Awesome Prompting on Vision Language Model
1.0.0
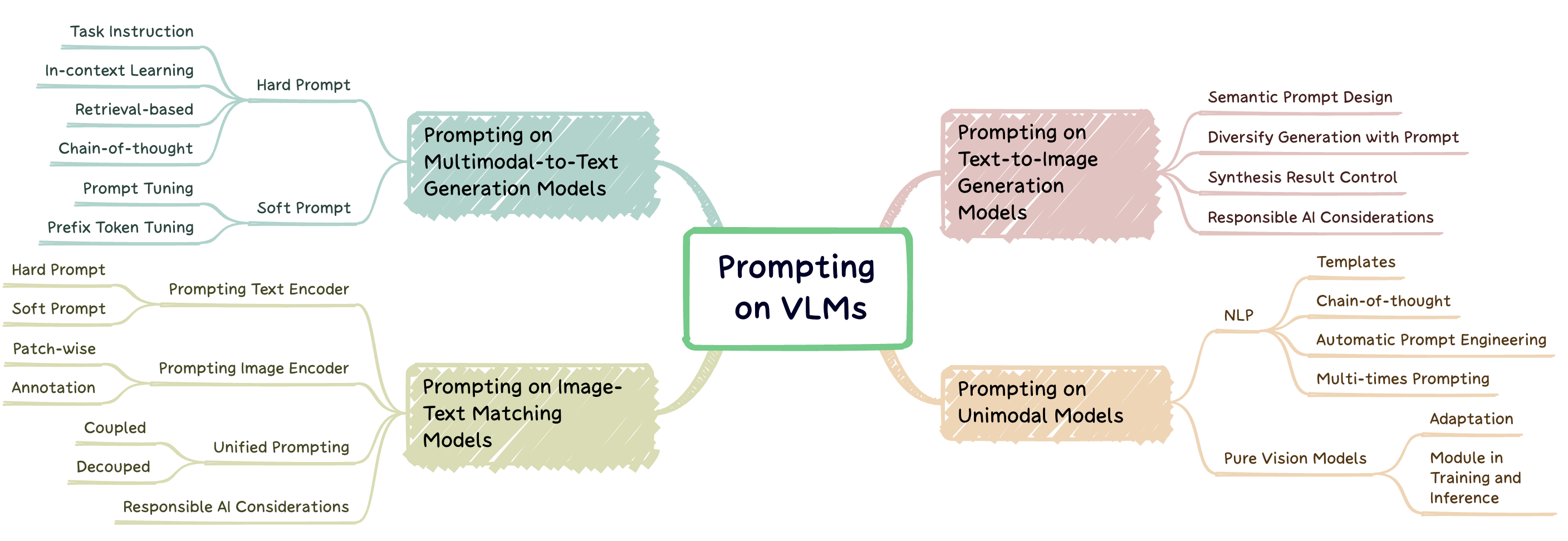
Proform Engineering ist eine Technik, bei der ein großes vorgebildetes Modell mit aufgabenspezifischen Hinweisen erweitert wird, die als Eingabeaufforderungen bezeichnet werden, um das Modell an neue Aufgaben anzupassen. Dieses Repo zielt darauf ab, eine umfassende Übersicht über die modernste Forschung in der schnellen Technik auf drei Arten von Sehvermögensmodellen (VLMs) zu erstellen: multimodale Modelle zu Textgenerierung ( z . B. Flamingo), Bildtext-Matching-Modelle ( z . B. Clip) und Modelle für die Generierung von Text-zu-Images ( z . B. stabile Diffusion) (Abb. 1).
