Awesome Prompting on Vision Language Model
1.0.0
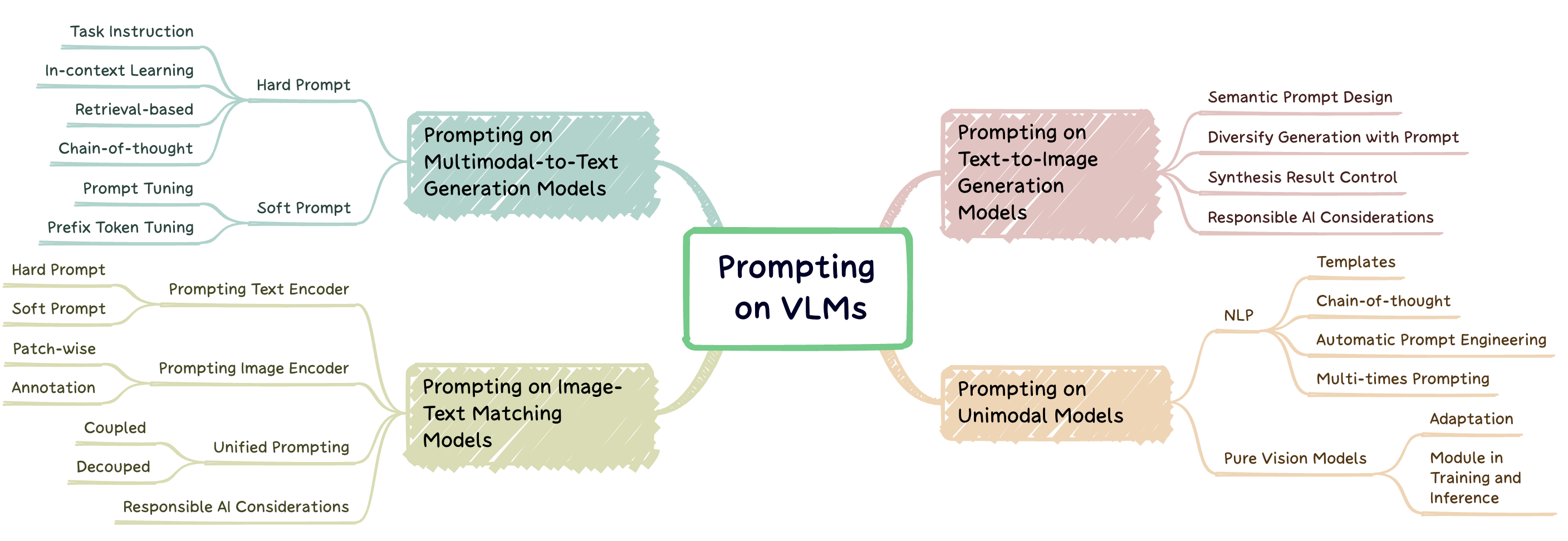
及时工程是一种技术,涉及通过使用特定于任务提示的大型预训练模型(称为提示)将模型调整为新任务。该仓库旨在对三种类型的视觉模型(VLM)进行迅速工程的尖端研究进行全面调查:多模态到文本生成模型(例如,Flamingo),图像文本匹配模型(例如,clip)和文本到图像形象的模型(例如,稳定的扩散)(例如,稳定的扩散)(图1)。
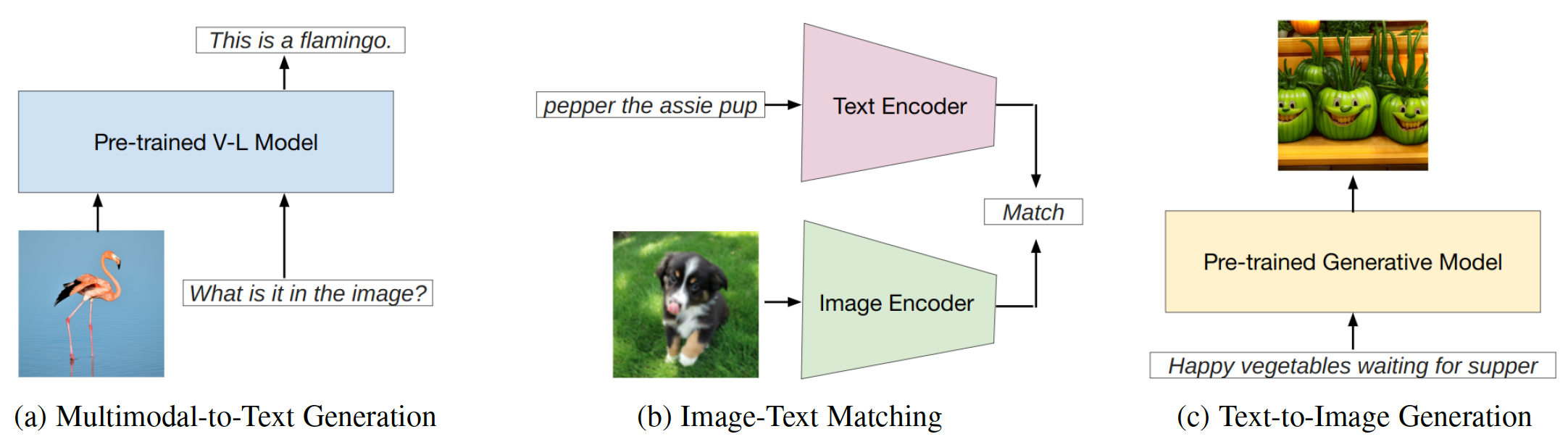
图1:这项工作集中于三种主要视觉语言模型。
该回购列出了我们调查中总结的相关论文:
对视觉基础模型的迅速工程的系统调查。 Jindong Gu,Zhen Han,Shuo Chen,Ahmad Beirami,Bailan HE,Gengyuan Zhang,Ruotong Liao,Yao Qin,Volker Tresp,Philip Torr 。预印度2023。[PDF]
如果您发现我们的论文和回购对您的研究有帮助,请引用以下论文:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}在多模式到文本生成中提示模型
在图像文本匹配中提示模型
在文本到图像中提示模型
基于视觉和文本模式的集成,有两种主要类型的融合模块方法:编码器解码器作为多模式融合模块,而仅作为多模式融合模块将其作为多模式融合模块。提示方法可以根据模板的可读性分为两个主要类别(图2):硬提示和软提示。硬提示包括四个子类别:任务指令,内在学习,基于检索的提示和经过思考链的提示。软提示分为两种策略:提示调谐和前缀令牌调整,这是根据内部内部添加新令牌的新令牌,还是只将它们添加到输入中。这项研究主要集中于避免改变基本模型的及时方法。
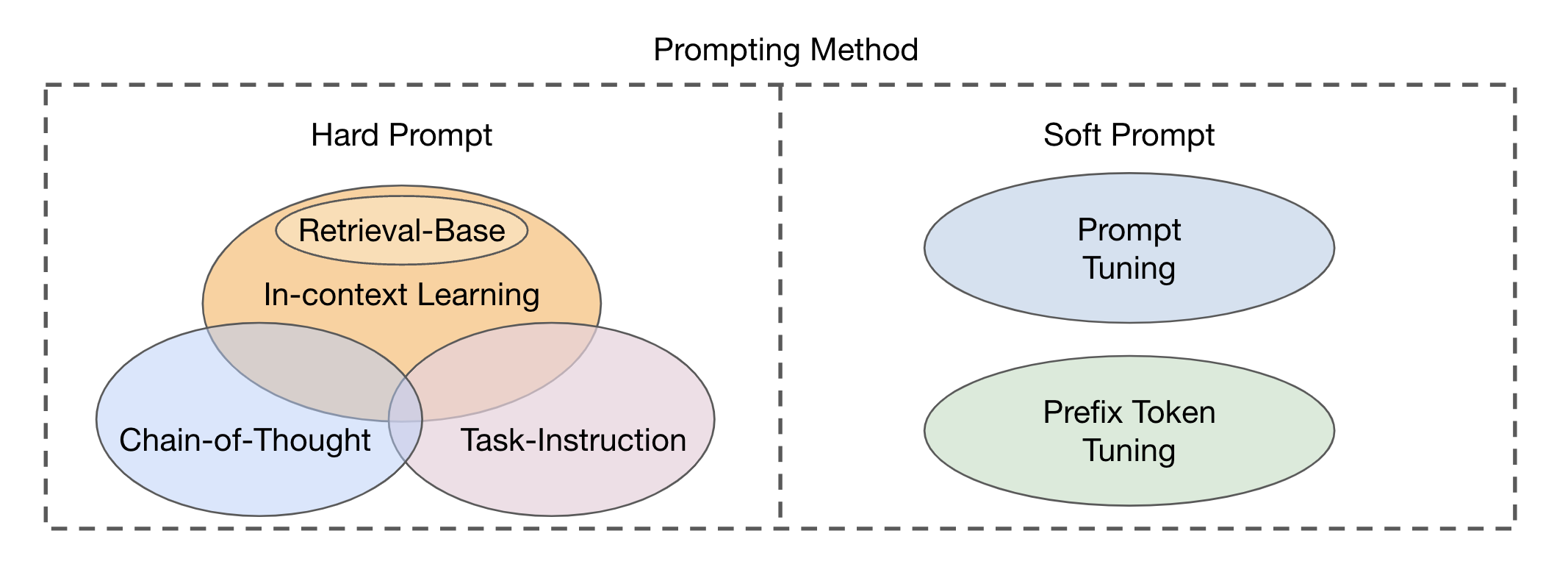
图2:提示方法的分类。
| 标题 | 场地 | 年 | 代码如果有的话 | 评论 |
|---|---|---|---|---|
| 通过文本生成统一视觉和语言任务 | ICML | 2021 | github | 编码器融合;文字前缀作为提示 |
| SIMVLM:简单的视觉语言模型,并通过弱监督进行预处理 | ICLR | 2022 | github | 编码器融合;文字前缀作为提示 |
| OFA:通过一个简单的顺序学习框架统一体系结构,任务和方式 | ICML | 2022 | github | 编码器融合;文字前缀作为提示 |
| 巴利人:一个共同刻度的多语言图像模型 | ICLR | 2023 | --- | 编码器融合;说明提示 |
