Awesome Prompting on Vision Language Model
1.0.0
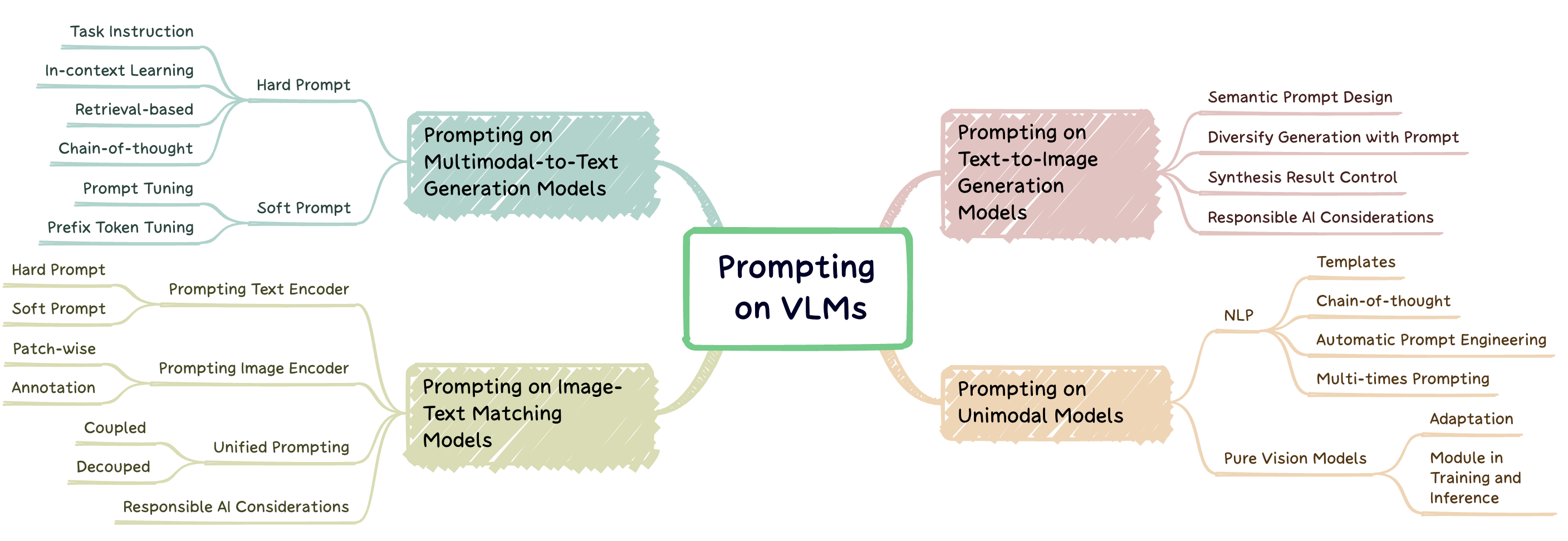
프롬프트 엔지니어링은 프롬프트라고 알려진 작업 별 힌트를 갖춘 대규모 미리 훈련 된 모델을 새로운 작업에 조정하는 기술입니다. 이 repo는 3 가지 유형의 비전 언어 모델 (VLMS)에 대한 신속한 엔지니어링에 대한 최첨단 연구에 대한 포괄적 인 조사를 제공하는 것을 목표로합니다 : 멀티 모달 대 텍스트 생성 모델 ( 예 : Flamingo), 이미지 텍스트 매칭 모델 ( 예 : 클립) 및 텍스트--이미지 생성 모델 ( 예 : 안정적인 차이) (그림 1).