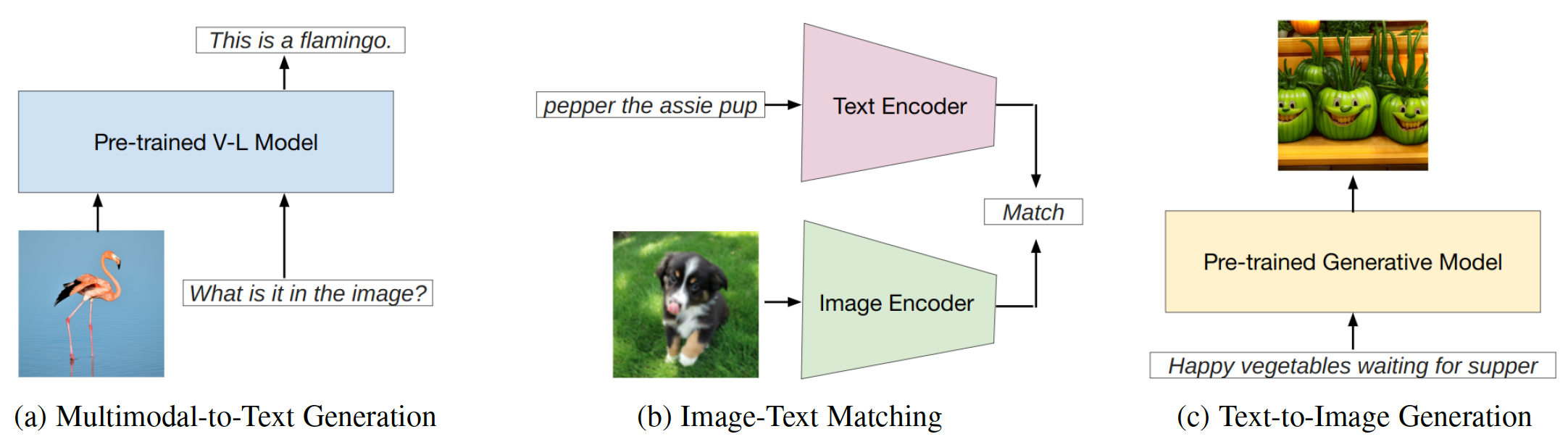
Abb. 1: Diese Arbeit konzentriert sich auf drei Haupttypen von Visionsprachenmodellen.
Dieses Repo listet relevante Artikel auf, die in unserer Umfrage zusammengefasst sind:
Eine systematische Übersicht über die modelle Technik der Vision-Sprachen-Fundamentmodelle. Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan HE, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Torr . Preprint 2023. [PDF]
Wenn Sie unser Papier und unser Repo für Ihre Recherche hilfreich finden, zitieren Sie bitte das folgende Papier:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}Aufforderung zum Modell in der multimodalen bis zur Textgenerierung
Aufmerksamkeit des Modells in Bild-Text-Matching
Aufforderung an das Modell in der Text-zu-Image-Generierung
Es gibt zwei Haupttypen von Fusionsmodul-Ansätzen, die auf der Integration von visuellen und textuellen Modalitäten basieren: Encoder-Decoder als multimodales Fusionsmodul und Decodierer nur als multimodales Fusionsmodul . Auf basierende Methoden können in zwei Hauptkategorien unterteilt werden (Abb. 2) basierend auf der Lesbarkeit der Vorlagen: harte Eingabeaufforderung und weiche Eingabeaufforderung . Harte Eingabeaufforderung umfasst vier Unterkategorien: Aufgabenanweisung, Kontextlernen, Abrufbasiertes Aufforderung und Aufmerksamkeit der Kette . Soft -Eingabeaufforderungen werden in zwei Strategien eingeteilt: sofortige Stimmen und Präfix -Token -Tuning , basierend darauf, ob sie der Architektur des Modells intern neue Token hinzufügen oder sie einfach an die Eingabe anhängen. Diese Studie konzentriert sich hauptsächlich auf Schnellmethoden, die vermeiden, das Basismodell zu verändern.
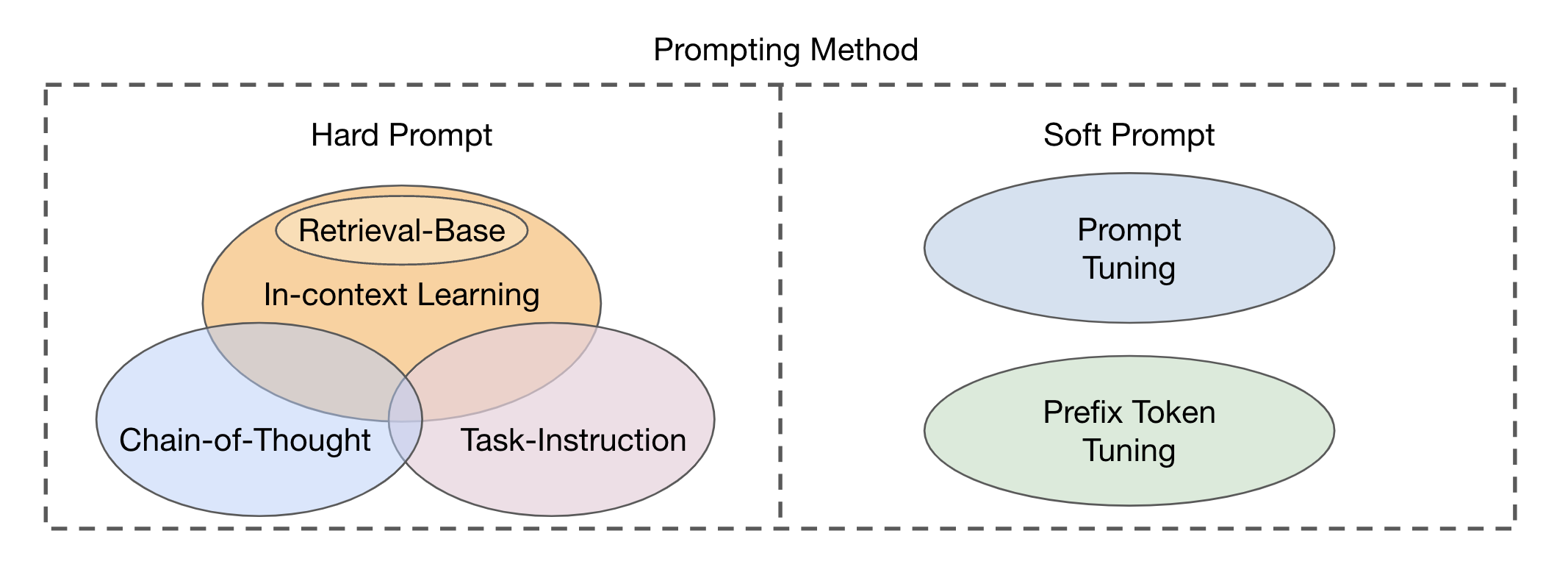
Abb. 2: Klassifizierung von Anlaufmethoden.