| 多式联运的几次学习与冷冻语言模型 | 神经 | 2021 | 页 | 仅解码器融合;图像条件前缀调整 |
| Flamingo:一种用于几次学习的视觉语言模型 | 神经 | 2022 | github | 仅解码器融合;文本提示; |
| 岩浆 - 通过基于适配器的填充的生成模型的多模式增强 | emnlp | 2022 | github | 仅解码器融合;图像条件前缀调整 |
| BLIP-2:引导语言图像预训练,并用冷冻图像编码器和大型语言模型 | ICML | 2023 | github | 仅解码器融合;图像条件前缀调整 |
| 语言模型是无监督的多任务学习者 | Openai博客 | 2019 | github | 任务说明提示 |
| 土耳其测试:语言模型可以理解说明吗? | arxiv | 2020 | --- | 任务说明提示 |
| 语言模型是很少的学习者 | 神经 | 2020 | --- | 在文化学习中 |
| 学会检索提示中的内在学习 | naacl-hlt | 2022 | github | 基于检索的提示 |
| 统一的演示检索器用于内在学习 | ACL | 2023 | github | 基于检索的提示 |
| 秘密学习的组成示例 | ICML | 2023 | github | 基于检索的提示 |
| 经过思考的链条提示在大语言模型中引起推理 | 神经 | 2022 | --- | 经过思考链的提示 |
| 自动思想链在大型语言模型中提示 | ICLR | 2023 | github | 经过思考链的提示 |
| 参数有效提示调整的比例功能 | emnlp | 2021 | --- | 及时调整 |
| 学习如何提出:用软提示的混合物查询LMS | naacl-hlt | 2021 | github | 及时调整 |
| 前缀调整:优化发电的连续提示 | ACL | 2021 | github | 前缀调整 |
| 及时调整生成多模式预审预周座模型 | ACL | 2023 | github | 及时调整OFA |
| 语言不是您所需要的:将感知与语言模型保持一致 | 神经 | 2023 | github | 文本说明提示 |
| 在预训练的视力语言模型上对适应方法的鲁棒性进行基准测试 | 神经 | 2024 | 页 | 迅速调整VLM的鲁棒性 |
| 朝着视觉模型的强大提示 | NextGenaisafety@iclr | 2024 | --- | 迅速调整VLM的鲁棒性 |
| 指示灯:使用指令调整的通用视觉语言模型 | 神经 | 2023 | github | 及时调整 |
| 视觉说明调整 | 神经 | 2023 | github | |
| QWEN-VL:用于理解,本地化,文本阅读以及以下的多功能视觉语言模型 | arxiv | 2023 | github | 及时调整 |