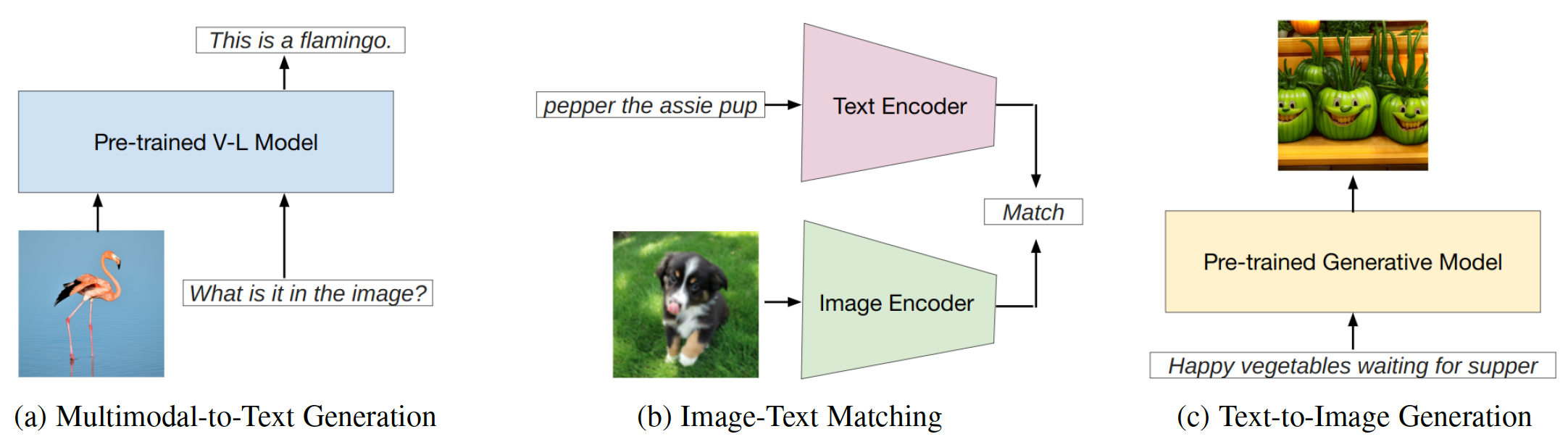
그림 1 :이 작업은 세 가지 주요 유형의 비전 언어 모델에 중점을 둡니다.
이 repo는 설문 조사에 요약 된 관련 논문을 나열합니다.
비전 언어 기초 모델에 대한 신속한 엔지니어링에 대한 체계적인 조사. Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan HE, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, Philip Torr . Preprint 2023. [PDF]
우리의 논문을 발견하고 리포지트를 연구에 도움이되면 다음 논문을 인용하십시오.
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}멀티 모달-텍스트 생성에서 모델을 제기합니다
이미지 텍스트 일치에서 모델을 제기합니다
텍스트-이미지 생성에서 모델을 제기합니다
시각적 및 텍스트 모드의 통합에 기초한 두 가지 주요 유형의 퓨전 모듈 접근법이있다 : 멀티 모달 퓨전 모듈로서의 인코더 디코더 및 다중 모달 퓨전 모듈로서의 디코더 전용 . 프롬프트 방법은 템플릿의 가독성에 따라 두 가지 주요 범주 (그림 2)로 나눌 수 있습니다 : 하드 프롬프트 및 소프트 프롬프트 . 하드 프롬프트 에는 작업 지침, 컨텍스트 내 학습, 검색 기반 프롬프트 및 사슬의 프롬프트라는 네 가지 하위 범주가 포함됩니다. 소프트 프롬프트는 두 가지 전략으로 분류됩니다. 즉 , 프롬프트 튜닝 및 접두사 토큰 튜닝은 모델의 아키텍처에 내부적으로 새로운 토큰을 추가하거나 간단히 입력에 추가되는지 여부를 기반으로합니다. 이 연구는 주로 기본 모델을 변경하지 않는 신속한 방법에 중점을 둡니다.