| Titel | Veranstaltungsort | Jahr | Code, falls verfügbar | Kommentar |
|---|---|---|---|---|
| Vereinigung von Vision- und Sprachaufgaben über die Textgenerierung | ICML | 2021 | Github | Encoder-Decoder-Fusion; Textpräfixe als Eingabeaufforderung |
| SIMVLM: Einfaches visuelles Sprachmodell Vorstand mit schwacher Überwachung | ICLR | 2022 | Github | Encoder-Decoder-Fusion; Textpräfixe als Eingabeaufforderung |
| OFA: Vereinheitliche Architekturen, Aufgaben und Modalitäten durch einen einfachen Lernrahmen für Sequenz zu Sequenz | ICML | 2022 | Github | Encoder-Decoder-Fusion; Textpräfixe als Eingabeaufforderung |
| Pali: Ein gemeinsamskaliertes mehrsprachiges Sprachbildmodell | ICLR | 2023 | --- | Encoder-Decoder-Fusion; Anweisung Eingabeaufforderung |
| Multimodales Lernen mit wenigen Scheinen mit gefrorenen Sprachmodellen | Neurips | 2021 | Seite | Decoder-Nur-Fusion; Bildbedingter Präfix -Tuning |
| Flamingo: Ein visuelles Sprachmodell für wenige Schüsse-Lernen | Neurips | 2022 | Github | Decoder-Nur-Fusion; Textaufforderungen; |
| MAGMA-Multimodale Augmentation generativer Modelle durch Adapterbasis-Basisfinetuning | EMNLP | 2022 | Github | Decoder-Nur-Fusion; Bildbedingter Präfix -Tuning |
| BLIP-2: Bootstrapping-Sprachbild vor der Ausbildung mit gefrorenen Bildcodierern und großen Sprachmodellen | ICML | 2023 | Github | Decoder-Nur-Fusion; Bildbedingter Präfix -Tuning |
| Sprachmodelle sind unbeaufsichtigte Multitasking -Lernende | OpenAI -Blog | 2019 | Github | Aufgabenanweisung Eingabeaufforderung |
| Der Turking -Test: Können Sprachmodelle Anweisungen verstehen? | Arxiv | 2020 | --- | Aufgabenanweisung Eingabeaufforderung |
| Sprachmodelle sind nur wenige Schusslerner | Neurips | 2020 | --- | In-Kontext-Lernen |
| Lernen, Eingabeaufforderungen für das Lernen des Kontextes abzurufen | NAACl-HLT | 2022 | Github | Abrufbasierte Aufforderung |
| Einheitliche Demonstration Retriever für das Lernen in Kontext | ACL | 2023 | Github | Abrufbasierte Aufforderung |
| Kompositionelle Exemplare für das Lernen in Kontext | ICML | 2023 | Github | Abrufbasierte Aufforderung |
