visual-bijaksana |
| CPT: Tuning Prompt Berwarna-warni untuk Model Bahasa Penglihatan Pra-Terlatih | Ai terbuka | 2024 | GitHub | Permintaan anotasi visual |
| Apa yang diketahui klip tentang lingkaran merah? Visual Prompt Engineering untuk VLMS | Iccv | 2023 | --- | Permintaan anotasi visual |
| Dorongan visual melalui inpainting gambar | Neurips | 2022 | GitHub | Permintaan anotasi visual |
| Visi terpadu dan bahasa yang cepat belajar | arxiv | 2023 | GitHub | Ditambah dorongan terpadu |
| Tuning Prompt Bahasa Visi Multitask | WACV | 2024 | GitHub | Dorongan terpencil terpadu |
| Maple: Pembelajaran Prompt Multi-Modal | CVPR | 2023 | GitHub | Dorongan terpencil terpadu |
| Memahami kekokohan permusuhan zero-shot untuk model skala besar | Iclr | 2023 | Kode | Ketahanan Perselisihan dari Prompt |
| Dorongan visual untuk kekokohan yang bermusuhan | Icassp | 2023 | GitHub | Ketahanan Perselisihan dari Prompt |
| Sejajarkan sebelum sekering: Visi dan representasi bahasa belajar dengan distilasi momentum | Neurips | 2021 | GitHub | Model pencocokan teks-teks |
| Pembelajaran cepat tanpa pengawasan untuk model penglihatan-bahasa | arxiv | 2022 | GitHub | Permintaan yang tidak dapat dipelajari tanpa ketentuan |
| Test-time prompt tuning untuk generalisasi nol-shot dalam model penglihatan-bahasa | Neurips | 2022 | GitHub | Prompt yang dapat dipelajari |
| Prompt pra-pelatihan dengan lebih dari dua puluh ribu kelas untuk pengakuan visual vokabulary terbuka | Neurips | 2023 | GitHub | Prepat pra-pelatihan |
| Pembelajaran cepat yang dipandu konsistensi untuk model visi-bahasa | Iclr | 2024 | --- | Dorongan terpencil terpadu |
| Meningkatkan kemampuan beradaptasi dan generalisasi pembelajaran transfer yang efisien untuk model penglihatan-bahasa | ACL ARR | 2024 | --- | Prompt yang dapat dipelajari |
| Judul | Lokasi | Tahun | Kode jika tersedia | Komentar |
|---|---|---|---|---|
| LMPT: Penyetelan cepat dengan kehilangan embedding khusus kelas untuk pengenalan visual multi-label berlabel panjang | Alvr | 2024 | GitHub | Meminta klasifikasi gambar multi-label ekor panjang |
| Test-time prompt tuning untuk generalisasi nol-shot dalam model penglihatan-bahasa | Neurips | 2022 | GitHub | Prompt yang dapat dipelajari; Meminta klasifikasi gambar |
| LPT: penyetelan cepat ekor panjang untuk klasifikasi gambar | Iclr | 2023 | GitHub | Meminta klasifikasi gambar ekor panjang |
| Teks sebagai gambar dalam penyetelan cepat untuk pengenalan gambar multi-label | CVPR | 2023 | GitHub | Meminta klasifikasi dan deteksi gambar multi-label |
| DualCoop: Adaptasi cepat ke pengakuan multi-label dengan anotasi terbatas | Neurips | 2022 | GitHub | Meminta klasifikasi dan pengakuan gambar multi-label |
| Tuning prompt visual untuk klasifikasi teks beberapa shot | ICCL | 2022 | --- | Prompt visual untuk klasifikasi teks |
| Deteksi Objek Vokabulary Terbuka Melalui Penglihatan dan Distilasi Pengetahuan Bahasa | Iclr | 2021 | GitHub | Meminta untuk deteksi objek |
| Belajar Minta Deteksi Objek Open-Vocabulary dengan model penglihatan-bahasa | CVPR | 2022 | GitHub | Meminta untuk deteksi objek |
| PromptDET: Menuju deteksi vokabulary terbuka menggunakan gambar yang tidak tertutup | ECCV | 2022 | GitHub | Meminta untuk deteksi objek |
| Mengoptimalkan dorongan kontinu untuk deteksi hubungan visual dengan imbuhan-tuning | Akses IEEE | 2022 | --- | Prompt lunak untuk deteksi hubungan visual |
| Menuju pembuatan grafik adegan vokabulary terbuka dengan finetuning berbasis prompt | ECCV | 2022 | --- | Prompt lunak untuk deteksi hubungan visual |
| Penyetelan prompt komposisi dengan isyarat gerak untuk deteksi hubungan video vokabulary terbuka | Iclr | 2023 | GitHub | Relasi meminta untuk deteksi hubungan vokabulary terbuka |
| Denseclip: prediksi padat yang dipandu bahasa dengan dorongan sadar konteks | CVPR | 2022 | GitHub | Teks yang dikondisikan kelas meminta segmentasi semantik |
| Segmen apapun | Iccv | 2023 | GitHub | Pertanyaan yang segera untuk segmentasi semantik |