| Shikra:释放多模式LLM的参考对话魔术 | arxiv | 2023 | github | |
| Minigpt-4:通过高级大语言模型增强视力语言理解 | ICLR | 2023 | github | 及时调整 |
根据提示的目标,可以将现有方法分为三类:提示文本编码,提示视觉编码器或共同提示两个分支,如图2所示。这些方法旨在增强VLM的灵活性和特定于任务的性能。
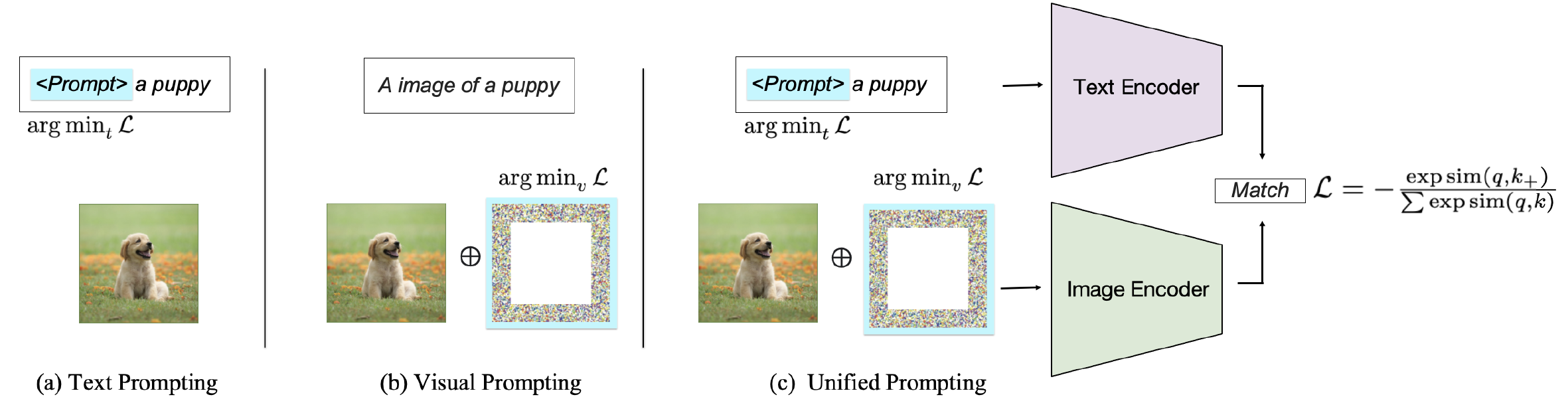
图2:图像文本匹配VLMS上提示方法的分类。
| 标题 | 场地 | 年 | 代码如果有的话 | 评论 |
|---|---|---|---|---|
| 从自然语言监督中学习可转移的视觉模型 | ICML | 2021 | github | 硬文字提示;提示图像分类 |
| 深入研究剪辑的开放性 | ACL | 2023 | github | 硬文字提示理解 |
| 测试时间及时调整视觉模型中的零弹性概括 | 神经 | 2022 | github | 软文本提示 |
| 学会提示视觉模型 | IJCV | 2022 | github | 软文本提示 |
| 促使视觉语言模型以有效的视频理解 | ECCV | 2022 | github | 软文本提示 |
| 多任务视觉语言提示调谐 | WACV | 2024 | github | 软文本提示 |
| 有条件地学习视觉模型 | CVPR | 2022 | github | 软文本提示 |
| 视觉提示调整 | ECCV | 2022 | github | 视觉贴片提示 |
| 探索视觉提示以适应大型模型 | arxiv | 2022 | github | 视觉贴片提示 |
| 多任务视觉语言提示调谐 | WACV | 2024 | github | 视觉贴片提示 |
| 释放在像素级别的视觉提示的力量 | TMLR | 2024 | github | 视觉贴片提示 |
| 多样性感知的元视觉提示 | CVPR | 2023 | github | 视觉贴片提示 |
| CPT:为预训练的视力语言模型进行色彩及时调整 | AI开放 | 2024 | github | 视觉注释提示 |
| 剪辑对红色圆圈有什么了解? VLM的视觉及时工程 | ICCV | 2023 | --- | 视觉注释提示 |
| 视觉提示通过图像介入 | 神经 | 2022 | github | 视觉注释提示 |
| 统一的视觉和语言及时学习 | arxiv | 2023 | github | 耦合统一提示 |
| 多任务视觉语言提示调谐 | WACV | 2024 | github | 解耦统一提示 |