| Die Aufforderung zur Kette der Gedanken liefert Argumentation in Großsprachenmodellen aus | Neurips | 2022 | --- | Aufforderung zur Kette der Gedanken |
| Automatische Denkkette, die in großen Sprachmodellen auffordert | ICLR | 2023 | Github | Aufforderung zur Kette der Gedanken |
| Die Skalierungsleistung für parametereffizientes Einort-Tuning | EMNLP | 2021 | --- | Sofortiges Tuning |
| Lernen, wie man fragt: LMS mit Mischungen aus weichen Eingabeaufforderungen abfragen | NAACl-HLT | 2021 | Github | Sofortiges Tuning |
| Präfixabbau: Optimieren Sie kontinuierliche Eingabeaufforderungen für die Generation | ACL | 2021 | Github | Präfixabstimmung |
| Sofortig | ACL | 2023 | Github | Sofortiges Einstellen auf OFA |
| Sprache ist nicht alles was Sie brauchen: Wahrnehmung mit Sprachmodellen ausrichten | Neurips | 2023 | Github | Textanweisungen Eingabeaufforderungen |
| Benchmarking Robustheit von Anpassungsmethoden auf vorgeborenen Visionsprachenmodellen | Neurips | 2024 | Seite | Robustheit des sofortigen Stimmens auf VLMs |
| Auf dem Weg zu robusten Aufforderungen auf Visionsprachmodelle | NextGenaisafety@ICLR | 2024 | --- | Robustheit des sofortigen Stimmens auf VLMs |
| InstructBlip: In Richtung allgemeiner Visionsprachgutmodelle mit Anweisungsabstimmung | Neurips | 2023 | Github | Sofortiges Tuning |
| Visuelle Anweisungsstimmung | Neurips | 2023 | Github | |
| QWEN-VL: Ein vielseitiges visuelles Modell zum Verständnis, Lokalisierung, Textlesen und darüber hinaus | Arxiv | 2023 | Github | Sofortiges Tuning |
| Shikra: Multimodal LLMs referenzielles Dialogmagie entfesseln | Arxiv | 2023 | Github | |
| MiniGPT-4: Verbesserung des Verständnisses der Visionsprachen mit fortgeschrittenen Großsprachmodellen | ICLR | 2023 | Github | Sofortiges Tuning |
Abhängig vom Ziel der Aufforderung können vorhandene Methoden in drei Kategorien eingeteilt werden: Aufforderung zum Textcodierer , die Aufforderung zum visuellen Encoder oder die gemeinsame Aufforderung an beide Zweige, wie in Abb. 2 gezeigt. Diese Ansätze zielen darauf ab, die Flexibilität und aufgabenspezifische Leistung von VLMs zu verbessern.
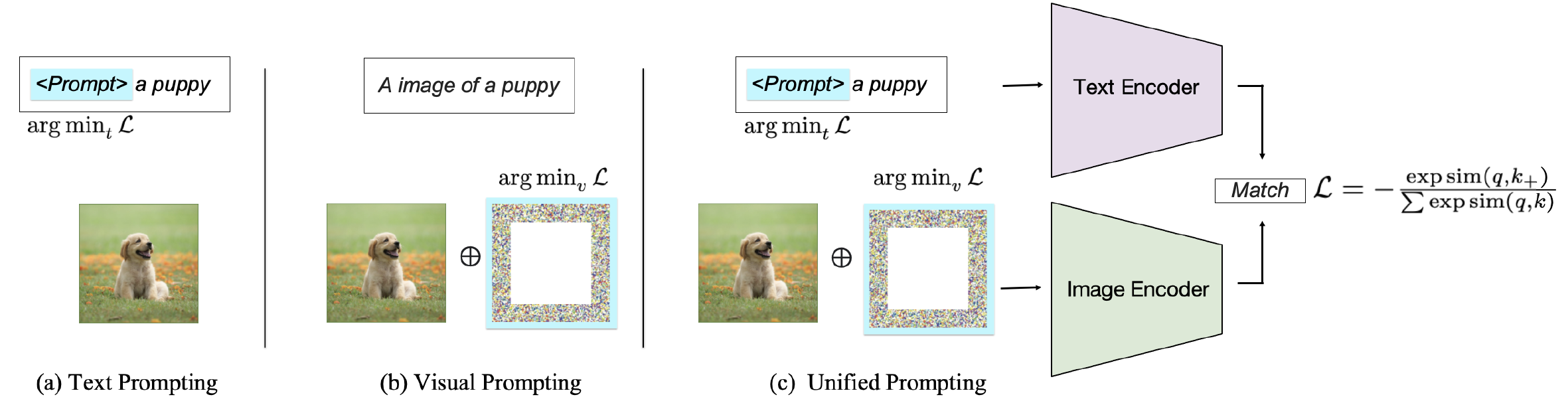
Abb. 2: Klassifizierung von Anlaufmethoden auf dem Bild-Text-Matching-VLMs.