| Adaptasi domain melalui pembelajaran yang cepat | IEEE | 2023 | GitHub | Perkumpulan tekstual khusus domain untuk adaptasi domain |
| Tuning prompt visual untuk adaptasi domain test-time | arxiv | 2022 | --- | Meminta adaptasi domain |
| Belajar meminta pembelajaran terus -menerus | CVPR | 2022 | GitHub | Meminta pembelajaran terus -menerus |
| DualPrompt: Complementary Foreding untuk belajar terus-menerus bebas latihan | ECCV | 2022 | GitHub | Meminta pembelajaran terus -menerus |
| Transformator visi cepat untuk generalisasi domain | arxiv | 2022 | GitHub | Minta Generalisasi Domain |
| Memahami kekokohan permusuhan zero-shot untuk model skala besar | Lclr | 2022 | GitHub | Penyetelan prompt visual di bawah serangan musuh |
| Dorongan visual untuk kekokohan yang bermusuhan | Icassp | 2023 | GitHub | Dorongan visual untuk meningkatkan ketahanan permusuhan |
| Menjelajahi kerentanan universal paradigma pembelajaran berbasis prompt | Naacl | 2022 | GitHub | Visual mendorong kerentanan |
| Keracunan dan pembelajaran kontrasik belakang | Iclr | 2022 | --- | Serangan backdoor dan keracunan pada klip |
| Badencoder: Serangan Backdoor ke Encoder Pra-Terlatih dalam Pembelajaran Penuh Diri | IEEE | 2022 | GitHub | Serangan backdoor pada klip |
| Cleanclip: Mitigasi Data Keracunan Serangan dalam Pembelajaran Kontras Multimodal | Lokakarya ICLR | 2023 | --- | Serangan backdoor pertahanan pada klip |
| Debiasing Model Visi-Bahasa melalui Perkejutaan Bias | arxiv | 2023 | GitHub | Meminta untuk meringankan bias |
| Judul | Lokasi | Tahun | Kode jika tersedia | Komentar |
|---|---|---|---|---|
| Model difusi mengalahkan GAN pada sintesis gambar | Neurips | 2021 | GitHub | Model Difusi pada Pembuatan Gambar |
| Model difusi mengalahkan GAN pada sintesis gambar | Neurips | 2021 | GitHub | Model Difusi pada Pembuatan Gambar |
| Model probabilistik difusi denoising | Neurips | 2020 | GitHub | Model Difusi pada Pembuatan Gambar |
| SUS-X: Transfer nama-hanya nama-bebas dari model penglihatan-penglihatan | Iccv | 2023 | GitHub | Model Difusi pada Pembuatan Gambar |
| Menyelidiki rekayasa cepat dalam model difusi | Lokakarya Neurips | 2022 | --- | Desain Prompt Semantik |
| Diffumask: Sintesis gambar dengan anotasi tingkat piksel untuk segmentasi semantik menggunakan model difusi | IEEE/CVF | 2023 | GitHub | Diversifikasi generasi dengan prompt; Meminta untuk pembuatan data sintetis |
| Apakah data sintetis dari model generatif siap untuk pengenalan gambar? | Iclr | 2023 | GitHub | Diversifikasi generasi dengan prompt |
| Gambar bernilai satu kata: Personalisasi pembuatan teks-ke-gambar menggunakan inversi tekstual | Iclr | 2023 | GitHub | Kontrol kompleks hasil sintesis melalui petunjuk |
| DreamBooth: Model difusi teks-ke-gambar yang menyempurnakan untuk generasi yang didorong oleh subjek | CVPR | 2023 | GitHub | Kontrol kompleks hasil sintesis melalui petunjuk |
| Kustomisasi multi-konsep difusi teks-ke-gambar | CVPR | 2023 | GitHub | Kontrol kompleks hasil sintesis melalui petunjuk |
| Pengeditan gambar yang cepat untuk dipromptikan dengan kontrol perhatian silang | Iclr | 2023 | --- | Kontrol kompleks hasil sintesis melalui petunjuk |
| Panduan difusi terstruktur bebas pelatihan untuk sintesis teks-ke-gambar komposisi | Iclr | 2023 | GitHub | Pembuatan teks-ke-gambar yang dapat dikendalikan |
| Difusi penindasan diri untuk pembuatan gambar yang dapat dikendalikan | Neurips | 2023 | Halaman | Pembuatan teks-ke-gambar yang dapat dikendalikan |
| Imagic: Pengeditan gambar nyata berbasis teks dengan model difusi | CVPR | 2023 | GitHub | Pembuatan teks-ke-gambar yang dapat dikendalikan |
| Menambahkan kontrol bersyarat ke model difusi teks-ke-gambar | IEEE/CVF | 2023 | GitHub | Pembuatan teks-ke-gambar yang dapat dikendalikan |
| Pengeditan gambar yang cepat untuk dipromptikan dengan kontrol perhatian silang | Iclr | 2023 | GitHub | Kontrol kompleks hasil sintesis melalui petunjuk |