| 枫树:多模式提示学习 | CVPR | 2023 | github | 解耦统一提示 |
| 了解大型型号的零拍对对抗性鲁棒性 | ICLR | 2023 | 代码 | 迅速的对抗性鲁棒性 |
| 视觉提示对抗性鲁棒性 | ICASSP | 2023 | github | 迅速的对抗性鲁棒性 |
| 保险丝前对齐:视觉和语言表示学习动量蒸馏 | 神经 | 2021 | github | 图像文本匹配模型 |
| 无监督的及时学习视觉模型 | arxiv | 2022 | github | 无治的可学习提示 |
| 测试时间及时调整视觉模型中的零弹性概括 | 神经 | 2022 | github | 可学习的提示 |
| 及时进行预训练,以超过2万个班级进行开放式视觉识别 | 神经 | 2023 | github | 提示预训练 |
| 一致性引导的及时学习视觉模型 | ICLR | 2024 | --- | 解耦统一提示 |
| 改善视觉模型的有效传输学习的适应性和概括性 | ACL arr | 2024 | --- | 可学习的提示 |
| 标题 | 场地 | 年 | 代码如果有的话 | 评论 |
|---|---|---|---|---|
| LMPT:及时调整长尾部多标签视觉识别的特定班级嵌入损失 | Alvr | 2024 | github | 提示长尾多标签图像分类 |
| 测试时间及时调整视觉模型中的零弹性概括 | 神经 | 2022 | github | 可学习的提示;图像分类提示 |
| LPT:长尾及时调整图像分类 | ICLR | 2023 | github | 提示长尾图像分类 |
| 文本作为图像,以迅速调整多标签图像识别 | CVPR | 2023 | github | 提示多标签图像分类和检测 |
| DualCoop:快速适应多标签识别,注释有限 | 神经 | 2022 | github | 多标签图像分类和识别提示 |
| 视觉提示调整几次播种文本分类 | ICCL | 2022 | --- | 视觉提示文本分类 |
| 通过视觉和语言知识蒸馏的开放式摄制对象检测 | ICLR | 2021 | github | 提示对象检测 |
| 学会通过视觉语言模型提示开放式视频对象检测 | CVPR | 2022 | github | 提示对象检测 |
| 提示:使用未经切割的图像朝开放式摄取检测 | ECCV | 2022 | github | 提示对象检测 |
| 通过调节来优化连续的提示以进行视觉关系检测 | IEEE访问 | 2022 | --- | 软提示以进行视觉关系检测 |
| 朝着开放式视频范围场景图生成及时基于基于迅速的登录 | ECCV | 2022 | --- | 软提示以进行视觉关系检测 |