| Titel | Veranstaltungsort | Jahr | Code, falls verfügbar | Kommentar |
|---|---|---|---|---|
| Lernen übertragbarer visueller Modelle aus natürlicher Sprache Überwachung | ICML | 2021 | Github | Harte Textaufforderungen; Aufforderung zur Bildklassifizierung |
| In die Offenheit des Clips eintauchen | ACL | 2023 | Github | Harte Textaufforderungen zum Verständnis |
| Tester-Zeit-Eingabeaufforderung für die Verallgemeinerung von Null-Shot in Visionsprachenmodellen | Neurips | 2022 | Github | Weiche Textaufforderungen |
| Lernen, um sehverwöhnliche Modelle aufzufordern | Ijcv | 2022 | Github | Weiche Textaufforderungen |
| Auffordern visuellsprachiger Modelle für ein effizientes Videoverständnis | ECCV | 2022 | Github | Weiche Textaufforderungen |
| Multitasking Vision-Sprache, sofortiges Tuning | WACV | 2024 | Github | Weiche Textaufforderungen |
| Bedingte schnelle Lernen für Visionsprachel-Modelle | CVPR | 2022 | Github | Weiche Textaufforderungen |
| Visuelle Eingabeaufforderung | ECCV | 2022 | Github | Visuelle Patch-Hinweis auf Eingabeaufforderungen |
| Erforschung visueller Eingabeaufforderungen zur Anpassung groß angelegter Modelle | Arxiv | 2022 | Github | Visuelle Patch-Hinweis auf Eingabeaufforderungen |
| Multitasking Vision-Sprache, sofortiges Tuning | WACV | 2024 | Github | Visuelle Patch-Hinweis auf Eingabeaufforderungen |
| Entfesseln Sie die Kraft der visuellen Aufforderung auf Pixelebene | Tmlr | 2024 | Github | Visuelle Patch-Hinweis auf Eingabeaufforderungen |
| Diversity-bekanntes Meta-visueller Aufforderung | CVPR | 2023 | Github | Visuelle Patch-Hinweis auf Eingabeaufforderungen |
| Cpt | Ai offen | 2024 | Github | Visuelle Annotation Aufforderungen |
| Was weiß Clip über einen roten Kreis? Visuelle Eingabeaufforderung Engineering für VLMs | ICCV | 2023 | --- | Visuelle Annotation Aufforderungen |
| Visuelle Aufforderung über Bildeinbacken | Neurips | 2022 | Github | Visuelle Annotation Aufforderungen |
| Einheitliche Vision und Sprache schnelles Lernen | Arxiv | 2023 | Github | Gekoppelte einheitliche Aufforderung |
| Multitasking Vision-Sprache, sofortiges Tuning | WACV | 2024 | Github | Entkoppelte einheitliche Aufforderung |
| Maple: Multi-Modal-promptes Lernen | CVPR | 2023 | Github | Entkoppelte einheitliche Aufforderung |
| Verständnis von Null-Shot-kontroverse Robustheit für groß angelegte Modelle | ICLR | 2023 | Code | Kontroverse Robustheit der schnellen |
| Visuelle Aufforderung zur kontroversen Robustheit | ICASSP | 2023 | Github | Kontroverse Robustheit der schnellen |
| Ausrichten vor der Sicherung: Vision und Sprachrepräsentation Lernen mit Distillation Destillation | Neurips | 2021 | Github | Bild-Text-Matching-Modell |
| Unbeaufsichtigtes sofortiges Lernen für Visionsprachenmodelle | Arxiv | 2022 | Github | Unbeschwerte lernbare Eingabeaufforderungen |
| Tester-Zeit-Eingabeaufforderung für die Verallgemeinerung von Null-Shot in Visionsprachenmodellen | Neurips | 2022 | Github | Lernbare Eingabeaufforderung |
| Eingehend vor der Ausbildung mit über zwanztausend Klassen für die visuelle Erkennung von offenem Vokabular | Neurips | 2023 | Github | Sofortige Vorabbildung |
| Konsistenzgesteuerte schnelle Lernen für Visionsprachenmodelle | ICLR | 2024 | --- | Entkoppelte einheitliche Aufforderung |
| Verbesserung der Anpassungsfähigkeit und Generalisierbarkeit des effizienten Transferlernens für Visionsprachel-Modelle | ACL arr | 2024 | --- | Lernbare Eingabeaufforderung |
| Titel | Veranstaltungsort | Jahr | Code, falls verfügbar | Kommentar |
|---|---|---|---|---|
| LMPT: Sofortige Stimmung mit klassenspezifischer Einbettungsverlust für Langzeitmulti-Label-visuelle Erkennung | Alvr | 2024 | Github | Eingabeaufforderungen für eine langschwanzige Multi-Label-Bildklassifizierung |