| ImaginaryNet: Detektor Objek Belajar tanpa gambar dan anotasi nyata | Iclr | 2023 | GitHub | Meminta untuk pembuatan data sintetis |
| Apakah data sintetis dari model generatif siap untuk pengenalan gambar? | Iclr | 2023 | GitHub | Meminta untuk pembuatan data sintetis |
| Make-A-Video: Pembuatan teks-ke-video tanpa data teks-video | Iclr | 2023 | Halaman | Meminta untuk generasi teks-ke-video |
| Video Imagen: Pembuatan video definisi tinggi dengan model difusi | arxiv | 2022 | Halaman | Meminta untuk generasi teks-ke-video |
| Fatezero: Perhatian sekering untuk pengeditan video berbasis teks nol-shot | Iccv | 2023 | GitHub | Meminta untuk generasi teks-ke-video |
| Tune-A-Video: Tuning One-Shot dari Model Difusi Gambar untuk Pembuatan Teks-ke-Video | Iccv | 2023 | GitHub | Meminta untuk generasi teks-ke-video |
| Difrf: difusi bidang pancaran 3D yang dipandu rendering | CVPR | 2023 | Halaman | Meminta untuk generasi teks-ke-3d |
| DreamFusion: Text-to-3d Menggunakan Difusi 2D | Iclr terkenal 5% teratas | 2023 | Halaman | Meminta untuk generasi teks-ke-3d |
| Dream3D: Sintesis Teks-ke-3D Zero-Shot Menggunakan Model Difusi Prior dan Teks-ke-Teks | CVPR | 2023 | Halaman | Meminta untuk generasi teks-ke-3d |
| MotionDiffuse: Generasi gerak manusia yang digerakkan oleh teks dengan model difusi | IEEE | 2024 | Halaman | Meminta untuk pembuatan teks-ke-gerak |
| Api: Sintesis & Pengeditan Berbasis Bahasa Bahasa Gratis | Aaai | 2023 | GitHub | Meminta untuk pembuatan teks-ke-gerak |
| MDM: Model Difusi Gerakan Manusia | Iclr | 2023 | GitHub | Meminta untuk pembuatan teks-ke-gerak |
| Generasi buku cerita koheren zero-shot dari cerita teks biasa menggunakan model difusi | arxiv | 2023 | --- | Meminta tugas yang rumit |
| Perencanaan Prosedural Multimodal Melalui Dual Teks-Image Diminta | Iclr | 2024 | GitHub | Meminta tugas yang rumit |
| Segera mencuri serangan terhadap model generasi teks-ke-gambar | Simposium Keamanan Usenix | 2023 | --- | Meminta AI yang bertanggung jawab |
| Serangan inferensi keanggotaan terhadap model generasi teks-ke-gambar | Iclr | 2023 | --- | Serangan keanggotaan terhadap model teks-ke-gambar |
| Apakah model difusi rentan terhadap serangan inferensi keanggotaan? | ICML | 2023 | GitHub | Serangan keanggotaan terhadap model teks-ke-gambar |
| Ekstraksi yang dapat direproduksi dari gambar pelatihan dari model difusi | arxiv | 2023 | GitHub | Serangan keanggotaan terhadap model teks-ke-gambar |
| Difusi wajar: Menginstruksikan model pembuatan teks-ke-gambar tentang keadilan | arxiv | 2023 | GitHub | Meminta pada model teks-ke-gambar yang mempertimbangkan keadilan |
| Bias sosial melalui lensa generasi teks-ke-gambar | AAAI/ACM | 2023 | --- | Meminta pada model teks-ke-gambar yang mempertimbangkan bias |
| T2IAT: Mengukur valensi dan bias stereotip dalam pembuatan teks-ke-gambar | ACL | 2023 | --- | Meminta pada model teks-ke-gambar yang mempertimbangkan bias |
| Bias yang stabil: Menganalisis representasi sosial dalam model difusi | Neurips | 2023 | --- | Meminta pada model teks-ke-gambar yang mempertimbangkan bias |
| Studi percontohan serangan permusuhan bebas kueri terhadap difusi yang stabil | CVPR | 2023 | --- | Ketahanan Model Teks-ke-Gambar |
| Model difusi untuk serangan permusuhan yang tidak terlihat dan dapat ditransfer | Iclr | 2024 | GitHub | Ketahanan Model Teks-ke-Gambar |
| Model difusi untuk pemurnian permusuhan | ICML | 2022 | GitHub | Ketahanan Model Teks-ke-Gambar |
| Rickrolling The Artist: Menyuntikkan backdoors ke dalam encoder teks untuk sintesis teks-ke-gambar | Iccv | 2023 | --- | Serangan backdoor pada model teks-ke-gambar |
| Model difusi teks-ke-gambar dapat dengan mudah diputar ulang melalui keracunan data multimodal | ACM MM | 2023 | --- | Serangan backdoor pada model teks-ke-gambar |
| Personalisasi sebagai jalan pintas untuk serangan backdoor beberapa tembakan terhadap model difusi teks-ke-gambar | Aaai | 2024 | --- | Serangan backdoor pada model teks-ke-gambar |
Silakan hubungi kami ([email protected], [email protected]) jika