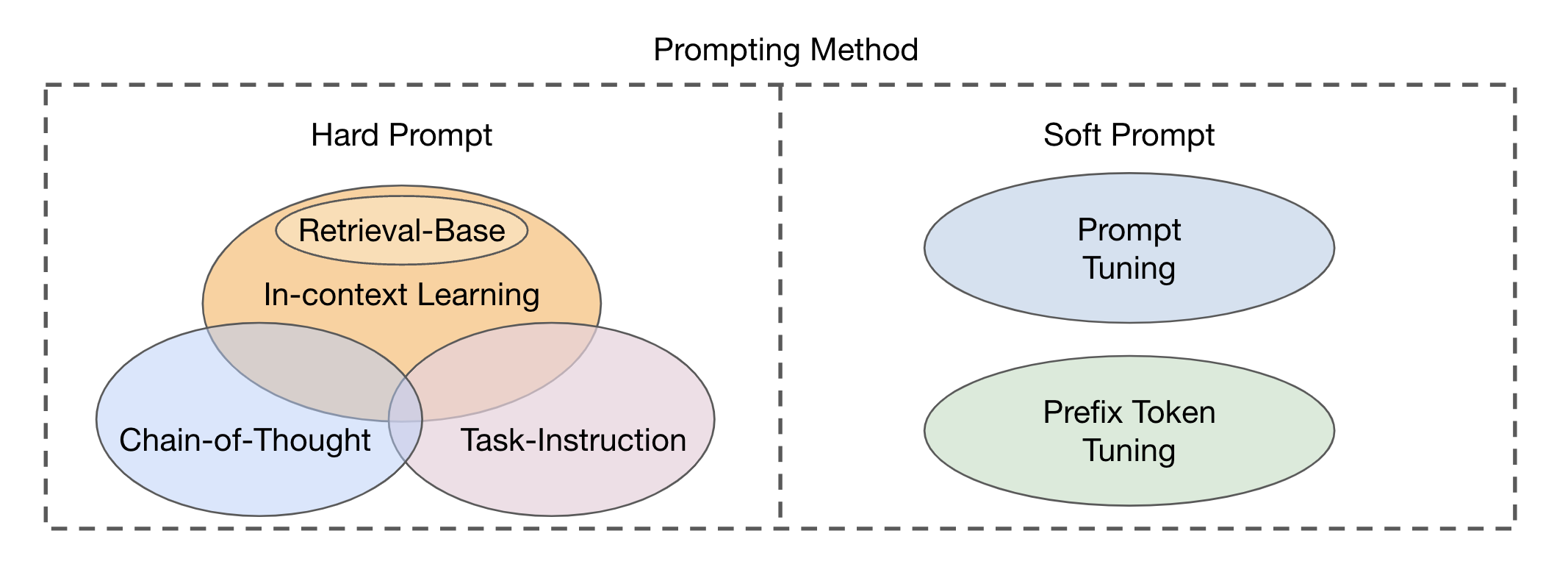
그림 2 : 프롬프트 방법의 분류.
| 제목 | 장소 | 년도 | 사용 가능한 경우 코드 | 논평 |
|---|---|---|---|---|
| 텍스트 생성을 통해 비전과 언어 작업을 통일합니다 | ICML | 2021 | github | 인코더 디코더 융합; 텍스트 접두사로 프롬프트 |
| SIMVLM : 약한 감독과 함께 간단한 시각적 언어 모델 사전 여지가 있습니다 | ICLR | 2022 | github | 인코더 디코더 융합; 텍스트 접두사로 프롬프트 |
| OFA : 간단한 시퀀스-시퀀스 학습 프레임 워크를 통한 아키텍처, 작업 및 양식 통합 | ICML | 2022 | github | 인코더 디코더 융합; 텍스트 접두사로 프롬프트 |
| PALI : 공동 스케일 된 다국어 언어 이미지 모델 | ICLR | 2023 | --- | 인코더 디코더 융합; 지시 프롬프트 |
| 냉동 언어 모델을 사용한 멀티 모달 소수의 학습 | 신경관 | 2021 | 페이지 | 디코더 전용 융합; 이미지 조건부 접두사 튜닝 |
| Flamingo : 소수의 학습을위한 시각적 언어 모델 | 신경관 | 2022 | github | 디코더 전용 융합; 텍스트 프롬프트; |
| 마그마-어댑터 기반 결승을 통한 생성 모델의 멀티 모달 보강 | emnlp | 2022 | github | 디코더 전용 융합; 이미지 조건부 접두사 튜닝 |
| Blip-2 : 냉동 이미지 인코더 및 대형 언어 모델로 언어 이미지 사전 훈련 부트 스트랩 | ICML | 2023 | github | 디코더 전용 융합; 이미지 조건부 접두사 튜닝 |
| 언어 모델은 감독되지 않은 멀티 태스킹 학습자입니다 | Openai 블로그 | 2019 | github | 작업 명령 프롬프트 |
| 터키 테스트 : 언어 모델이 지침을 이해할 수 있습니까? | arxiv | 2020 | --- | 작업 명령 프롬프트 |
| 언어 모델은 소수의 학습자입니다 | 신경관 | 2020 | --- | 텍스트 내 학습 |
| 텍스트 내 학습을위한 프롬프트를 검색하는 법 학습 | NAACL-HLT | 2022 | github | 검색 기반 프롬프트 |
| 텍스트 내 학습을위한 통합 데모 리트리버 | ACL | 2023 | github | 검색 기반 프롬프트 |
| 텍스트 내 학습을위한 구성 모범 | ICML | 2023 | github | 검색 기반 프롬프트 |