| Tester-Zeit-Eingabeaufforderung für die Verallgemeinerung von Null-Shot in Visionsprachenmodellen | Neurips | 2022 | Github | Lernbare Eingabeaufforderung; Eingabeaufforderungen für die Bildklassifizierung |
| LPT: Langschwanz schnelles Tuning für die Bildklassifizierung | ICLR | 2023 | Github | Eingabeaufforderungen für eine langschwanzige Bildklassifizierung |
| Texte als Bilder im schnellen Tuning für die Multi-Label-Bilderkennung | CVPR | 2023 | Github | Eingabeaufforderungen für die Klassifizierung und Erkennung von Multi-Label-Bild |
| DualCoop: Schnelle Anpassung an Multi-Label-Erkennung mit begrenzten Annotationen | Neurips | 2022 | Github | Eingabeaufforderungen für die Klassifizierung und Erkennung von Multi-Label-Bild |
| Visuelle Eingabeaufforderung für eine wenige Schuss-Textklassifizierung | ICCL | 2022 | --- | Visuelle Eingabeaufforderungen für die Textklassifizierung |
| Erkennung von Open-Vocabulary-Objekten durch Seh- und Sprachwissendestillation | ICLR | 2021 | Github | Aufforderungen zur Objekterkennung |
| Lernen, die Erkennung von Open-Vocabulary-Objekten mit Visionsprachemodell zu fordern | CVPR | 2022 | Github | Aufforderungen zur Objekterkennung |
| Eingabeaufforderung: In Richtung Open-Vocabulary-Erkennung unter Verwendung ungeschlossener Bilder | ECCV | 2022 | Github | Aufforderungen zur Objekterkennung |
| Optimieren Sie kontinuierliche Eingabeaufforderungen für die Erkennung visueller Beziehungen durch Affix-Tuning | IEEE -Zugang | 2022 | --- | Weiche Eingabeaufforderungen für die Erkennung visueller Beziehung |
| In Richtung Open-Vocabular-Szenendiagrammgenerierung mit prompt-basierten Flossen | ECCV | 2022 | --- | Weiche Eingabeaufforderungen für die Erkennung visueller Beziehung |
| Kompositionelle Einstellung mit Bewegungshinweise für die Erkennung von Videobeziehungen mit offenem Vokabular | ICLR | 2023 | Github | Beziehungsaufforderungen für Video Open-Vocabularary-Relationserkennung |
| Denseclip: Sprachgeführte dichte Vorhersage mit kontextbewusster Aufforderung | CVPR | 2022 | Github | Klassenkonditionierte Textaufforderungen für die semantische Segmentierung |
| Irgendetwas segmentieren | ICCV | 2023 | Github | Prunkbare Abfragen zur semantischen Segmentierung |
| Domänenanpassung durch schnelles Lernen | IEEE | 2023 | Github | Domänenspezifische Textaufforderungen für die Domänenanpassung |
| Visuelle Eingabeaufforderung für die Tester-Zeit-Domänenanpassung | Arxiv | 2022 | --- | Eingabeaufforderungen für die Domänenanpassung |
| Lernen, ein kontinuierliches Lernen zu veranlassen | CVPR | 2022 | Github | Aufforderungen für kontinuierliches Lernen |
| DualPrompt: Komplementäre Aufforderung zum probenfreien kontinuierlichen Lernen | ECCV | 2022 | Github | Aufforderungen für kontinuierliches Lernen |
| Promptes Sehtransformator für die Domänenverallgemeinerung | Arxiv | 2022 | Github | Aufforderungen für die Verallgemeinerung der Domänen |
| Verständnis von Null-Shot-kontroverse Robustheit für groß angelegte Modelle | Lclr | 2022 | Github | Visuelle sofortige Stimmung unter kontroversem Angriff |
| Visuelle Aufforderung zur kontroversen Robustheit | ICASSP | 2023 | Github | Visuelle Aufforderung zur Verbesserung der kontroversen Robustheit |
| Erforschung der universellen Anfälligkeit von prompt-basierten Lernparadigma | Naacl | 2022 | Github | Visuelle Anfälligkeit |
| Vergiftung und Hintermännung kontrastives Lernen | ICLR | 2022 | --- | Hintertür- und Vergiftungsangriffe auf Clip |
| Badencoder: Backdoor-Angriffe auf vorgebildete Encoder im selbstverständlichen Lernen | IEEE | 2022 | Github | Backdoor -Angriff auf Clip |