| 用运动提示进行构图提示调整开放式视频关系检测 | ICLR | 2023 | github | 关系提示进行视频开放式摄影关系检测 |
| DENSECLIP:语言引导密集的预测,并引起上下文感知 | CVPR | 2022 | github | 班级条件的文本提示,用于语义细分 |
| 细分任何东西 | ICCV | 2023 | github | 迅速的语义细分查询 |
| 通过及时学习适应域 | IEEE | 2023 | github | 特定领域的文本提示域适应 |
| 视觉提示调整测试时间域的适应 | arxiv | 2022 | --- | 提示域适应 |
| 学习提示持续学习 | CVPR | 2022 | github | 提示持续学习 |
| 双提示:互补提示无彩排的持续学习 | ECCV | 2022 | github | 提示持续学习 |
| 迅速的视力变压器用于域概括 | arxiv | 2022 | github | 提示域概括 |
| 了解大型型号的零拍对对抗性鲁棒性 | lclr | 2022 | github | 在对抗攻击下进行视觉及时调节 |
| 视觉提示对抗性鲁棒性 | ICASSP | 2023 | github | 视觉提示提高对抗性鲁棒性 |
| 探索基于迅速的学习范式的普遍脆弱性 | Naacl | 2022 | github | 视觉提示漏洞 |
| 中毒和后门对比度学习 | ICLR | 2022 | --- | 剪辑上的后门和中毒攻击 |
| BadEncoder:在自学学习中对预训练的编码者进行的后门攻击 | IEEE | 2022 | github | 剪辑的后门攻击 |
| CleanClip:减轻多模式对比学习中的数据中毒攻击 | ICLR研讨会 | 2023 | --- | 防御后门攻击剪辑 |
| 通过有偏见的提示来使视觉语言模型 | arxiv | 2023 | github | 提示减轻偏见 |
| 标题 | 场地 | 年 | 代码如果有的话 | 评论 |
|---|---|---|---|---|
| 扩散模型击败图像合成上的gan | 神经 | 2021 | github | 图像生成的扩散模型 |
| 扩散模型击败图像合成上的gan | 神经 | 2021 | github | 图像生成的扩散模型 |
| 剥离扩散概率模型 | 神经 | 2020 | github | 图像生成的扩散模型 |
| SUS-X:视觉模型的仅训练的仅训练名称转移 | ICCV | 2023 | github | 图像生成的扩散模型 |
| 在扩散模型中调查及时工程 | 神经研讨会 | 2022 | --- | 语义提示设计 |
| Diffumask:使用像素级注释合成图像,使用扩散模型进行语义分割 | IEEE/CVF | 2023 | github | 迅速多样化;提示合成数据生成 |