| 생각을 기울이는 체인은 큰 언어 모델에서 추론을 유도합니다 | 신경관 | 2022 | --- | 생각의 사슬 프롬프트 |
| 대형 언어 모델로 인한 자동 사고 체인 | ICLR | 2023 | github | 생각의 사슬 프롬프트 |
| 매개 변수 효율적인 프롬프트 튜닝을위한 스케일의 전력 | emnlp | 2021 | --- | 프롬프트 튜닝 |
| 묻는 방법 배우기 : 소프트 프롬프트 혼합물로 LMS 쿼리 | NAACL-HLT | 2021 | github | 프롬프트 튜닝 |
| 접두사 조정 : 세대를위한 연속 프롬프트 최적화 | ACL | 2021 | github | 접두사 튜닝 |
| 생성 멀티 모달 사전 관리 모델에 대한 프롬프트 튜닝 | ACL | 2023 | github | OFA에 대한 프롬프트 튜닝 |
| 언어가 필요한 전부는 아닙니다 : 언어 모델과의 인식을 정렬합니다. | 신경관 | 2023 | github | 텍스트 명령 프롬프트 |
| 미리 훈련 된 비전 언어 모델에서 적응 방법의 견고성을 벤치마킹합니다 | 신경관 | 2024 | 페이지 | VLM에서 신속한 튜닝의 견고성 |
| 비전 언어 모델에 대한 강력한 프롬프트를 향해 | NextGenenaisAfety@iclr | 2024 | --- | VLM에서 신속한 튜닝의 견고성 |
| InstructBlip : 명령 튜닝이있는 일반 목적 비전 언어 모델을 향해 | 신경관 | 2023 | github | 프롬프트 튜닝 |
| 시각적 지시 조정 | 신경관 | 2023 | github | |
| Qwen-VL : 이해, 현지화, 텍스트 읽기 및 그 밖의 다목적 비전 언어 모델 | arxiv | 2023 | github | 프롬프트 튜닝 |
| Shikra : Multimodal LLM의 참조 대화 매직을 방출합니다 | arxiv | 2023 | github | |
| MINIGPT-4 : 고급 대형 언어 모델로 비전 언어 이해 향상 | ICLR | 2023 | github | 프롬프트 튜닝 |
프롬프트 대상에 따라 기존 방법은 세 가지 범주로 분류 될 수 있습니다. 텍스트 인코더 프롬프트 , 시각 인코더 프롬프트 또는 그림 2에 표시된 것처럼 두 가지 모두 공동으로 프롬프트 할 수 있습니다 . 이러한 접근법은 VLM의 유연성과 작업 별 성능을 향상시키는 것을 목표로합니다.
그림 2 : 이미지 텍스트 매칭 VLM에서 프롬프트 방법의 분류.