| Cleanclip: Minderung von Datenvergiftungsangriffen beim multimodalen kontrastiven Lernen | ICLR -Workshop | 2023 | --- | Verteidigung Backdoor -Angriffe auf Clip |
| Debiasing Vision-sprachliche Modelle über voreingenommene Eingabeaufforderungen | Arxiv | 2023 | Github | Aufforderung zur Linderung der Verzerrung |
| Titel | Veranstaltungsort | Jahr | Code, falls verfügbar | Kommentar |
|---|---|---|---|---|
| Diffusionsmodelle schlagen Gans zur Bildsynthese | Neurips | 2021 | Github | Diffusionsmodelle zur Bilderzeugung |
| Diffusionsmodelle schlagen Gans zur Bildsynthese | Neurips | 2021 | Github | Diffusionsmodelle zur Bilderzeugung |
| Denoising diffusion probabilistische Modelle | Neurips | 2020 | Github | Diffusionsmodelle zur Bilderzeugung |
| SUS-X: Nur trainierungsfreie Namensübertragung von Visionsprachenmodellen | ICCV | 2023 | Github | Diffusionsmodelle zur Bilderzeugung |
| Untersuchung der schnellen Engineering in Diffusionsmodellen | Neurips Workshop | 2022 | --- | Semantisches promptes Design |
| Diffumask: Bilder mit Annotationen auf Pixelebene zur semantischen Segmentierung unter Verwendung von Diffusionsmodellen synthetisieren | IEEE/CVF | 2023 | Github | Diversifizierung der Generation mit prompt; Aufforderungen für die Erzeugung synthetischer Daten |
| Sind synthetische Daten aus generativen Modellen zur Bilderkennung bereit? | ICLR | 2023 | Github | Diversifizierung der Generation mit prompt |
| Ein Bild ist ein Wort wert: Personalisierung der Text-zu-Image-Generation mithilfe einer Textinversion personalisieren | ICLR | 2023 | Github | Komplexe Kontrolle der Syntheseergebnisse über Eingabeaufforderungen |
| Dreambooth: Feinabstimmungsdiffusionsmodelle für die Subjektbetriebener Generation | CVPR | 2023 | Github | Komplexe Kontrolle der Syntheseergebnisse über Eingabeaufforderungen |
| Multi-Concept-Anpassung der Text-zu-Im-Im-Im-Im-Im-Im-Im-Im-Im-Im-Im-Im-Im-Immobilien-Diffusion | CVPR | 2023 | Github | Komplexe Kontrolle der Syntheseergebnisse über Eingabeaufforderungen |
| Eingabeaufforderung zur Prompt-Bildbearbeitung mit kreuzen Aufmerksamkeitskontrolle | ICLR | 2023 | --- | Komplexe Kontrolle der Syntheseergebnisse über Eingabeaufforderungen |
| Trainingsfreie strukturierte Diffusionsanleitung für die Synthese "Text-zu-Im-Im-Im-Image" für Kompositionen | ICLR | 2023 | Github | Steuerbare Text-zu-Image-Erzeugung |
| Diffusions-Selbstanwalt für die steuerbare Bilderzeugung | Neurips | 2023 | Seite | Steuerbare Text-zu-Image-Erzeugung |
| Vorstellung: textbasierte echte Bildbearbeitung mit Diffusionsmodellen | CVPR | 2023 | Github | Steuerbare Text-zu-Image-Erzeugung |
| Hinzufügen einer bedingten Steuerung zu Text-zu-Image-Diffusionsmodellen | IEEE/CVF | 2023 | Github | Steuerbare Text-zu-Image-Erzeugung |
| Eingabeaufforderung zur Prompt-Bildbearbeitung mit kreuzen Aufmerksamkeitskontrolle | ICLR | 2023 | Github | Komplexe Kontrolle der Syntheseergebnisse über Eingabeaufforderungen |
| ImaginaryNet: Lernobjektdetektoren ohne echte Bilder und Anmerkungen | ICLR | 2023 | Github | Aufforderungen für die Erzeugung synthetischer Daten |
| Sind synthetische Daten aus generativen Modellen zur Bilderkennung bereit? | ICLR | 2023 | Github | Aufforderungen für die Erzeugung synthetischer Daten |
| Make-a-video: Text-to-Video-Erzeugung ohne Text-Video-Daten | ICLR | 2023 | Seite | Eingabeaufforderungen für die Erzeugung von Text-zu-Videos |
| Imageen Video: High Definition -Videogenerierung mit Diffusionsmodellen | Arxiv | 2022 | Seite | Eingabeaufforderungen für die Erzeugung von Text-zu-Videos |
| Fatezero: Aufmerksamkeiten für die textbasierte Videobearbeitung von Zero-Shot-Basis verschmelzen | ICCV | 2023 | Github | Eingabeaufforderungen für die Erzeugung von Text-zu-Videos |