| 来自生成模型的合成数据是否准备好用于图像识别? | ICLR | 2023 | github | 迅速多样化 |
| 图像值得一个词:使用文本反演个性化文本到图像生成 | ICLR | 2023 | github | 通过提示对合成结果的复杂控制 |
| Dreambooth:主题驱动一代的微调文本到图像扩散模型 | CVPR | 2023 | github | 通过提示对合成结果的复杂控制 |
| 文本对图像扩散的多概念自定义 | CVPR | 2023 | github | 通过提示对合成结果的复杂控制 |
| 迅速使用交叉注意控制的图像编辑 | ICLR | 2023 | --- | 通过提示对合成结果的复杂控制 |
| 构成文本对图像合成的无训练结构扩散指南 | ICLR | 2023 | github | 可控制的文本对图像生成 |
| 可控图像生成的扩散自我构想 | 神经 | 2023 | 页 | 可控制的文本对图像生成 |
| 图像:基于文本的真实图像编辑,具有扩散模型 | CVPR | 2023 | github | 可控制的文本对图像生成 |
| 将条件控制添加到文本到图像扩散模型 | IEEE/CVF | 2023 | github | 可控制的文本对图像生成 |
| 迅速使用交叉注意控制的图像编辑 | ICLR | 2023 | github | 通过提示对合成结果的复杂控制 |
| 假想网络:学习对象探测器没有真实图像和注释 | ICLR | 2023 | github | 提示合成数据生成 |
| 来自生成模型的合成数据是否准备好用于图像识别? | ICLR | 2023 | github | 提示合成数据生成 |
| Make-A-Video:没有文本视频数据的文本到视频生成 | ICLR | 2023 | 页 | 提示文本到视频生成 |
| 影像视频:带扩散模型的高清视频生成 | arxiv | 2022 | 页 | 提示文本到视频生成 |
| FATEZERO:基于文本的视频编辑的零拍摄的关注 | ICCV | 2023 | github | 提示文本到视频生成 |
| Tune-a-video:文本到视频生成的图像扩散模型的一声调整 | ICCV | 2023 | github | 提示文本到视频生成 |
| 差异:渲染引导的3D辐射场扩散 | CVPR | 2023 | 页 | 提示文本到3D代 |
| DreamFusion:使用2D扩散的文本到3D | ICLR值得注意的前5% | 2023 | 页 | 提示文本到3D代 |
| dream3d:零击文本到3D合成3D形状的先验和文本形象扩散模型 | CVPR | 2023 | 页 | 提示文本到3D代 |