| 제목 | 장소 | 년도 | 사용 가능한 경우 코드 | 논평 |
|---|---|---|---|---|
| 자연어 감독에서 전송 가능한 시각적 모델 학습 | ICML | 2021 | github | 어려운 텍스트 프롬프트; 이미지 분류 프롬프트 |
| 클립의 개방성을 탐구합니다 | ACL | 2023 | github | 이해하기위한 어려운 텍스트 프롬프트 |
| 비전 언어 모델에서 제로 샷 일반화에 대한 테스트 시간 프롬프트 튜닝 | 신경관 | 2022 | github | 소프트 텍스트 프롬프트 |
| 비전 언어 모델을 신속하게 배운 학습 | IJCV | 2022 | github | 소프트 텍스트 프롬프트 |
| 효율적인 비디오 이해를위한 시각적 언어 모델을 제기합니다 | ECCV | 2022 | github | 소프트 텍스트 프롬프트 |
| 멀티 태스킹 비전 언어 프롬프트 튜닝 | WACV | 2024 | github | 소프트 텍스트 프롬프트 |
| 비전 언어 모델에 대한 조건부 신속한 학습 | CVPR | 2022 | github | 소프트 텍스트 프롬프트 |
| 시각적 프롬프트 튜닝 | ECCV | 2022 | github | 시각적 패치가 현명한 프롬프트 |
| 대규모 모델을 조정하기위한 시각적 프롬프트 탐색 | arxiv | 2022 | github | 시각적 패치가 현명한 프롬프트 |
| 멀티 태스킹 비전 언어 프롬프트 튜닝 | WACV | 2024 | github | 시각적 패치가 현명한 프롬프트 |
| 픽셀 레벨에서 시각적 프롬프트의 힘을 발휘 | tmlr | 2024 | github | 시각적 패치가 현명한 프롬프트 |
| 다양성 인식 메타 비주얼 프롬프트 | CVPR | 2023 | github | 시각적 패치가 현명한 프롬프트 |
| CPT : 미리 훈련 된 비전 언어 모델을위한 다채로운 프롬프트 튜닝 | AI 열기 | 2024 | github | 시각적 주석 프롬프트 |
| 클립은 빨간 원에 대해 무엇을 알고 있습니까? VLM의 시각적 신속한 엔지니어링 | ICCV | 2023 | --- | 시각적 주석 프롬프트 |
| 이미지를 통한 시각적 프롬프트 | 신경관 | 2022 | github | 시각적 주석 프롬프트 |
| 통일 된 비전과 언어 프롬프트 학습 | arxiv | 2023 | github | 결합 된 통합 프롬프트 |
| 멀티 태스킹 비전 언어 프롬프트 튜닝 | WACV | 2024 | github | 통합 된 프롬프트 분리 |
| 메이플 : 멀티 모달 프롬프트 학습 | CVPR | 2023 | github | 통합 된 프롬프트 분리 |
| 대규모 모델에 대한 제로 샷 부적 견고성 이해 | ICLR | 2023 | 암호 | 프롬프트의 적대적 견고성 |
| 대적 견고성을위한 시각적 프롬프트 | ICASSP | 2023 | github | 프롬프트의 적대적 견고성 |
| 퓨즈 전에 정렬 : 모멘텀 증류로 비전 및 언어 표현 학습 | 신경관 | 2021 | github | 이미지 텍스트 매칭 모델 |
| 비전 언어 모델에 대한 감독되지 않은 신속한 학습 | arxiv | 2022 | github | 보복되지 않은 학습 가능한 프롬프트 |
| 비전 언어 모델에서 제로 샷 일반화에 대한 테스트 시간 프롬프트 튜닝 | 신경관 | 2022 | github | 학습 가능한 프롬프트 |
| 개방 대정 관찰을 위해 2 천명 이상의 클래스로 프롬프트 사전 훈련 | 신경관 | 2023 | github | 프롬프트 사전 훈련 |
| 비전 언어 모델에 대한 일관성 유도 신속한 학습 | ICLR | 2024 | --- | 통합 된 프롬프트 분리 |
| 비전 언어 모델에 대한 효율적인 전송 학습의 적응성 및 일반화 개선 | ACL ARR | 2024 | --- | 학습 가능한 프롬프트 |
| 제목 | 장소 | 년도 | 사용 가능한 경우 코드 | 논평 |