| Tune-a-video: One-Shot-Abstimmung von Bilddiffusionsmodellen für die Erzeugung von Text zu Video | ICCV | 2023 | Github | Eingabeaufforderungen für die Erzeugung von Text-zu-Videos |
| BUFFRF: Rendering-geführte 3D-Strahlungsfelddiffusion | CVPR | 2023 | Seite | Eingabeaufforderungen für die Text-zu-3D-Generation |
| Dreamfusion: Text-zu-3D mit 2D-Diffusion | ICLR bemerkenswerte Top 5% | 2023 | Seite | Eingabeaufforderungen für die Text-zu-3D-Generation |
| Dream3D: Null-Shot-Text-zu-3D | CVPR | 2023 | Seite | Eingabeaufforderungen für die Text-zu-3D-Generation |
| MotionDiffuse: textgetriebene menschliche Bewegungsgenerierung mit Diffusionsmodell | IEEE | 2024 | Seite | Eingabeaufforderungen für die Erzeugung von Text-zu-Motion |
| Flamme: Sprachbasierte Bewegungssynthese und Bearbeitung von freier Form | Aaai | 2023 | Github | Eingabeaufforderungen für die Erzeugung von Text-zu-Motion |
| MDM: menschliches Bewegungsdiffusionsmodell | ICLR | 2023 | Github | Eingabeaufforderungen für die Erzeugung von Text-zu-Motion |
| Zero-Shot-Generierung von kohärentem Storybook aus der einfachen Textgeschichte mit Diffusionsmodellen | Arxiv | 2023 | --- | Aufforderungen für komplexe Aufgaben |
| Multimodale Verfahrensplanung durch Doppeltextezeitaufforderung | ICLR | 2024 | Github | Aufforderungen für komplexe Aufgaben |
| Sofortdiebstahl von Angriffen gegen Text-zu-Image-Generierungsmodelle | Usenix Security Symposium | 2023 | --- | Aufforderungen für verantwortungsbewusste KI |
| Inferenzangriffe der Mitgliedschaft Angriffe gegen Text-zu-Image-Generierungsmodelle | ICLR | 2023 | --- | Mitgliedschaftsangriffe gegen Text-zu-Image-Modelle |
| Sind Diffusionsmodelle für Mitgliederinferenzangriffe anfällig? | ICML | 2023 | Github | Mitgliedschaftsangriffe gegen Text-zu-Image-Modelle |
| Eine reproduzierbare Extraktion von Trainingsbildern aus Diffusionsmodellen | Arxiv | 2023 | Github | Mitgliedschaftsangriffe gegen Text-zu-Image-Modelle |
| Faire Diffusion: Ermittlung von Modellen zur Erzeugung von Text-zu-Image-Erzeugung auf Fairness | Arxiv | 2023 | Github | Aufforderungen zu Text-zu-Image-Modellen, die Fairness berücksichtigen |
| Soziale Vorurteile durch das Objektiv der Text-zu-Image-Generation | AAAI/ACM | 2023 | --- | Aufforderungen zu Text-zu-Image-Modellen unter Berücksichtigung von Vorurteilen |
| T2IAT: Messung der Valenz und stereotypen Verzerrungen in der Erzeugung von Text zu Image | ACL | 2023 | --- | Aufforderungen zu Text-zu-Image-Modellen unter Berücksichtigung von Vorurteilen |
| Stabile Verzerrung: Analyse gesellschaftlicher Darstellungen in Diffusionsmodellen | Neurips | 2023 | --- | Aufforderungen zu Text-zu-Image-Modellen unter Berücksichtigung von Vorurteilen |
| Eine Pilotstudie über abfragefreie kontroverse Angriff gegen stabile Diffusion | CVPR | 2023 | --- | Gegentliche Robustheit von Text-zu-Image-Modellen |
| Diffusionsmodelle für unmerklicher und übertragbarer kontroverser Angriff | ICLR | 2024 | Github | Gegentliche Robustheit von Text-zu-Image-Modellen |
| Diffusionsmodelle für die kontroverse Reinigung | ICML | 2022 | Github | Gegentliche Robustheit von Text-zu-Image-Modellen |
| Rickrolling The Artist: Injecting Hintertoors in Text-Encoder für die Text-zu-Image-Synthese injizieren | ICCV | 2023 | --- | Backdoor-Angriff auf Text-zu-Image-Modelle |
| Text-to-Image-Diffusionsmodelle können durch multimodale Datenvergiftung leicht zurückgegriffen werden | ACM mm | 2023 | --- | Backdoor-Angriff auf Text-zu-Image-Modelle |
| Personalisierung als Verknüpfung für wenige Schuss-Backdoor-Angriffe gegen Text-zu-Image-Diffusionsmodelle | Aaai | 2024 | --- | Backdoor-Angriff auf Text-zu-Image-Modelle |
Bitte kontaktieren Sie uns ([email protected], [email protected]), wenn