| MotionDiffuse:通过扩散模型的文本驱动人类运动产生 | IEEE | 2024 | 页 | 提示文本到动作生成 |
| 火焰:基于语言的自由形式的运动综合和编辑 | AAAI | 2023 | github | 提示文本到动作生成 |
| MDM:人类运动扩散模型 | ICLR | 2023 | github | 提示文本到动作生成 |
| 使用扩散模型从纯文本故事出发的零发镜头 | arxiv | 2023 | --- | 提示复杂的任务 |
| 通过双文本图像提示,多模式的程序计划 | ICLR | 2024 | github | 提示复杂的任务 |
| 及时窃取针对文本到图像生成模型的攻击 | USENIX安全研讨会 | 2023 | --- | 提示负责人AI |
| 对文本到图像生成模型的会员推断攻击 | ICLR | 2023 | --- | 对文本图模型的会员攻击 |
| 扩散模型是否容易受到会员推理攻击? | ICML | 2023 | github | 对文本图模型的会员攻击 |
| 从扩散模型中可再现的训练图像 | arxiv | 2023 | github | 对文本图模型的会员攻击 |
| 公平扩散:指导公平的文本到图像生成模型 | arxiv | 2023 | github | 考虑公平的文本到图像模型的提示 |
| 通过文本到图像一代镜头的社会偏见 | AAAI/ACM | 2023 | --- | 考虑偏见的文本到图像模型的提示 |
| T2IAT:在文本到图像生成中测量价和刻板印象的偏见 | ACL | 2023 | --- | 考虑偏见的文本到图像模型的提示 |
| 稳定偏见:分析扩散模型中的社会表示 | 神经 | 2023 | --- | 考虑偏见的文本到图像模型的提示 |
| 一项针对稳定扩散的无查询对抗攻击的试点研究 | CVPR | 2023 | --- | 文本对图像模型的对抗性鲁棒性 |
| 无法察觉和可转移的对抗性攻击的扩散模型 | ICLR | 2024 | github | 文本对图像模型的对抗性鲁棒性 |
| 对抗纯化的扩散模型 | ICML | 2022 | github | 文本对图像模型的对抗性鲁棒性 |
| 将艺术家摇滚:将后门注入文本编码器中的文本对图像综合 | ICCV | 2023 | --- | 对文本对图像模型的后门攻击 |
| 文本到图像扩散模型可以通过多模式数据中毒很容易地归还 | ACM mm | 2023 | --- | 对文本对图像模型的后门攻击 |
| 个性化作为对文本对图像扩散模型的几次后门攻击的快捷方式 | AAAI | 2024 | --- | 对文本对图像模型的后门攻击 |
请联系我们([email protected],[email protected])