|---|---|---|---|---|
| LMPT : 긴 꼬리 멀티 라벨 시각적 인식을위한 클래스 별 임베딩 손실로 신속한 튜닝 | Alvr | 2024 | github | 긴 꼬리 멀티 라벨 이미지 분류에 대한 프롬프트 |
| 비전 언어 모델에서 제로 샷 일반화에 대한 테스트 시간 프롬프트 튜닝 | 신경관 | 2022 | github | 학습 가능한 프롬프트; 이미지 분류 프롬프트 |
| LPT : 이미지 분류를위한 긴 꼬리 프롬프트 튜닝 | ICLR | 2023 | github | 긴 꼬리 이미지 분류 프롬프트 |
| 멀티 라벨 이미지 인식을위한 프롬프트 튜닝의 이미지로서의 텍스트 | CVPR | 2023 | github | 다중 표지 이미지 분류 및 탐지에 대한 프롬프트 |
| DualCoop : 제한된 주석으로 다중 표지 인식에 빠르게 적응합니다 | 신경관 | 2022 | github | 멀티 레이블 이미지 분류 및 인식에 대한 프롬프트 |
| 소수의 샷 텍스트 분류를위한 시각적 프롬프트 튜닝 | ICCL | 2022 | --- | 텍스트 분류를위한 시각적 프롬프트 |
| 시력 및 언어 지식 증류를 통한 개방-사발성 물체 탐지 | ICLR | 2021 | github | 물체 감지 프롬프트 |
| 비전 언어 모델로 개방 변호사 객체 탐지를 자극하는 학습 | CVPR | 2022 | github | 물체 감지 프롬프트 |
| PromptDet : 큐 레이션되지 않은 이미지를 사용하여 개방-변조 검출을 향해 | ECCV | 2022 | github | 물체 감지 프롬프트 |
| 접미사 조정에 의한 시각적 관계 탐지를위한 연속 프롬프트 최적화 | IEEE 액세스 | 2022 | --- | 시각 관계 탐지를위한 소프트 프롬프트 |
| 프롬프트 기반 결합을 사용하여 개방-변조 장면 그래프 생성을 향해 | ECCV | 2022 | --- | 시각 관계 탐지를위한 소프트 프롬프트 |
| 개방형 대사 비디오 관계 감지를위한 모션 큐가있는 구성 프롬프트 튜닝 | ICLR | 2023 | github | 비디오 개방-사발성 관계 검출에 대한 관계 프롬프트 |
| Denseclip : 상황 인식 프롬프트를 사용한 언어 유도 밀도 예측 | CVPR | 2022 | github | 시맨틱 세분화를위한 클래스 조정 된 텍스트 프롬프트 |
| 무엇이든 분류하십시오 | ICCV | 2023 | github | 시맨틱 세분화를위한 프롬프트 가능한 쿼리 |
| 신속한 학습을 통한 도메인 적응 | IEEE | 2023 | github | 도메인 적응을위한 도메인 별 텍스트 프롬프트 |
| 테스트 시간 도메인 적응을위한 시각적 프롬프트 튜닝 | arxiv | 2022 | --- | 도메인 적응에 대한 프롬프트 |
| 지속적인 학습을 신속하게 배우는 학습 | CVPR | 2022 | github | 지속적인 학습을위한 프롬프트 |
| DualPrompt : 리허설이없는 지속적인 학습을위한 보완 프롬프트 | ECCV | 2022 | github | 지속적인 학습을위한 프롬프트 |
| 도메인 일반화를위한 프롬프트 비전 변압기 | arxiv | 2022 | github | 도메인 일반화 프롬프트 |
| 대규모 모델에 대한 제로 샷 부적 견고성 이해 | lclr | 2022 | github | 적대적 공격 하에서 시각적 프롬프트 튜닝 |
| 대적 견고성을위한 시각적 프롬프트 | ICASSP | 2023 | github | 대적 견고성을 향상시키기위한 시각적 프롬프트 |
| 프롬프트 기반 학습 패러다임의 보편적 취약성 탐색 | NaaCl | 2022 | github | 취약성을위한 시각적 프롬프트 |
| 중독 및 백도어 대조 학습 | ICLR | 2022 | --- | 클립에 대한 백도어 및 중독 공격 |
| BADENCODER : 백도어는 자체 감독 학습에서 미리 훈련 된 인코더에 대한 공격 | IEEE | 2022 | github | 클립에 대한 백도어 공격 |
| CleanClip : 다중 모드 대조 학습에서 데이터 중독 공격 완화 | ICLR 워크숍 | 2023 | --- | 클립에 대한 방어 백도어 공격 |
| 편향된 프롬프트를 통한 비전 언어 모델에 대한 토론 | arxiv | 2023 | github | 편견을 완화하라는 프롬프트 |
| 제목 | 장소 | 년도 | 사용 가능한 경우 코드 | 논평 |
|---|---|---|---|---|
| 확산 모델은 이미지 합성에서 GAN을 이기고 있습니다 | 신경관 | 2021 | github | 이미지 생성에 대한 확산 모델 |
| 확산 모델은 이미지 합성에서 GAN을 이기고 있습니다 | 신경관 | 2021 | github | 이미지 생성에 대한 확산 모델 |
| 확산 확률 모델을 비난합니다 | 신경관 | 2020 | github | 이미지 생성에 대한 확산 모델 |
| SUS-X : 비전 언어 모델의 교육이없는 이름 전용 전송 | ICCV | 2023 | github | 이미지 생성에 대한 확산 모델 |
| 확산 모델의 신속한 엔지니어링 조사 | Neurips Workshop | 2022 | --- | 시맨틱 프롬프트 디자인 |
| DIFFUMASK : 확산 모델을 사용한 시맨틱 세분화를위한 픽셀 수준 주석으로 이미지 합성 | IEEE/CVF | 2023 | github | 프롬프트로 생성을 다각화합니다. 합성 데이터 생성 프롬프트 |
| 생성 모델의 합성 데이터는 이미지 인식을 위해 준비됩니까? | ICLR | 2023 | github | 프롬프트로 생성을 다각화하십시오 |
| 이미지는 한 단어의 가치가 있습니다 : 텍스트 반전을 사용하여 텍스트-이미지 생성 개인화 | ICLR | 2023 | github | 프롬프트를 통한 합성 결과의 복잡한 제어 |
| Dreambooth : 주제 중심 생성을위한 미세 튜닝 텍스트-이미지 확산 모델 | CVPR | 2023 | github | 프롬프트를 통한 합성 결과의 복잡한 제어 |
| 텍스트-이미지 확산의 다중 개념 사용자 정의 | CVPR | 2023 | github | 프롬프트를 통한 합성 결과의 복잡한 제어 |
| 크로스주의 제어 기능을 갖춘 프롬프트 이미지 편집 | ICLR | 2023 | --- | 프롬프트를 통한 합성 결과의 복잡한 제어 |
| 조성 텍스트-이미지 합성을위한 훈련이없는 구조화 된 확산 안내 | ICLR | 2023 | github | 제어 가능한 텍스트-이미지 생성 |
| 제어 가능한 이미지 생성을위한 확산 자체 유도 | 신경관 | 2023 | 페이지 | 제어 가능한 텍스트-이미지 생성 |
| Imagic : 확산 모델을 사용한 텍스트 기반 실제 이미지 편집 | CVPR | 2023 | github | 제어 가능한 텍스트-이미지 생성 |
| 텍스트-이미지 확산 모델에 조건부 제어 추가 | IEEE/CVF | 2023 | github | 제어 가능한 텍스트-이미지 생성 |
| 크로스주의 제어 기능을 갖춘 프롬프트 이미지 편집 | ICLR | 2023 | github | 프롬프트를 통한 합성 결과의 복잡한 제어 |
| Imaginarynet : 실제 이미지와 주석이없는 객체 탐지기 학습 | ICLR | 2023 | github | 합성 데이터 생성 프롬프트 |
| 생성 모델의 합성 데이터는 이미지 인식을 위해 준비됩니까? | ICLR | 2023 | github | 합성 데이터 생성 프롬프트 |
| Make-a-Video : 텍스트-비디오 데이터가없는 텍스트-비디오 생성 | ICLR | 2023 | 페이지 | 텍스트-비디오 생성 프롬프트 |
| Imagen 비디오 : 확산 모델을 가진 고화질 비디오 생성 | arxiv | 2022 | 페이지 | 텍스트-비디오 생성 프롬프트 |
| Fatezero : 제로 샷 텍스트 기반 비디오 편집에 대한 융합 관심 | ICCV | 2023 | github | 텍스트-비디오 생성 프롬프트 |
| Tune-A-Video : 텍스트-비디오 생성을위한 이미지 확산 모델의 원샷 튜닝 | ICCV | 2023 | github | 텍스트-비디오 생성 프롬프트 |
| Diffrf : 렌더링 유도 3D 방사선 필드 확산 | CVPR | 2023 | 페이지 | 텍스트-3D 세대의 프롬프트 |
| DreamFusion : 2D 확산을 사용한 텍스트-3D | ICLR 주목할만한 상위 5% | 2023 | 페이지 | 텍스트-3D 세대의 프롬프트 |
| Dream3d : 3D 모양 이전 및 텍스트-이미지 확산 모델을 사용한 제로 샷 텍스트-3D 합성 | CVPR | 2023 | 페이지 | 텍스트-3D 세대의 프롬프트 |
| MotionDiffuse : 확산 모델을 가진 텍스트 중심의 인간 모션 생성 | IEEE | 2024 | 페이지 | 텍스트-모션 생성의 프롬프트 |
| 불꽃 : 자유 형식 언어 기반 모션 합성 및 편집 | AAAI | 2023 | github | 텍스트-모션 생성의 프롬프트 |
| MDM : 인간 운동 확산 모델 | ICLR | 2023 | github | 텍스트-모션 생성의 프롬프트 |
| 확산 모델을 사용한 평범 | arxiv | 2023 | --- | 복잡한 작업에 대한 프롬프트 |
| 듀얼 텍스트 이미지 프롬프트를 통한 멀티 모달 절차 계획 | ICLR | 2024 | github | 복잡한 작업에 대한 프롬프트 |
| 텍스트-이미지 생성 모델에 대한 훔치기 공격 | Usenix 보안 심포지엄 | 2023 | --- | 책임있는 AI의 프롬프트 |
| 텍스트-이미지 생성 모델에 대한 멤버십 추측 공격 | ICLR | 2023 | --- | 텍스트-이미지 모델에 대한 멤버십 공격 |
| 확산 모델이 멤버십 불가능한 공격에 취약합니까? | ICML | 2023 | github | 텍스트-이미지 모델에 대한 멤버십 공격 |
| 확산 모델에서 훈련 이미지의 재현 가능한 추출 | arxiv | 2023 | github | 텍스트-이미지 모델에 대한 멤버십 공격 |
| 공정한 확산 : 공정성에 대한 텍스트-이미지 생성 모델을 지시합니다 | arxiv | 2023 | github | 공정성을 고려한 텍스트-이미지 모델에 대한 프롬프트 |
| 텍스트-이미지 생성 렌즈를 통한 사회적 편견 | AAAI/ACM | 2023 | --- | 편견을 고려한 텍스트-이미지 모델에 대한 프롬프트 |
| T2IAT : 텍스트-이미지 생성에서 원자가 및 전형적인 편향 측정 | ACL | 2023 | --- | 편견을 고려한 텍스트-이미지 모델에 대한 프롬프트 |
| 안정적인 편견 : 확산 모델에서 사회적 표현 분석 | 신경관 | 2023 | --- | 편견을 고려한 텍스트-이미지 모델에 대한 프롬프트 |
| 안정적인 확산에 대한 쿼리가없는 적대적 공격에 대한 파일럿 연구 | CVPR | 2023 | --- | 텍스트-이미지 모델의 적대적 견고성 |
| 눈에 띄지 않고 전달 가능한 적대적 공격을위한 확산 모델 | ICLR | 2024 | github | 텍스트-이미지 모델의 적대적 견고성 |
| 대응 정제를위한 확산 모델 | ICML | 2022 | github | 텍스트-이미지 모델의 적대적 견고성 |
| 아티스트 인 Rickrolling : 텍스트-이미지 합성을 위해 백도어를 텍스트 인코더에 넣습니다. | ICCV | 2023 | --- | 텍스트-이미지 모델에 대한 백도어 공격 |
| 텍스트-이미지 확산 모델은 멀티 모달 데이터 중독을 통해 쉽게 백도를 뒷받침 할 수 있습니다. | ACM MM | 2023 | --- | 텍스트-이미지 모델에 대한 백도어 공격 |
| 텍스트-이미지 확산 모델에 대한 몇 가지 샷 백도어 공격을위한 바로 가기로서의 개인화 | AAAI | 2024 | --- | 텍스트-이미지 모델에 대한 백도어 공격 |
if


